ワークベンチの5つのステップ¶
DataRobotでのモデルの構築は、データ処理、モデリングオプション、予測方法、デプロイアクションを問わず、同じ5つの基本的なアクションに集約されます。 以下のステップを参照することで、DataRobotを使いこなす方法をすばやく理解できます。
学習リソース
効率化された反復的なワークフロープロセスについては、 ワークベンチの基礎で説明します。
テスト用のデータセット¶
以下の再入院デモデータセットを使用して、DataRobot機能を試すことができます:
トレーニングデータをダウンロード スコアリングコードをダウンロードする
これらのサンプルデータセットは、70,000人の糖尿病患者の再入院を研究するために、 BioMed Research Internationalによって提供されています。 この調査の研究者は、Cerner社が提供するHealth Factsデータベース(米国医療提供者全体の臨床記録)からこのデータを収集しています。 Cerner社の電子医療システムを利用している組織は、研究目的でHealth Factsのデータを無償で利用できます。 すべてのデータは、HIPAAに従ってPIIが消去されています。
1:ユースケースの作成¶
ワークベンチのディレクトリから、右上のユースケースを作成をクリックします。
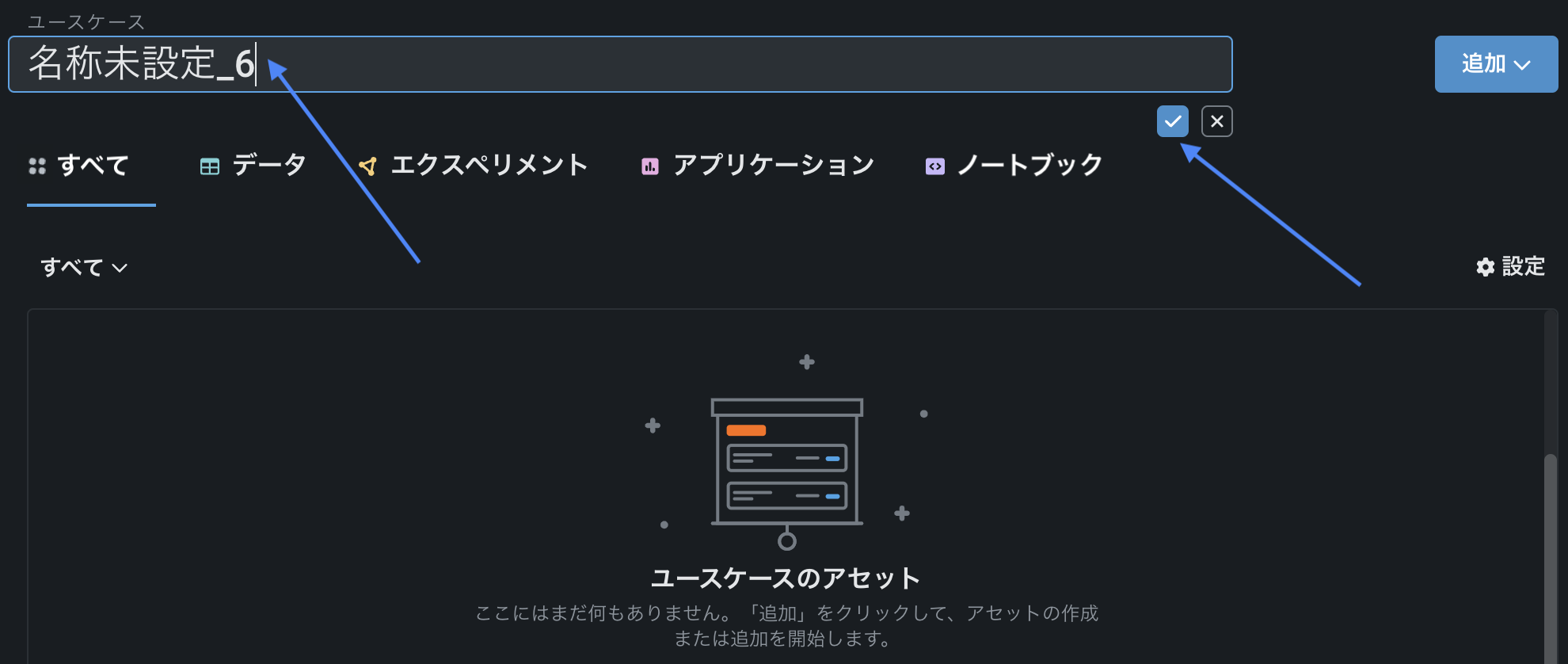
ユースケースの名前を入力し、チェックマークをクリックして承認します。 この名前は、ユースケースを開き、既存の名前をクリックすることで、いつでも変更できます。
2:データの操作¶
データの操作では、データのインポート(または接続)、探索、および準備を行います。 この3つのステップで、データはモデリングの準備が整います。
ローカルファイル、データレジストリ、またはデータ接続を使用して、ユースケースにデータを追加します。
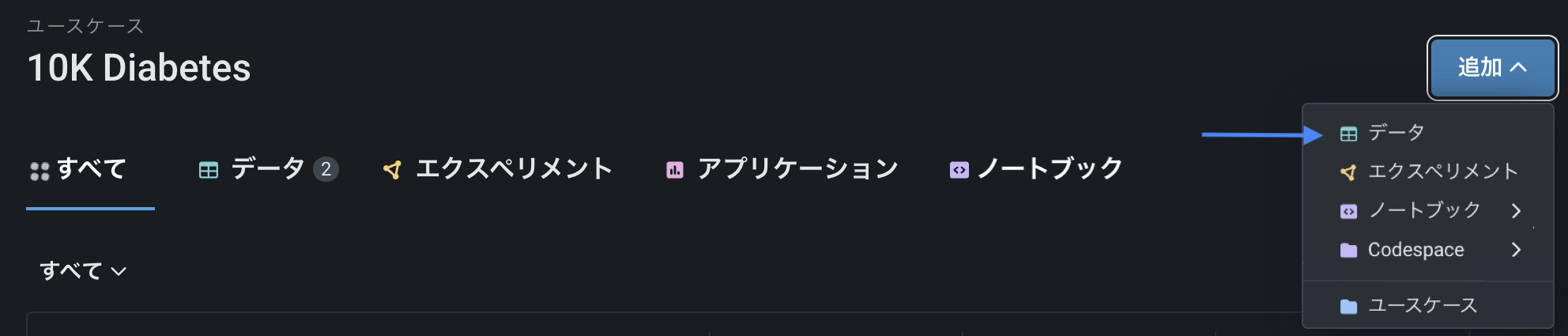
データ接続は、データの移動を最小限に抑えるだけでなく、DataRobotの統合データプレパレーション機能によって、データの参照、プレビュー、プロファイリング、準備をインタラクティブに行うことができます。
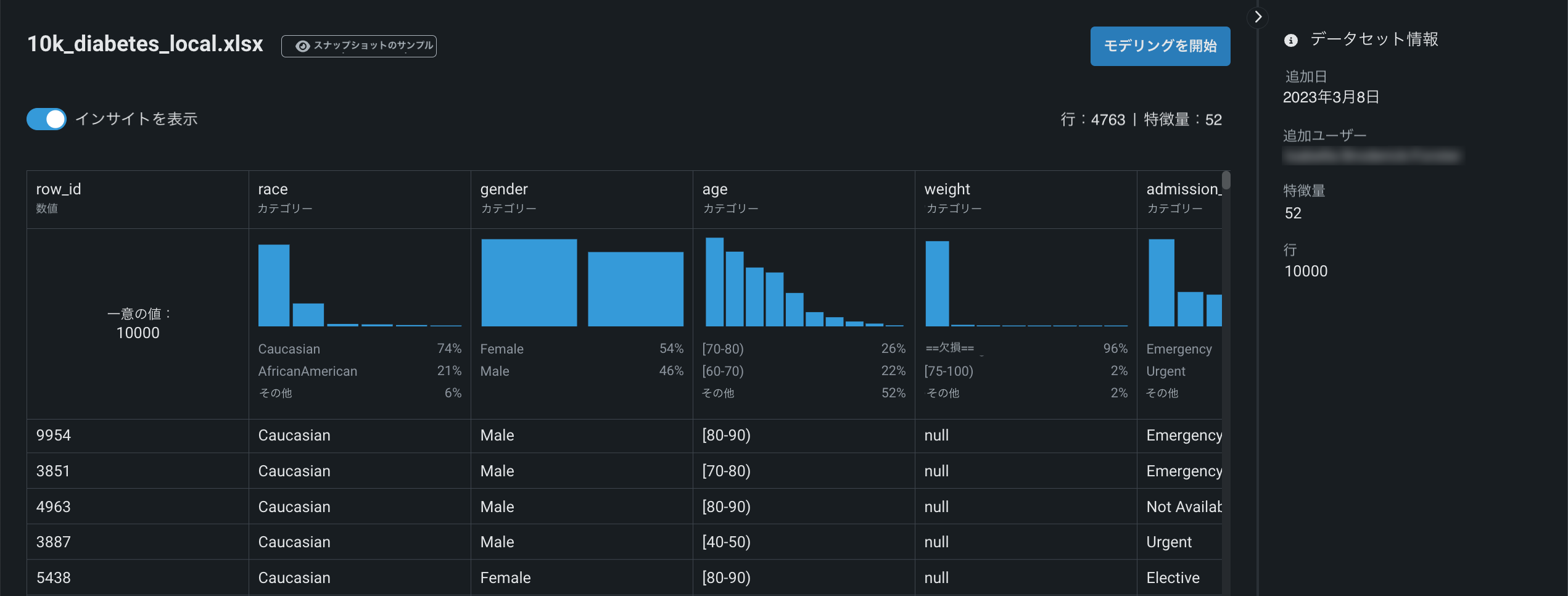
データセットがワークベンチに登録されている間、DataRobotはEDA1も実行します。つまり、すべての特徴量を分析およびプロファイリングして特徴量型を検出し、日付型特徴量の自動変換を行って、特徴量の品質を評価します。 登録が完了したら、EDA1の計算中に見つかった情報を探索することができます。
からデータを追加した場合、DataRobotのラングリング機能を使用できます。この機能により、シームレスでスケーラブルかつ安全な方法でモデリングのためのデータにアクセスし、変換することができます。 ワークベンチでは、「ラングリング」はソースでデータクリーニングを実行し、データソースの計算環境と分散アーキテクチャを活用するための視覚的なインターフェイスです。
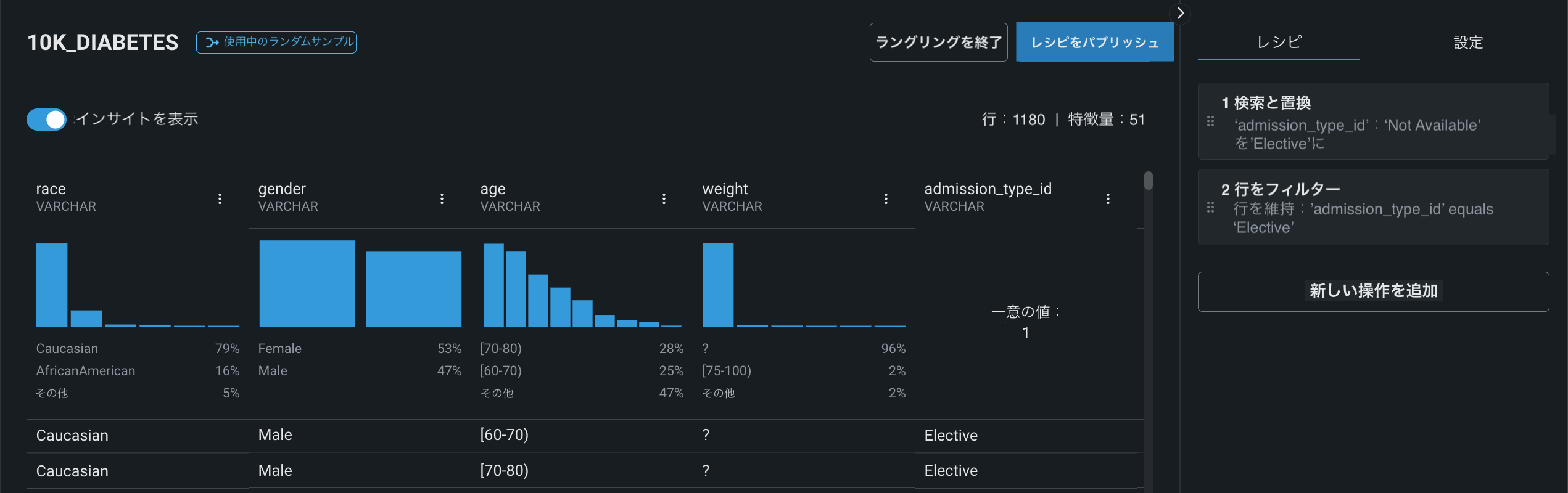
データセットのラングリングが完了したら、変換をデータソースに「プッシュダウン」して、新しい出力データセットを生成できます。
3:エクスペリメントの構築¶
ユースケース内で、追加したデータを使用してエクスペリメントを構築し、モデリングを開始します。 ワークベンチの各エクスペリメントは、ビジネス上の問題を解決する最適なモデルを見つけるために比較できるパラメーター(データ、ターゲット、モデリングの設定)のセットです。 最初に新しいエクスペリメントを追加します。
次に、ユースケースにロードしたばかりのデータセットを選択して、新しいエクスペリメントにデータを追加します。
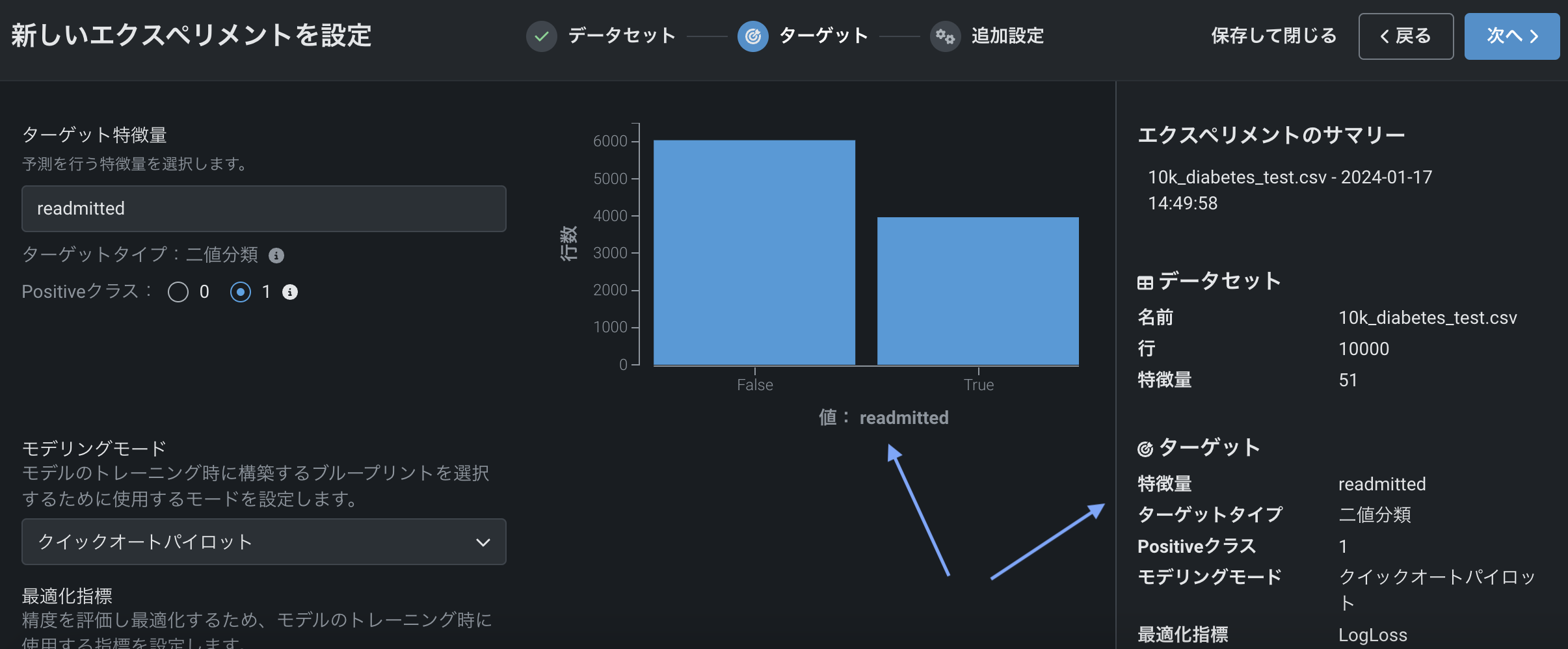
ターゲットを選択してモデリングを開始します。
4:モデルを評価¶
DataRobotのリーダーボードでは、エクスペリメント用に構築されたすべてのモデルがパフォーマンス順にランキング表示されるので、迅速なモデル評価に役立ちます。
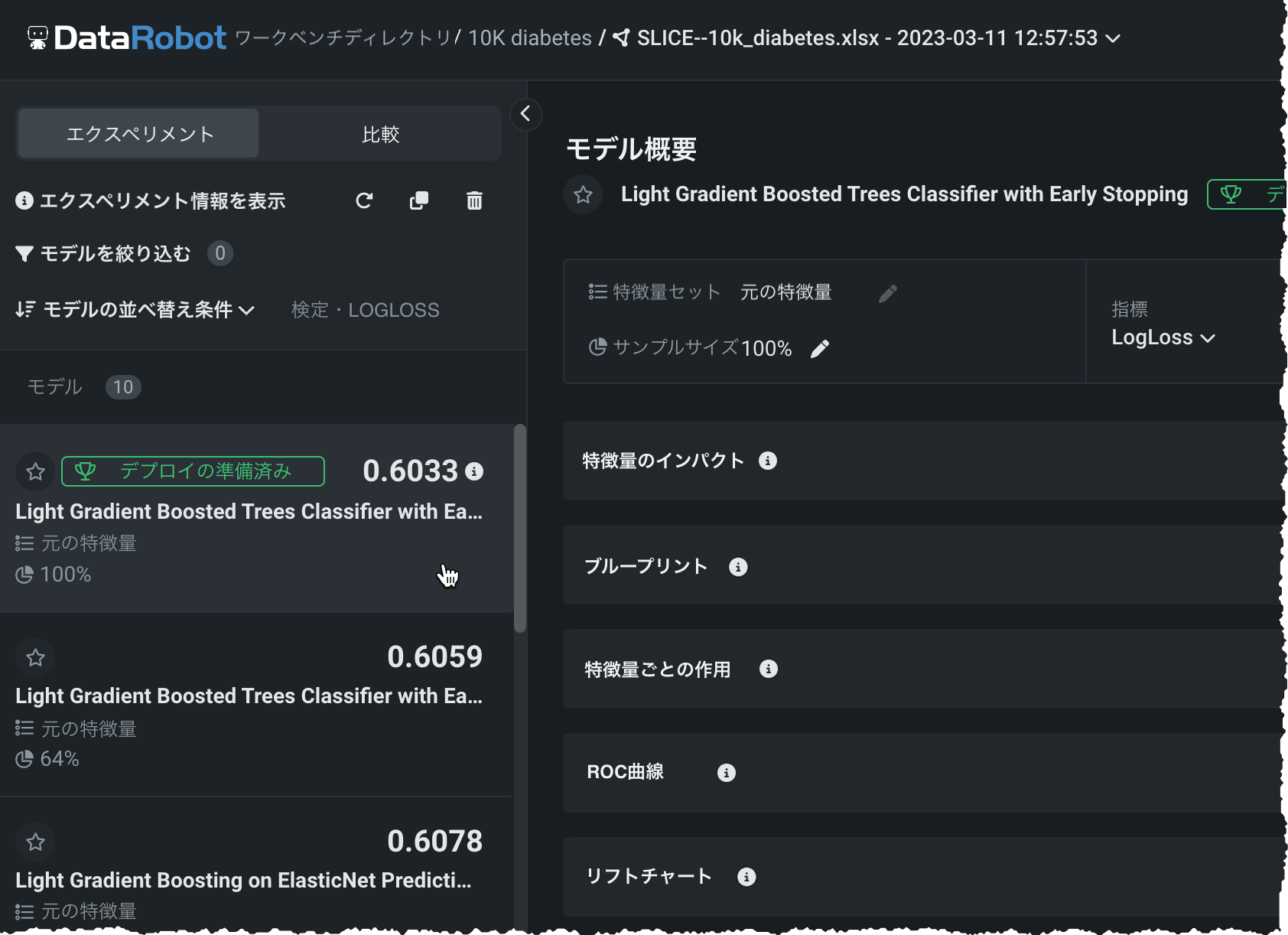
リーダーボードから、新しい特徴量セットを作成したり、モデルをクリックしてビジュアライゼーションにアクセスし、さらに探索したりすることができます。 これらのツールは、モデルの予測の根拠となるものを解釈、説明、検証し、次のエクスペリメントで何をすべきかを示すのに役立ちます。
リーダーボードから コンプライアンスドキュメントを生成することもできます。
5:予測の作成¶
モデルを選択したら、そのモデルを使って予測を行い、デプロイ前にモデルのパフォーマンスを評価することができます。 リーダーボードからモデルを選択して、モデルのアクション > 予測を作成をクリックします。

予測を作成ページで、予測ソースをアップロードします。
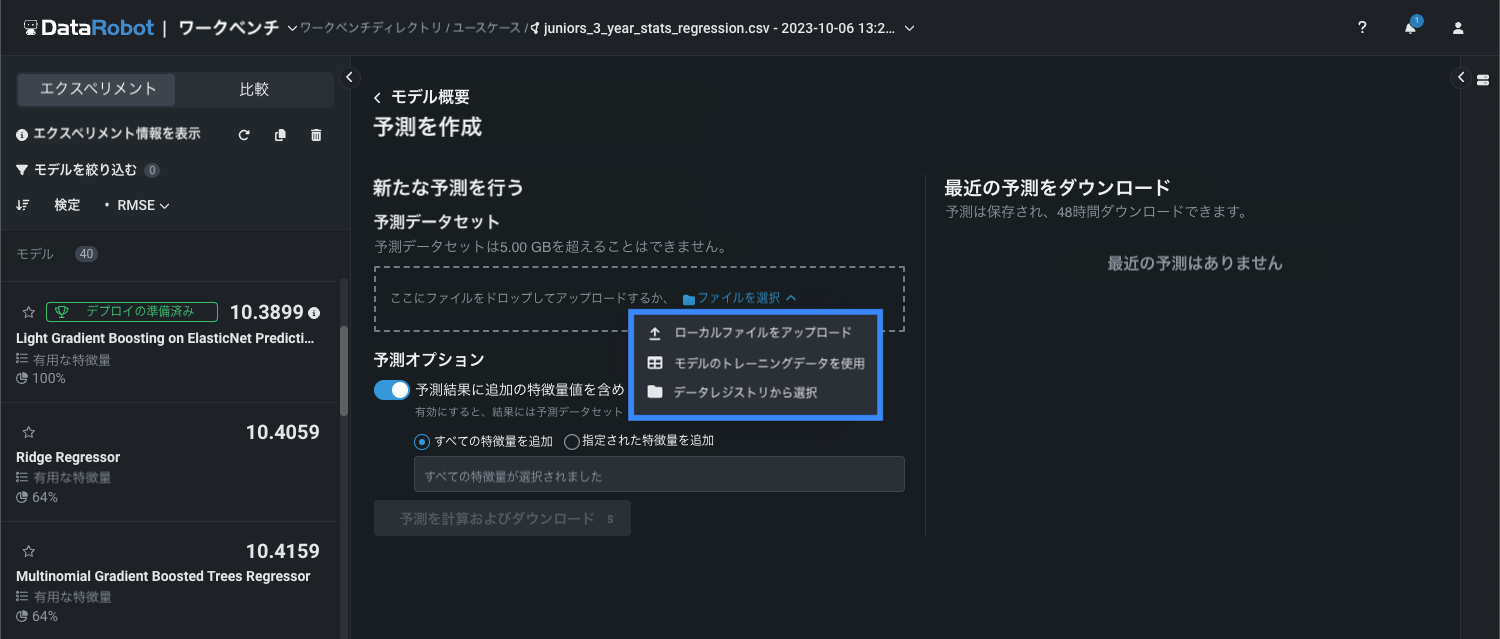
予測ソースをアップロードした後、 予測オプションを設定して予測を計算できます。
次のステップ¶
モデルを構築し、予測を行って精度をテストしたら、モデルを登録し、最終的にデプロイします。
ここから、次のこともできます。