Import data from AWS S3¶
This section shows how to ingest data from an Amazon Web Services S3 bucket into the DataRobot AI Catalog so that you can use it for ML modeling.
To build an ML model based on an object saved in an S3 bucket:
-
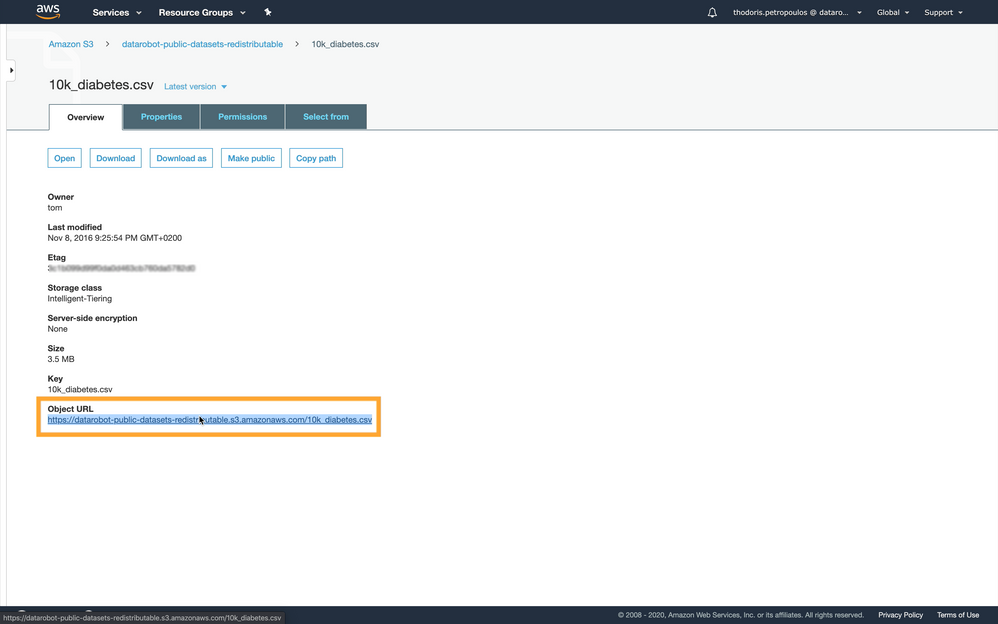
Navigate to the dataset object in AWS S3 and copy the object’s URL.
-
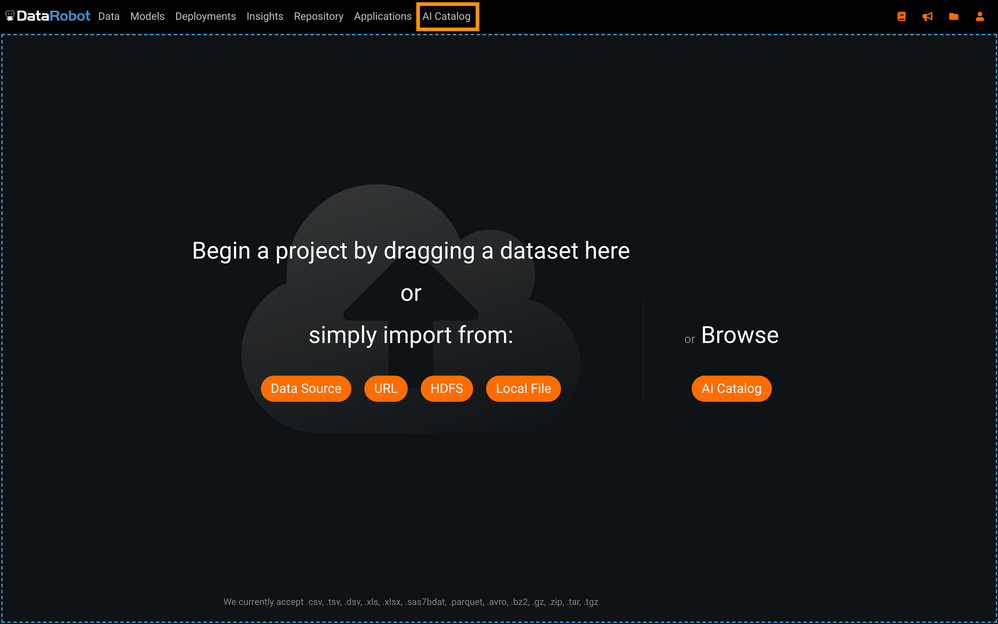
Select the AI Catalog tab in DataRobot.
-
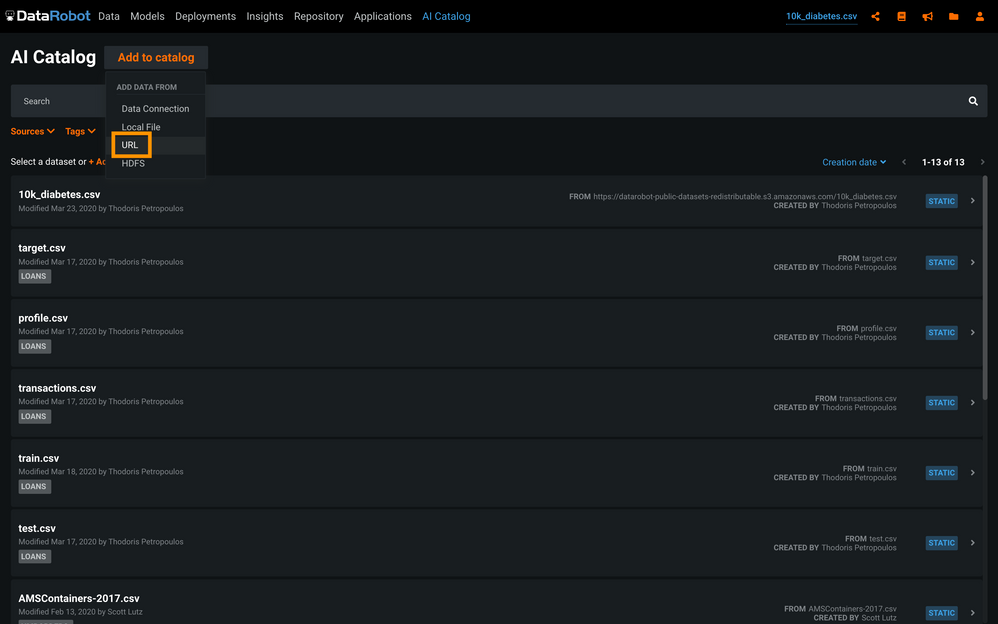
Click Add to catalog and select URL.
-
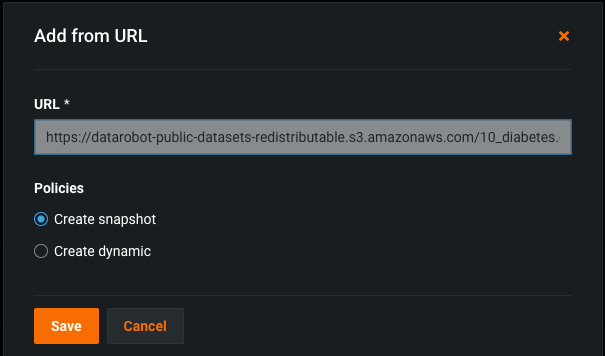
In the Add from URL window, paste the URL of the object and click Save.
DataRobot automatically reads the data and infers data types and the schema of the data, as it does when you upload a CSV file from your local machine.
-
Now that your data has been successfully uploaded, click Create project in the upper right corner to start an ML project.
Private S3 buckets¶
You can also ingest data into DataRobot from private S3 buckets. For example, you can create a temporary link from a pre-signed S3 URL that DataRobot can then use to retrieve the file.
A straightforward way to accomplish this is by using the AWS Command Line Interface (CLI).
After you install and configure the CLI, use a command like the following:
aws s3 presign --expires-in 600 s3://bucket-name/path/to/file.csv
https://bucket-name.s3.amazonaws.com/path/to/file.csv?AWSAccessKeyId=<key>
The URL produced in this example allows whoever has it to read the private file, file.csv, from the private bucket, bucket-name. The expires-in parameter makes the signed link available for 600 seconds upon creation.
If you have your own DataRobot installation, you can also:
- Provide the application's DataRobot service account with IAM privileges to read private S3 buckets. DataRobot can then ingest from any S3 location that it has privileges to access.
- Implement S3 impersonation of the user logging in to DataRobot to limit access to S3 data. This requires LDAP for authentication, with authorized roles for the user specified within LDAP attributes.
Both of these options accept an s3:// URI path.