Generative AI with NeMo Guardrails on NVIDIA GPUs¶
Availability information
The NVIDIA and NeMo Guardrails integrations are premium features. Contact your DataRobot representative or administrator for information on enabling them.
Use NVIDIA with DataRobot to quickly build out end-to-end generative AI (GenAI) capabilities by unlocking accelerated performance and leveraging the very best of open-source models and guardrails. The DataRobot integration with NVIDIA creates an inference software stack that provides full, end-to-end Generative AI capability, ensuring performance, governance, and safety through significant functionality out-of-the-box.
Create a GenAI model on NVIDIA resources¶
In the Registry, you can access the version history of your DataRobot, custom, and external models, including guard models for prompt injection monitoring, sentiment and toxicity classification, PII detection, and more.
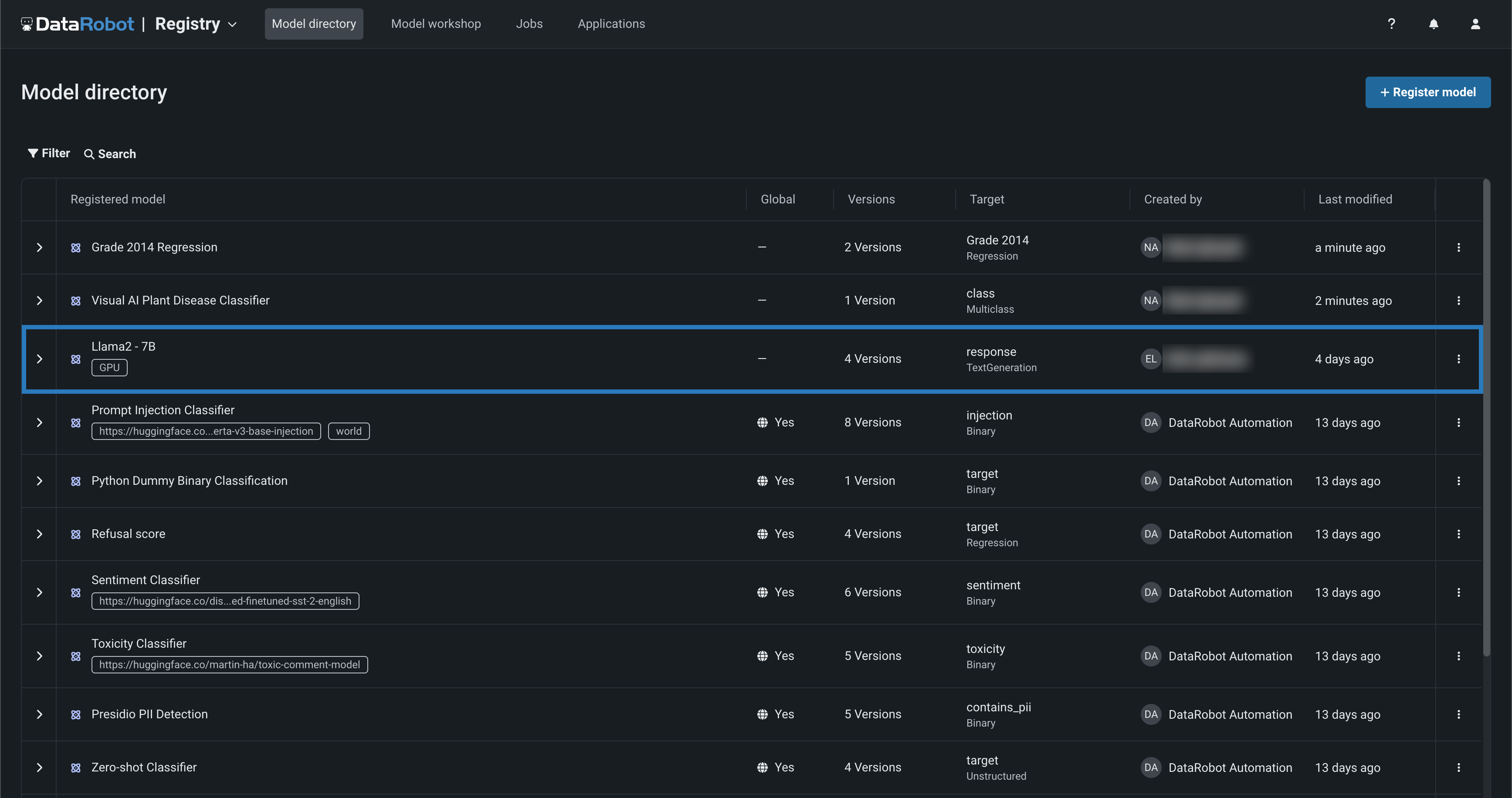
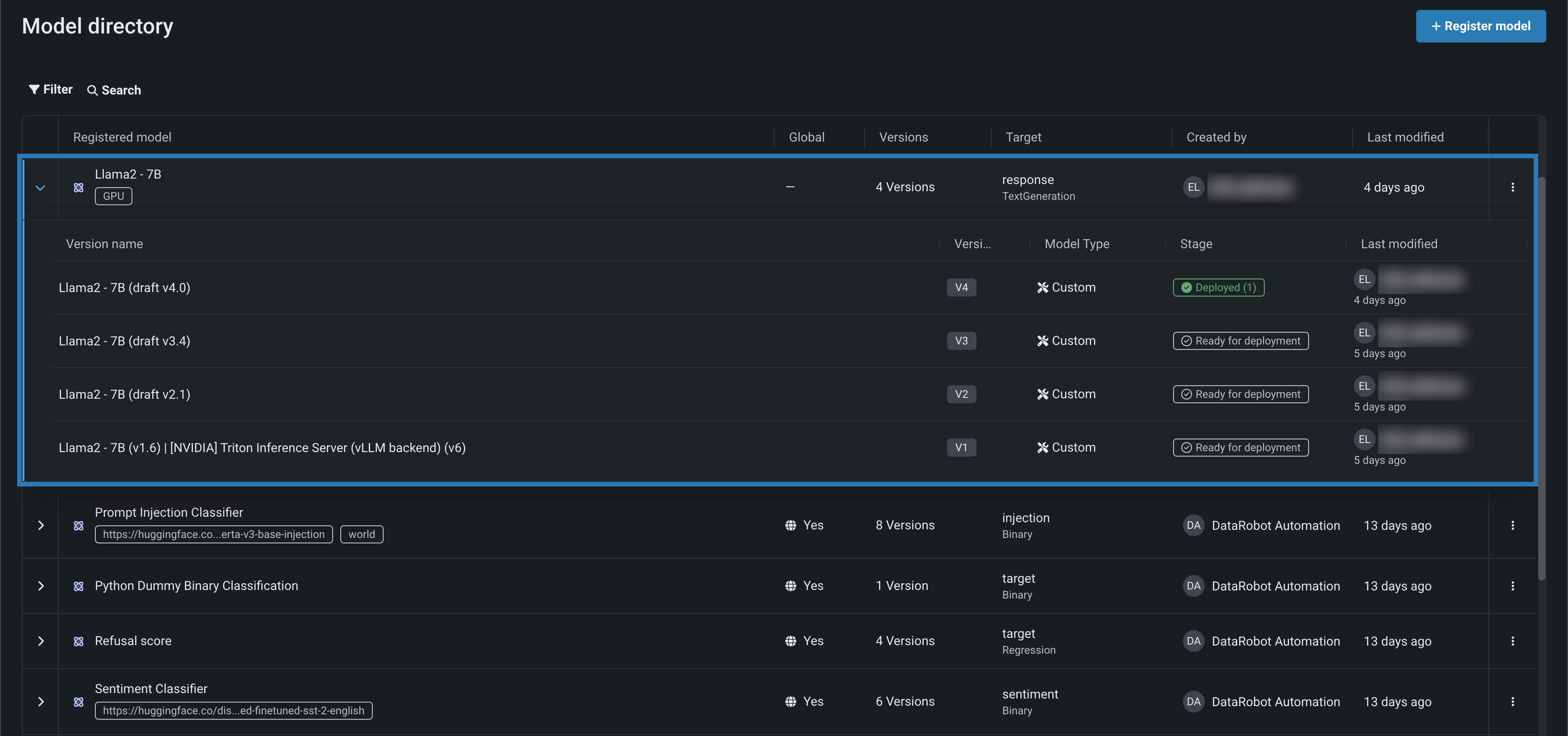
In the example above, you can see a Llama 2 model in the Model directory, with a GPU tag. Opening this registered model reveals, below, four versions of the Llama 2 model, assembled and tested for deployment on an NVIDIA Resource bundle.
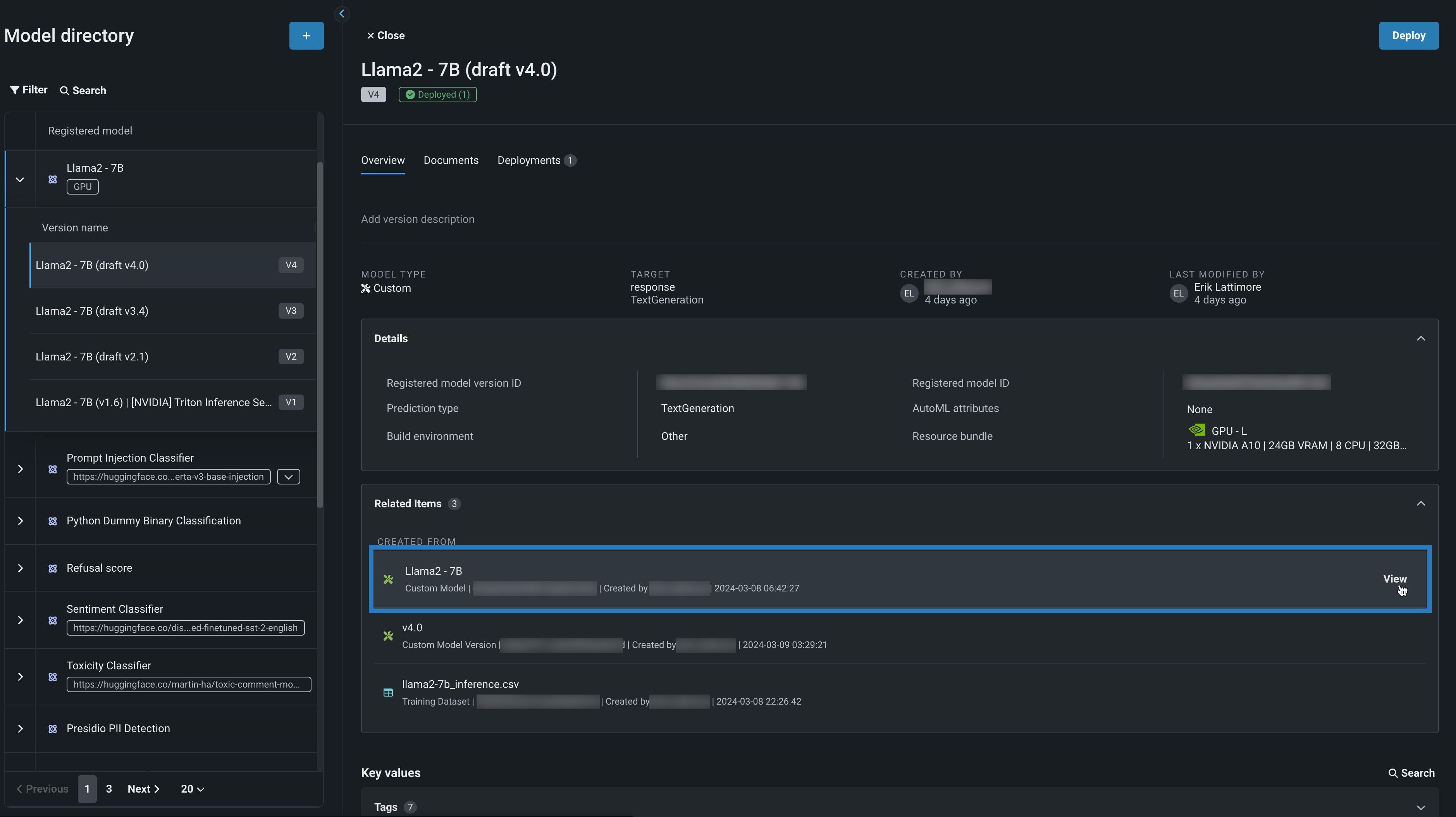
From the registered model version, review model Details, where the Resource bundle surfaces information about the NVIDIA resources used by the model. Opening the Related Items panel, click View to open the Llama 2 custom model in the model workshop.
From the Model workshop, open and review the Llama 2 custom model's Assemble tab to visualize how the model was constructed. For this model, you can see that DataRobot versions are built and tested. In the Environment section, you can see that the model is running on an [NVIDIA] Triton Inference Server base environment. DataRobot has natively built in the NVIDIA Triton Inference Server to provide extra acceleration for all of your GPU-based models as you build and deploy them onto NVIDIA devices.
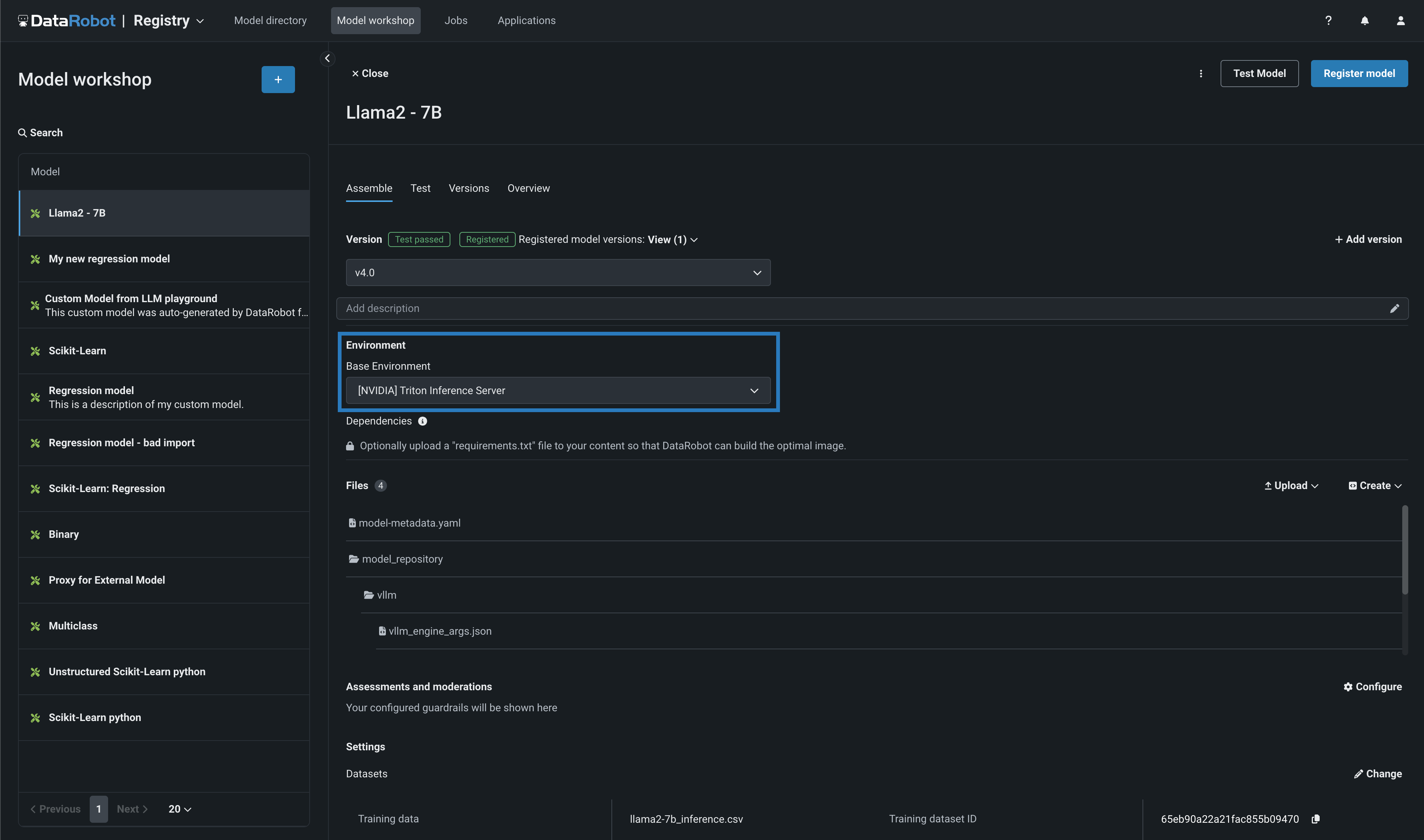
In the Files section, you can view, modify, or add model files. In the Runtime Parameters section, you can provide any important information to pass dynamically at runtime to the build process. Modifications to the custom model on this tab create a new minor version.
Navigating to the custom model's Settings section, review the Resources settings, a section surfacing information about the resources provided to the model. In this example, you can see that the Llama 2 model is built to be tested and deployed on an NVIDIA A10 device.
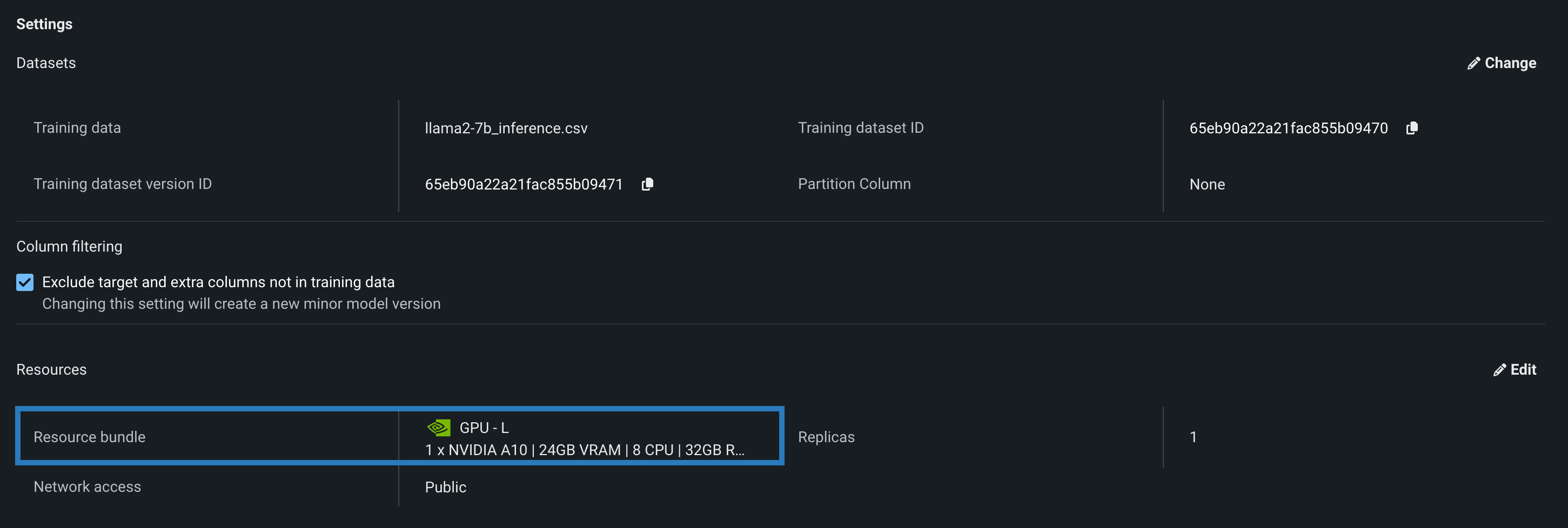
Click Edit to open the Update resource settings dialog box and, in the resource Bundle settings, review the range of NVIDIA devices available as build environments in DataRobot.
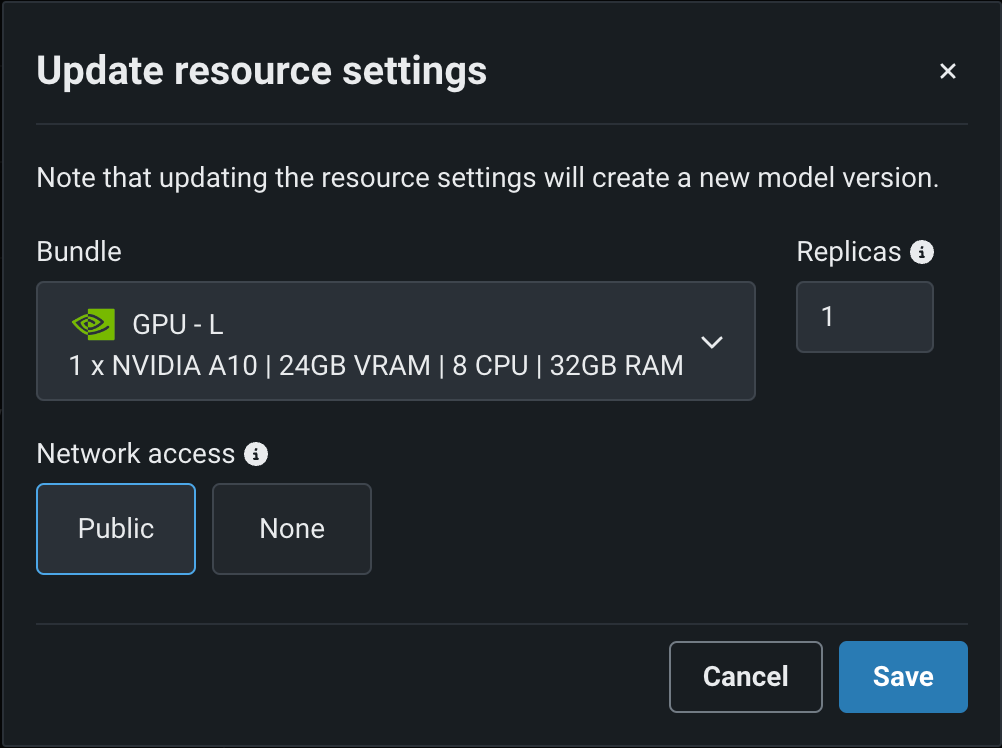
DataRobot can deploy models onto any of these NVIDIA resource bundles:
| Bundle | GPU | VRAM | CPU | RAM |
|---|---|---|---|---|
| GPU - S | 1 x NVIDIA T4 | 16GB | 4 | 16GB |
| GPU - M | 1 x NVIDIA T4 | 16GB | 8 | 32GB |
| GPU - L | 1 x NVIDIA A10 | 24GB | 8 | 32GB |
After assembling a model for the NVIDIA Triton Inference Server, you can open the Test tab. From there, DataRobot can verify that the container passes the Startup and Prediction error tests. DataRobot offers a wide range of custom model testing capabilities.
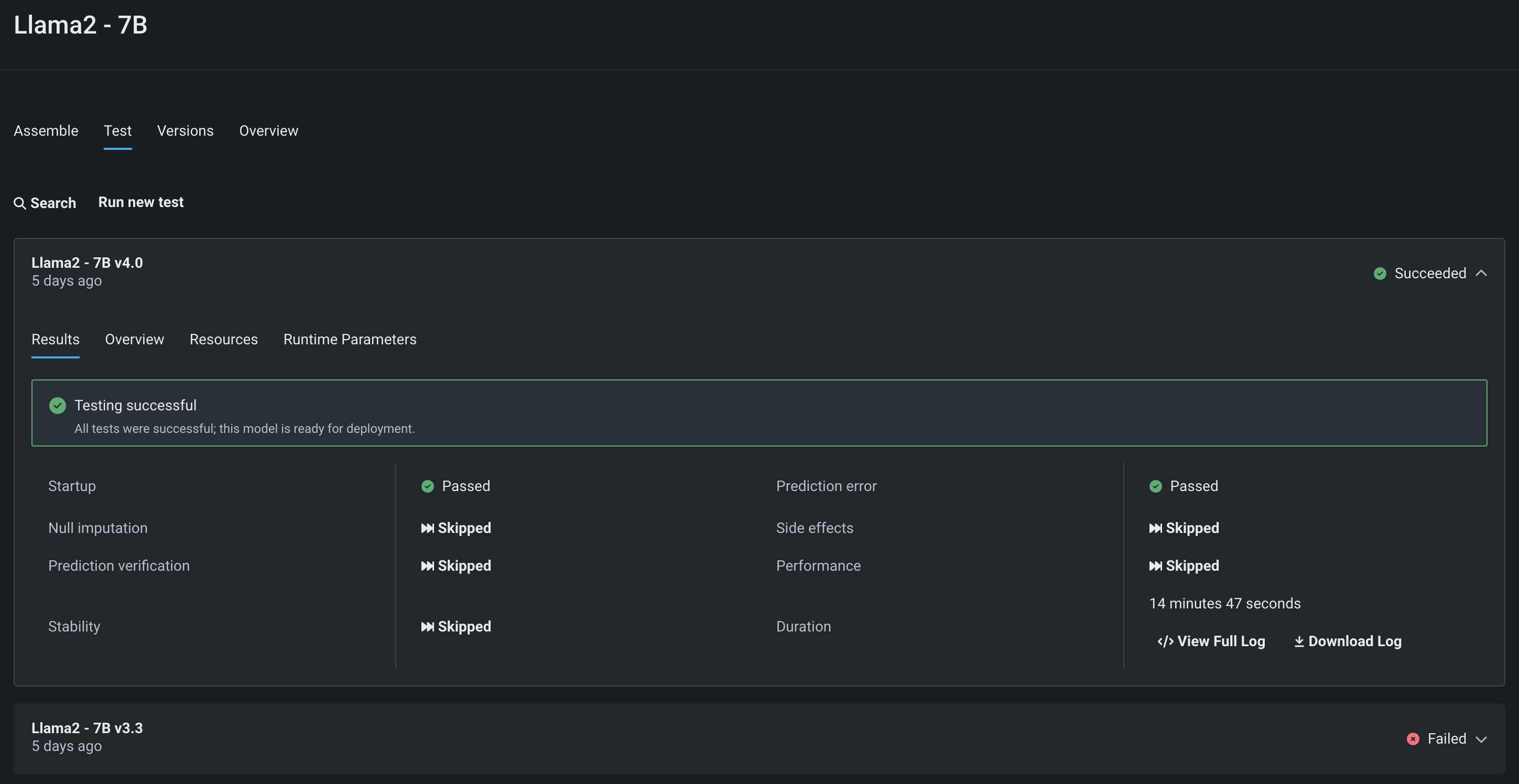
In addition, on the Runtime Parameters tab, you can pass parameters to the model at runtime for testing, as you can in production, to make sure that this new model container built on an NVIDIA Triton Inference Server is configured correctly and ready for production.
Deploy the model to production¶
Now that the Llama 2 model is assembled and tested on an NVIDIA resource bundle, you can register the model. In this example the model is already registered and the custom model is linked to the registered model version. DataRobot provides a direct connection to the registry's Model directory tab to review the model there.
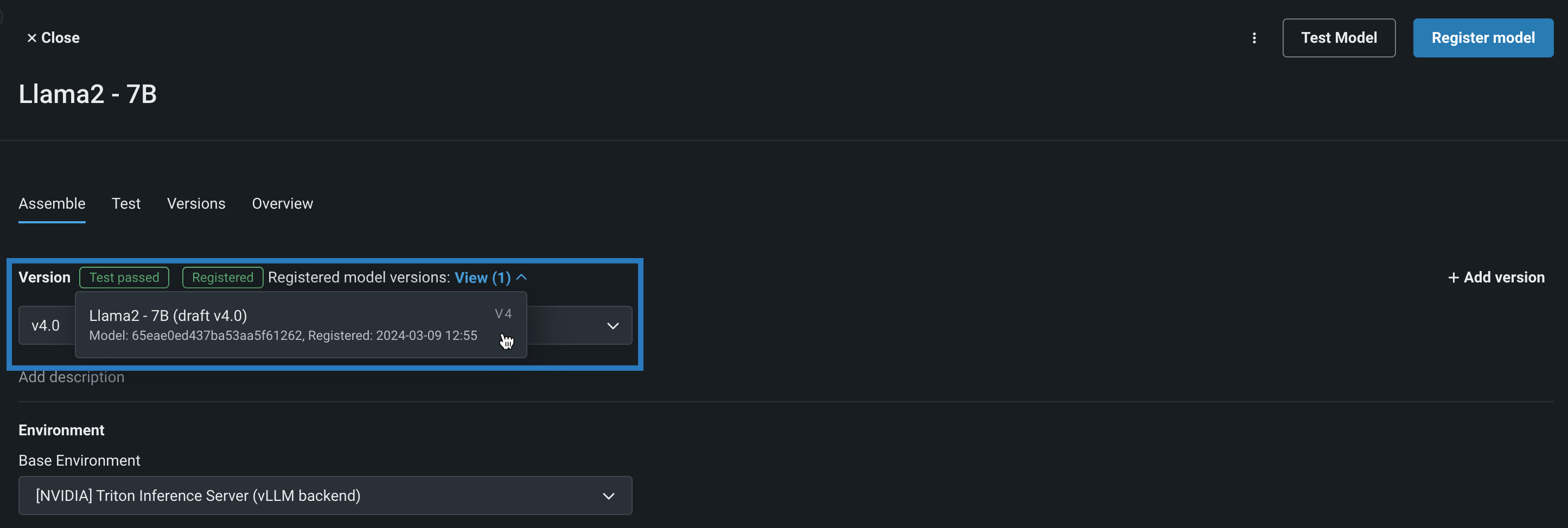
Back in this registry, you can see multiple builds, allowing you to share and socialize this model within your organization to seek approval for deployment. From the registered model, you can clearly see the resource bundle that this model was tested on and should be deployed to.
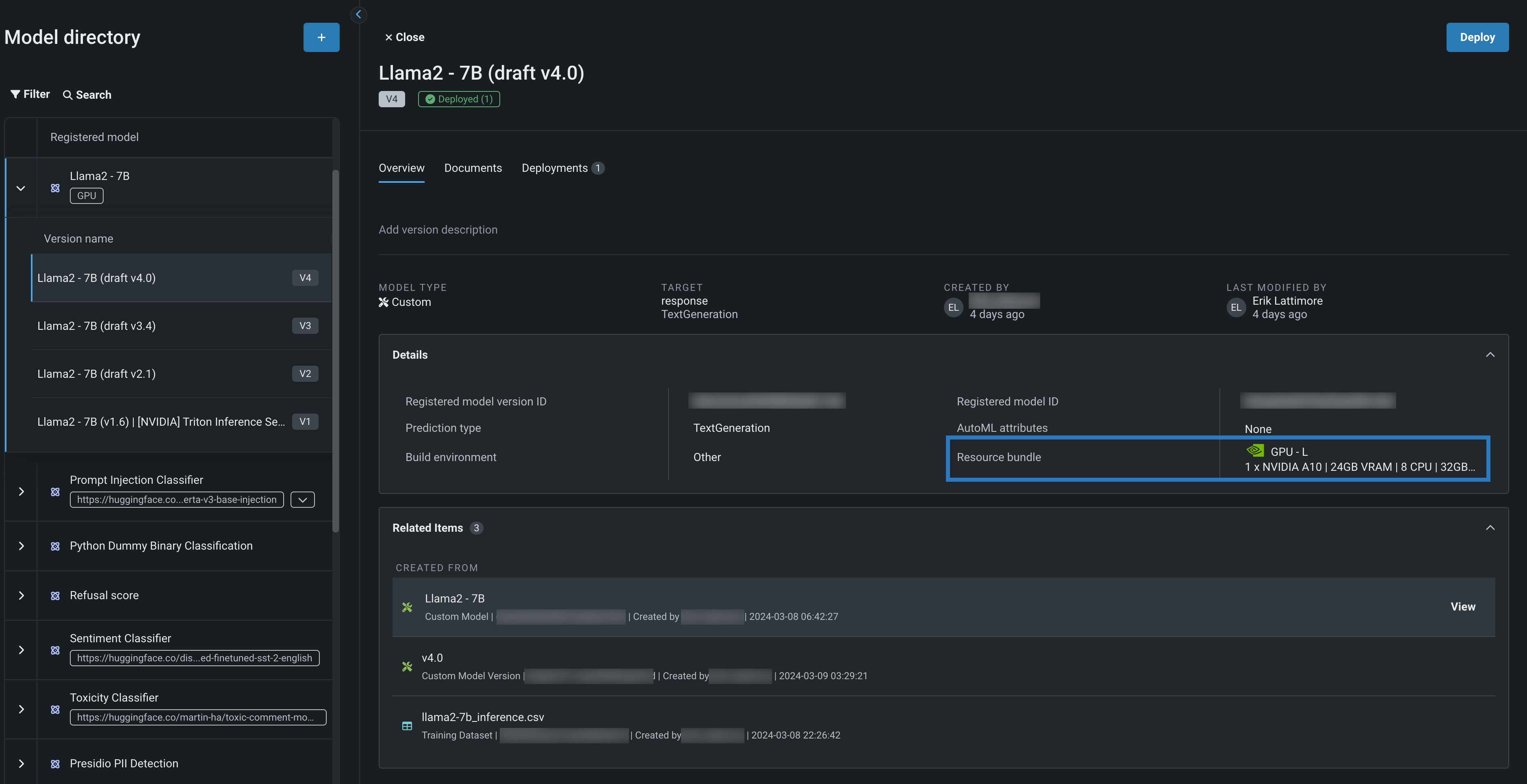
In addition to the versioning provided by the model directory, the registry also provides a clear model lineage through the Related Items panel, allowing you to review the Custom Model, Custom Model Version, and Training Dataset used to create the registered model. The training data provides a baseline for drift monitoring when the model is deployed. Your organization can also add custom metadata to categorize and identify models in the registry based on specific business needs and the specific controls required for each category.
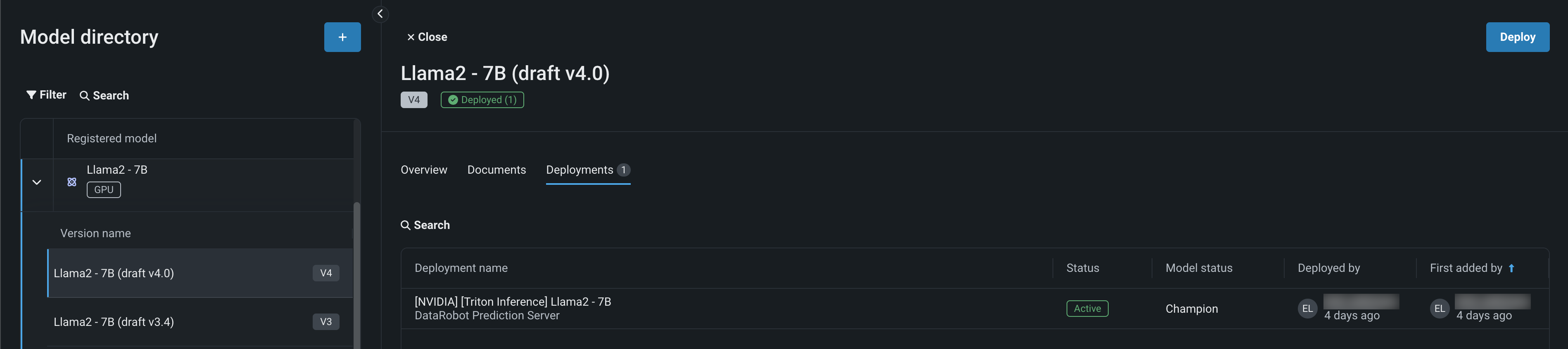
Now that the Llama 2 model is assembled, registered, and reviewed, deploy it to the appropriate NVIDIA A10 device. Once a registered model is deployed—as the Llama 2 model in this example is—you can view and access the deployment from the registry, on a model version's Deployments tab:
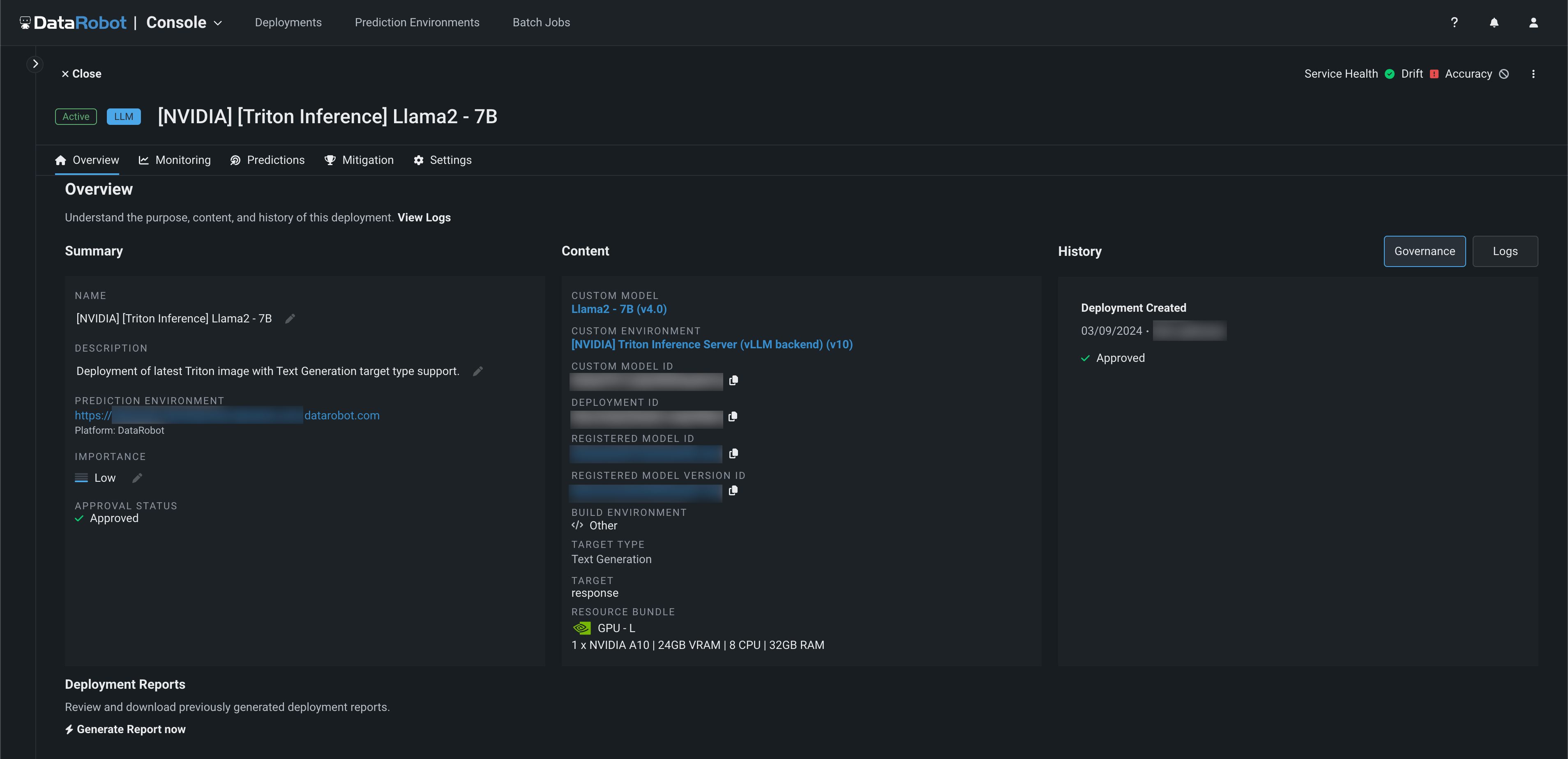
Opening the deployment, from the Overview tab, you can see that DataRobot has governed the approval process of this model's deployment. In the model History section, the Governance tab provides a persistent record indicating that the deployment was approved. From the Logs tab, you can see if the model was ever replaced, and if so, if there was a replacement reason. In this example, this model hasn't been replaced yet, as it was just recently deployed; however, over time, DataRobot will record the history of this deployed model and any additional models deployed behind this endpoint. In addition, you can see the Resources Bundle the Llama 2 model is deployed to, alongside information about the lineage of the model, with links to the model artifacts in the registry.
Monitor the deployed model¶
Once a model is deployed, DataRobot provides a wide range of monitoring tools, starting with IT metrics. Informational statistics—tile values—are based on your current settings for model and time frame (selected on the slider). If the slider interval values are weekly, for example, the displayed tile metrics show values corresponding to weeks. Clicking a metric tile updates the chart below the tiles.
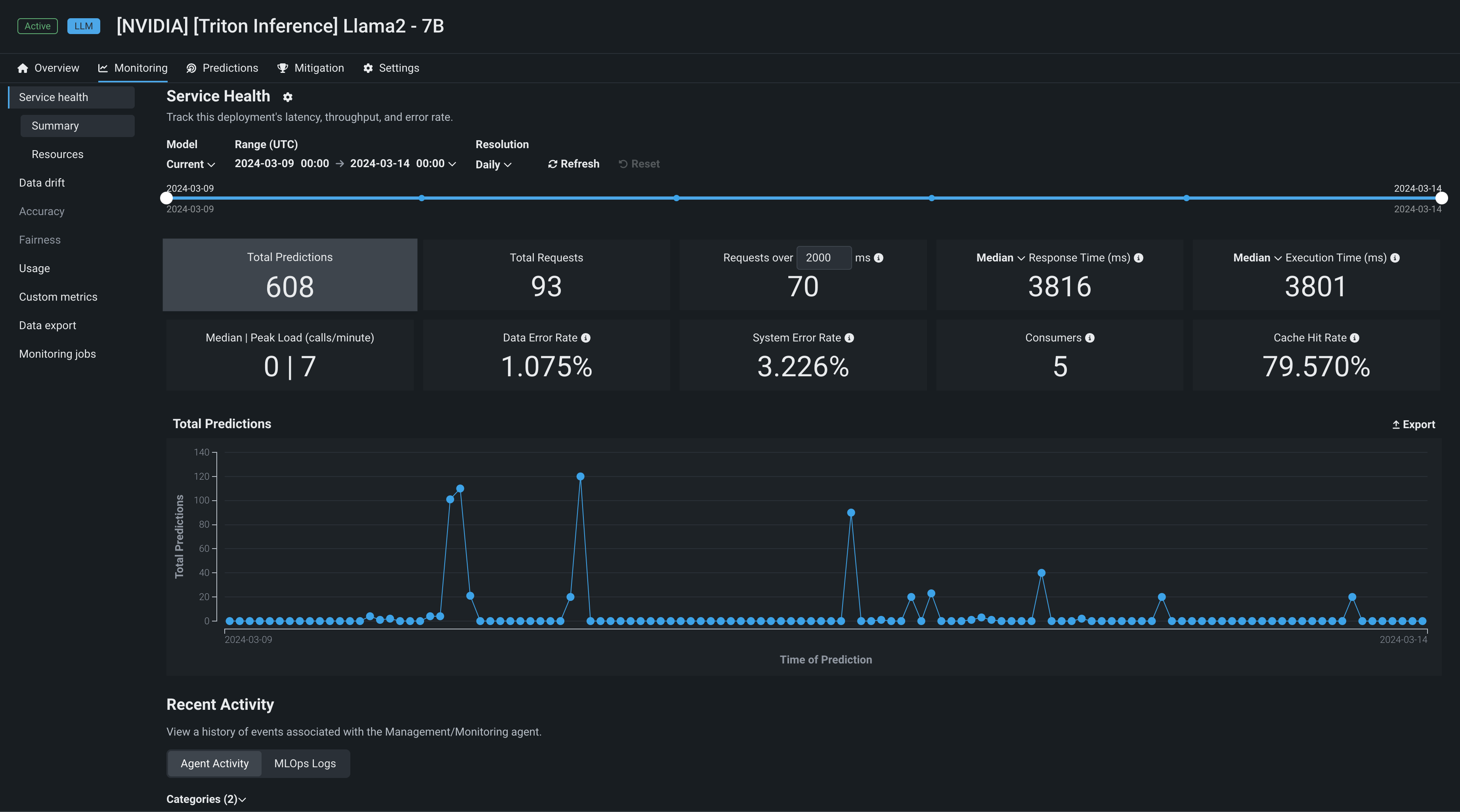
The Monitoring > Service health tab reports the following metrics on the dashboard:
| Statistic | Reports (for selected time period) |
|---|---|
| Total Predictions | The number of predictions the deployment has made. |
| Total Requests | The number of prediction requests the deployment has received (a single request can contain multiple prediction requests). |
Requests over x ms |
The number of requests where the response time was longer than the specified number of milliseconds. The default is 2000 ms; click in the box to enter a time between 10 and 100,000 ms or adjust with the controls. |
| Response Time | The time (in milliseconds) DataRobot spent receiving a prediction request, calculating the request, and returning a response. The report does not include time due to network latency. Select the median prediction request time or 90th, 95th, or 99th percentile. The display reports a dash if you have made no requests against it or if it's an external deployment. |
| Execution Time | The time (in milliseconds) DataRobot spent calculating a prediction request. Select the median prediction request time or 90th, 95th, or 99th percentile. |
| Median/Peak Load | The median and maximum number of requests per minute. |
| Data Error Rate | The percentage of requests that result in a 4xx error (problems with the prediction request submission). |
| System Error Rate | The percentage of well-formed requests that result in a 5xx error (problem with the DataRobot prediction server). |
| Consumers | The number of distinct users (identified by API key) who have made prediction requests against this deployment. |
| Cache Hit Rate | The percentage of requests that used a cached model (the model was recently used by other predictions). If not cached, DataRobot has to look the model up, which can cause delays. The prediction server cache holds 16 models by default, dropping the least-used model when the limit is reached. |
In addition to service health, DataRobot tracks data drift independently for prompts and completions. In the prompt and response word clouds, you can identify which tokens are contributing most to drift when compared to the baseline established by the training dataset uploaded during model assembly (and viewable in the registered model version).
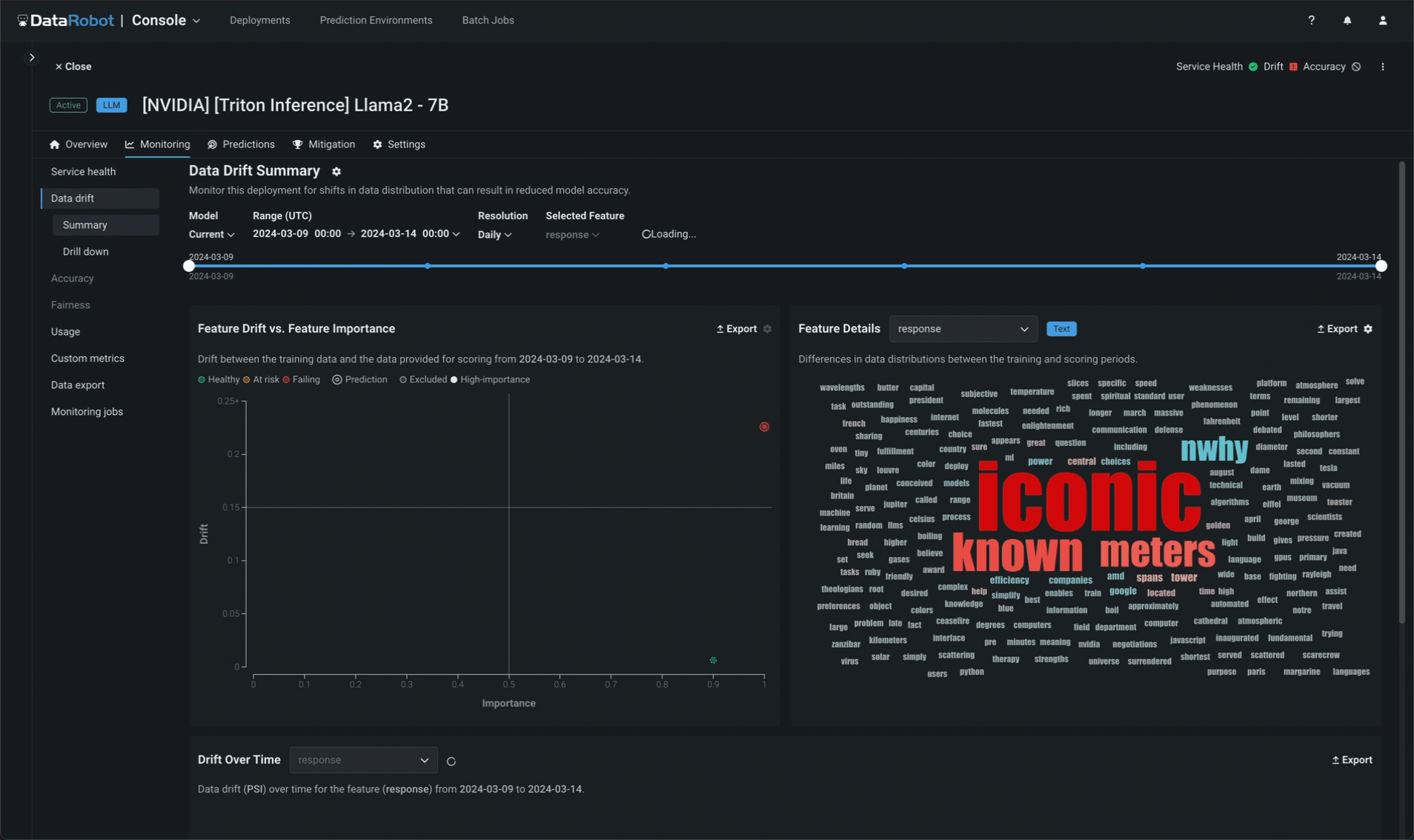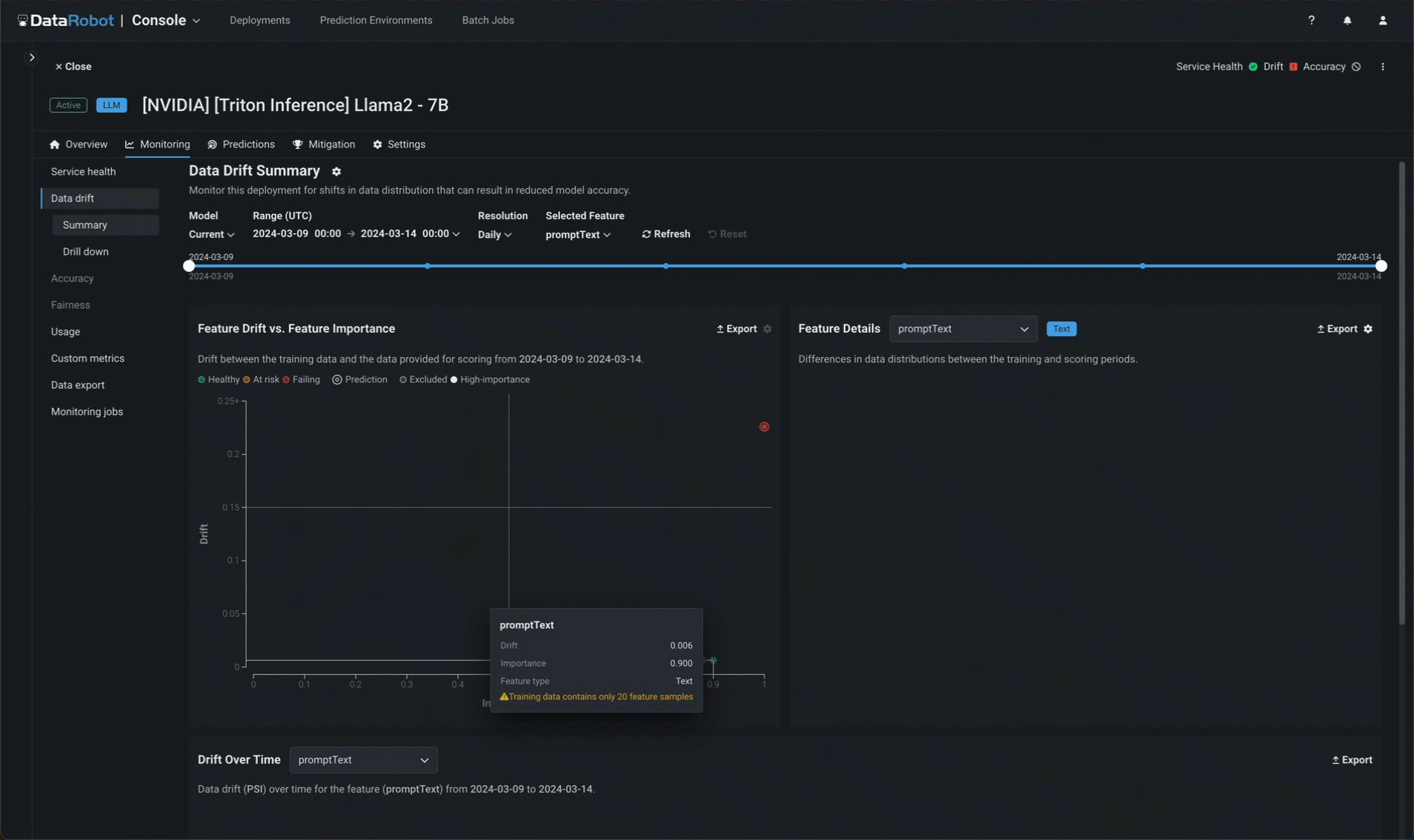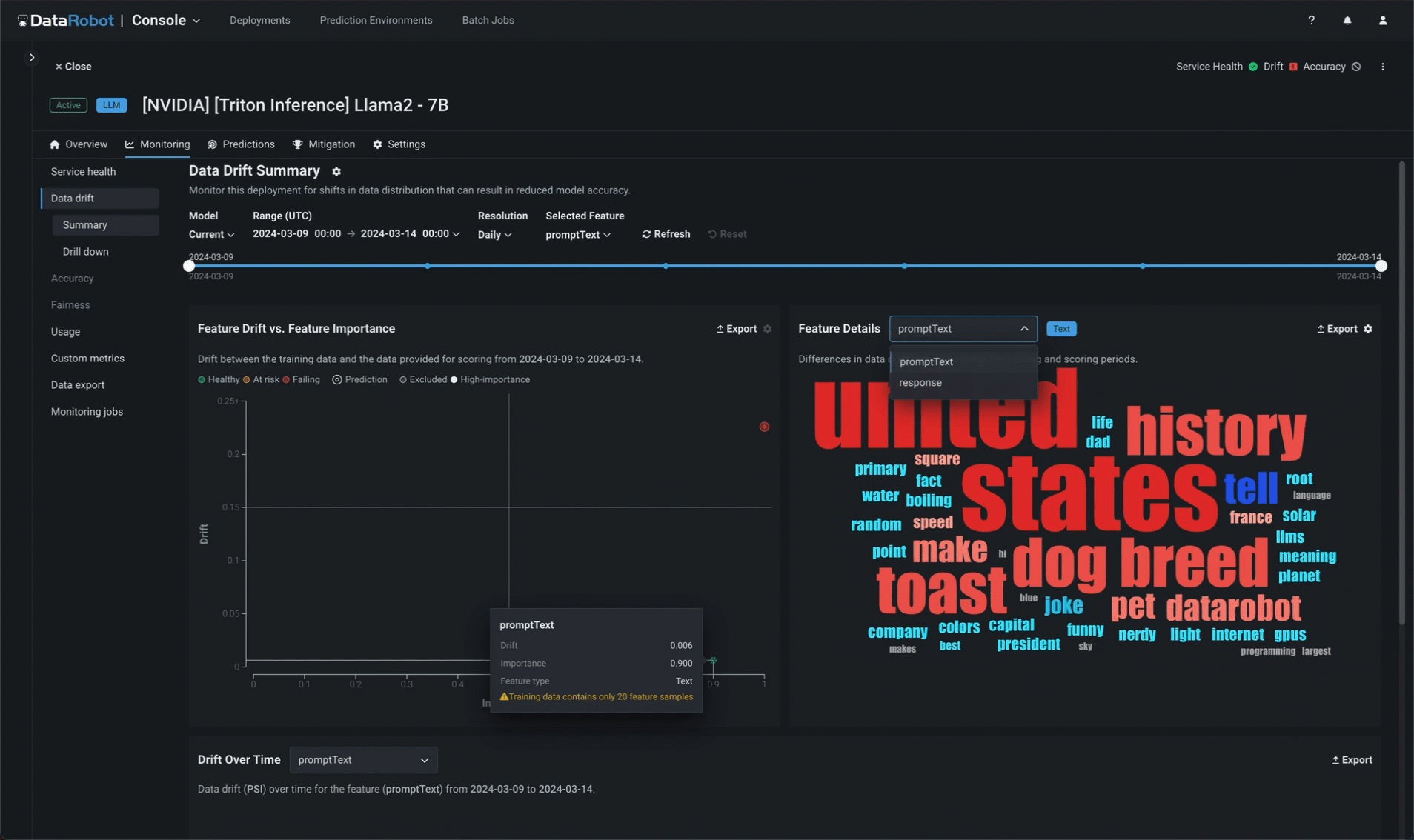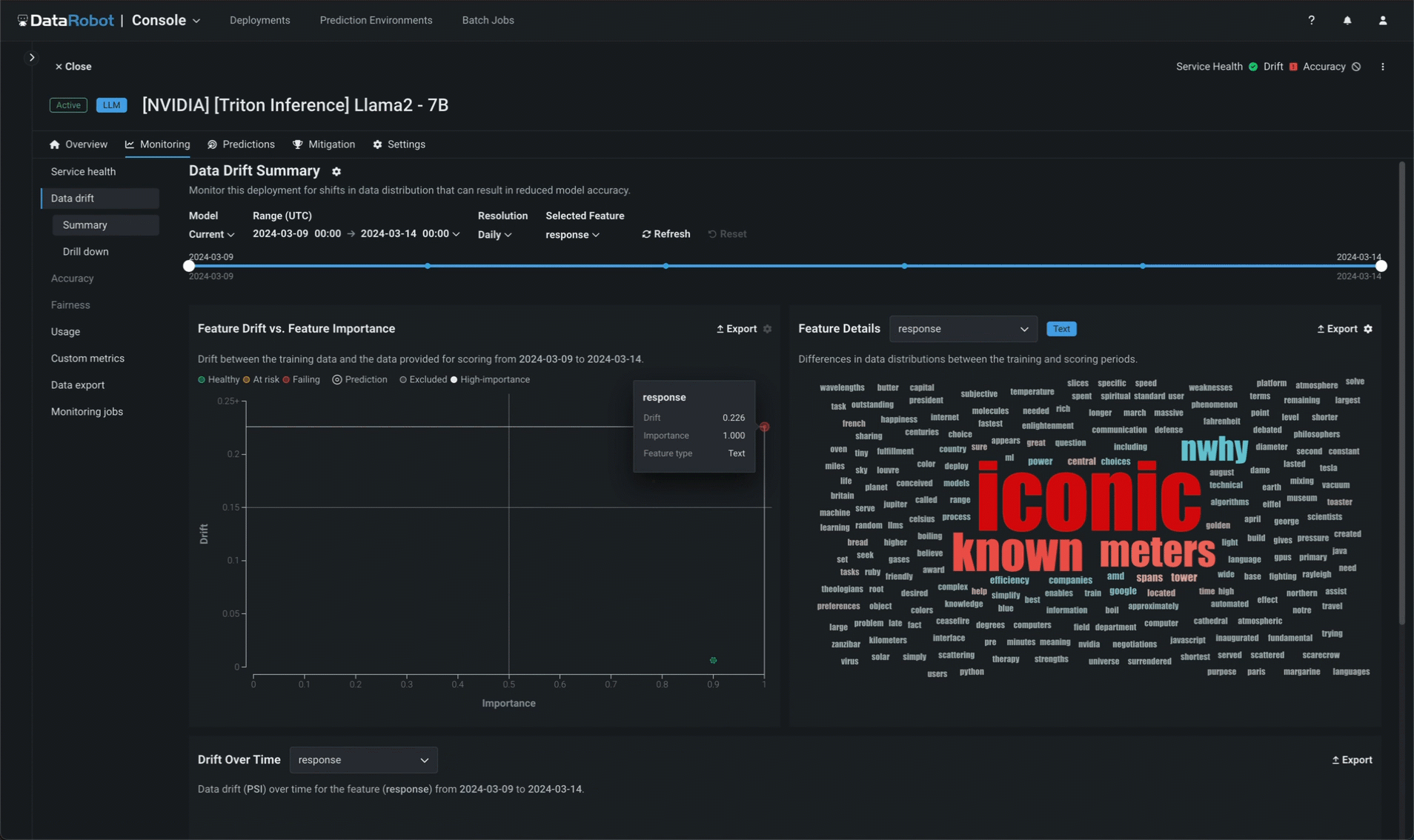
Implement NeMo Guardrails¶
In addition to the metrics available out of the box, DataRobot also provides a powerful interface to create custom metrics: from scratch, from a template, or through an integration with NeMo Guardrails. The integration with NeMo provides powerful rails to ensure your model stays on topic, using interventions to block prompts and completions if they violate the "on topic" principles provided by NeMo.
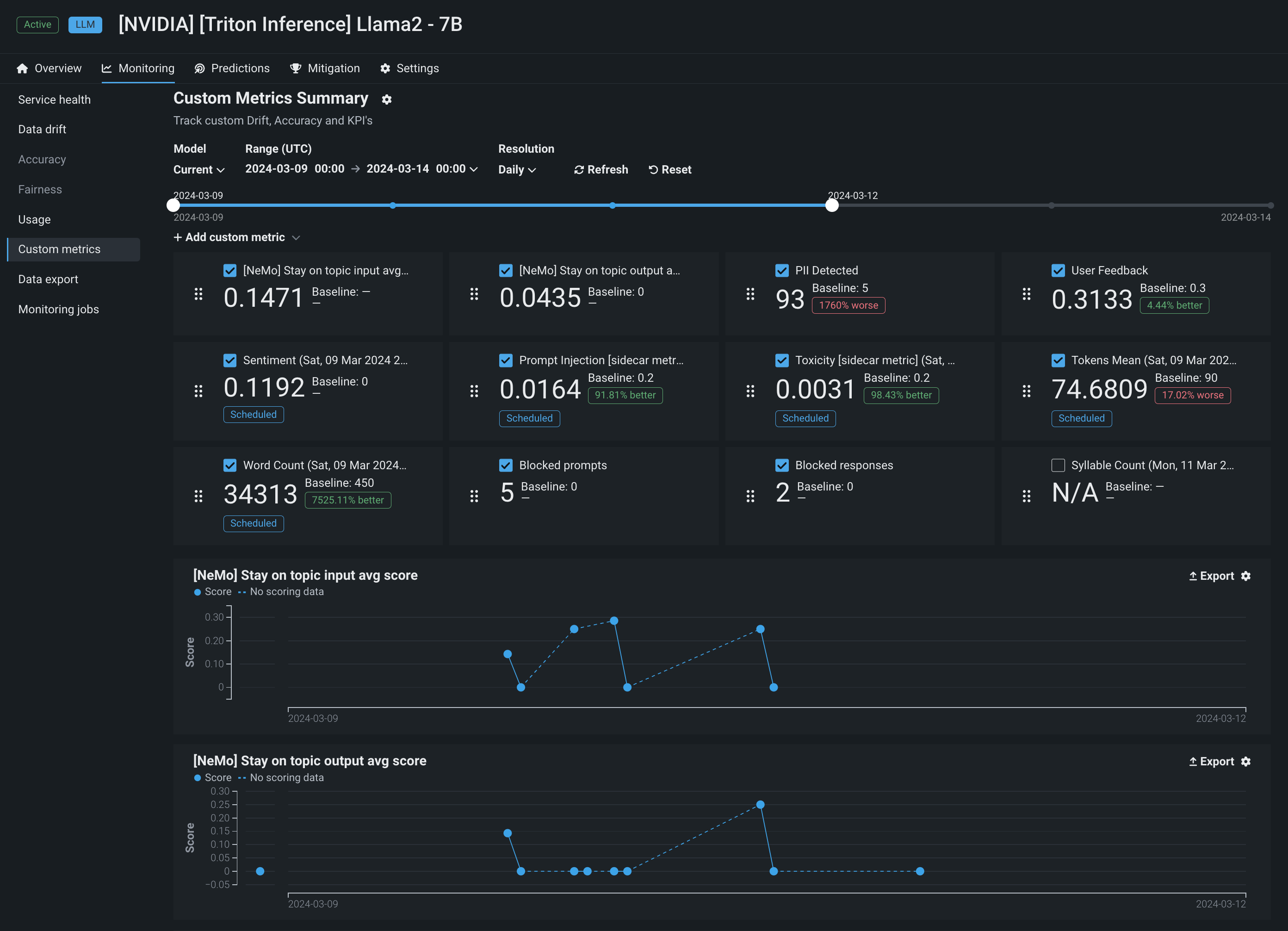
Alongside NeMo Guardrails, you can integrate the other guard models provided by DataRobot and track those metrics over time. For example, DataRobot provides a template for a personally identifiable information (PII) detection guard model, allowing you to scan a prompt for PII and sanitize that input before saving it to a prompt database. With custom metrics, DataRobot can:
-
Facilitate the human feedback loop by annotating each row in a deployment monitoring system with user feedback, if provided.
-
Monitor for prompt injection so you can create interventions to prevent them from reaching the model.
-
Monitor for sentiment and toxicity in prompts and responses.
-
Calculate operational metrics, like cost, by monitoring token use.