Score Snowflake data on AWS EMR Spark¶
DataRobot provides exportable Scoring Code that you can use to score millions of records on Spark. This topic shows how to do so with Snowflake as the data source and target. The steps can be used as a template you can modify to create Spark scoring jobs with different sources and targets.
About the technologies¶
Click a tab to learn about the technologies discussed in this topic.
Apache Spark is an open source cluster computing framework considered to be in the "Big Data" family of technologies. Spark is used for large volumes of data in structured or semi-structured forms—in streaming or batch modes. Spark does not have its own persistent storage layer. It relies on file systems like HDFS, object storage like AWS S3, and JDBC interfaces for data.
Popular Spark platforms include Databricks and AWS Elastic Map Reduce (EMR). The example in this topic shows how to score using EMR Spark. This is a Spark cluster that can be spun up for work as needed and shut down when work is completed.
S3 is the object storage service of AWS. It is used in this example to store and retrieve the job's database query dynamically. S3 can also write to as a job completion target. In addition, cluster log files are written to S3.
Hardcoding credentials can be done during development or for ad-hoc jobs, although as a best practice it is ideal, even in development, to score these in a secure fashion. This is a requirement for safely protecting them in production scoring jobs. The Secrets Manager service will allow only trusted users or roles to be able to access securely stored secret information.
For brevity and ease of use, the AWS CLI will be used to perform command line operations for several activities related to AWS activities throughout this article. These activities could also be performed manually via the GUI. See AWS Command Line Interface Documentation for more information on configuring the CLI.
Snowflake is a cloud-based database platform designed for data warehouse and analytic workloads. It allows for easy scale-up and scale-out capabilities for working on large data volume use cases and is available as a service across all major cloud platforms. For the scoring example in this topic, Snowflake is the source and target, although both can be swapped for other databases or storage platforms for Spark scoring jobs.
You can quickly and easily deploy models in DataRobot for API hosting within the platform. In some cases, rather than bringing the data to the model in the API, it can be beneficial to bring the model to the data, for example, for very large scoring jobs. The example that follows scores three million Titanic passengers for survival probability from an enlarged Kaggle dataset. Although not typically an amount that would warrant considering using Spark over the API, here it serves as a good technical demonstration.
You can export models from DataRobot in Java or Python as a rules-based approximation with DataRobot RuleFit models. A second export option is Scoring Code, which provides source code and a compiled Java binary JAR which holds the exact model chosen.
Structured Query Language (SQL) is used for the database, Scala for Spark. Python/PySpark can also be leveraged for running jobs on Spark.
Architecture¶
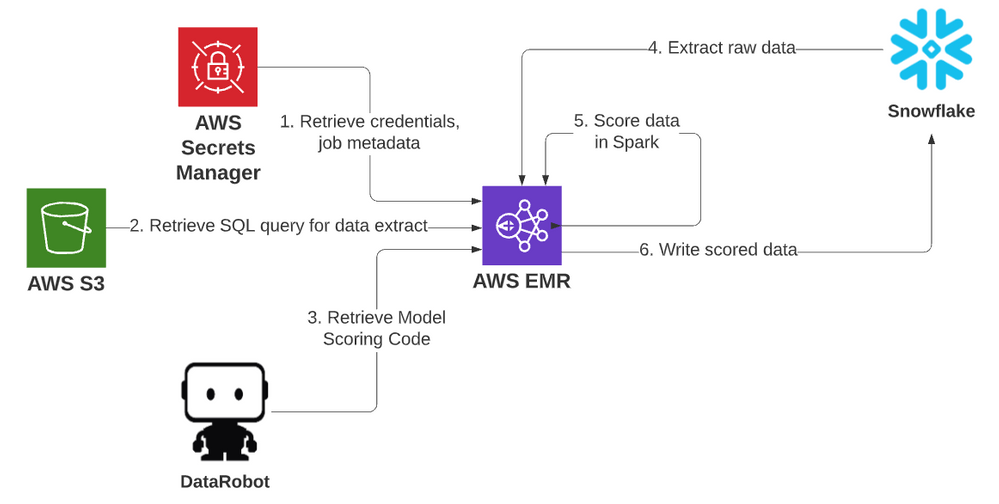
Development Environment¶
AWS EMR includes a Zeppelin Notebook service, which allows for interactive development of Spark code. To set up a development environment, first create an EMR cluster. You can do this via GUI options on AWS; the defaults are acceptable. Be sure to choose the Spark option. Note the advanced settings allow for more granular choices of software installation.
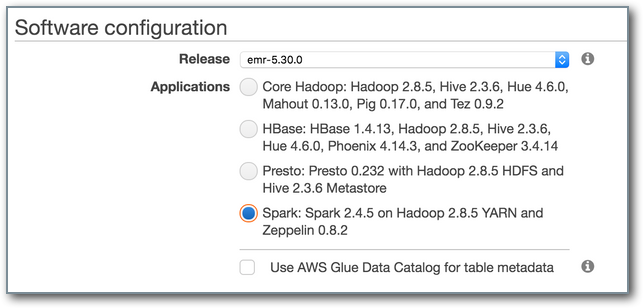
Upon successful creation, when viewing the Summary tab on the cluster the AWS CLI export button provides a CLI script to recreate the instance, which can be saved and edited for the future. An example is as follows:
aws emr create-cluster \
--applications Name=Spark Name=Zeppelin \
--configurations '[{"Classification":"spark","Properties":{}}]' \
--service-role EMR_DefaultRole \
--enable-debugging \
--release-label emr-5.30.0 \
--log-uri 's3n://mybucket/emr_logs/' \
--name 'Dev' \
--scale-down-behavior TERMINATE_AT_TASK_COMPLETION \ --region us-east-1 \
--tags "owner=doyouevendata" "environment=development" "cost_center=comm" \
--ec2-attributes '{"KeyName":"creds","InstanceProfile":"EMR_EC2_DefaultRole","SubnetId":"subnet-0e12345","EmrManaged
SlaveSecurityGroup":"sg-123456","EmrManagedMasterSecurityGroup":"sg-01234567"}' \
--instance-groups '[{"InstanceCount":1,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"SizeInGB"
:32,"VolumeType":"gp2"},"VolumesPerInstance":2}]},"InstanceGroupType":"MASTER","InstanceType":"m5.xlarge","Name":"Master
Instance Group"},{"InstanceCount":2,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"SizeInGB":32,"
VolumeType":"gp2"},"VolumesPerInstance":2}]},"InstanceGroupType":"CORE","InstanceType":"m5.xlarge","Name":"Core Instance
Group"}]'
You can find connectivity details about the cluster in the GUI. Log on to the server to provide additional configuration items. You can access a terminal via SSH; this requires a public-facing IP or DNS address, and that the VPC inbound ruleset applied to the EC2 cluster master instance allows incoming connections over SSH port 22. If connectivity is refused because the machine is unreachable, add source IP/subnets to the security group.
ssh -i ~/creds.pem hadoop@ec2-54-121-207-147.compute-1.amazonaws.com
Several packages are used to support database connectivity and model scoring. These JARs can be loaded to cluster nodes when the cluster is created to have them available in the environment. They can also be compiled into JARs for job submission, or they can be downloaded from a repository at run time. This example uses the last option.
The AWS environment used in this article is based on EWS EMR 5.30 with Spark 2.11. Some changes may be necessary to follow along as new versions of referenced environments and packages are released. In addition to those already provided by AWS, two Snowflake and two DataRobot packages are used:
To leverage these packages in the Zeppelin notebook environment, edit the zeppelin-env file to add the packages when the interpreter is invoked. Edit this file on the master node.
sudo vi /usr/lib/zeppelin/conf/zeppelin-env.sh
Edit the export SPARK_SUBMIT_OPTIONS line at the bottom of the file and add the packages flag to the string value.
--packages net.snowflake:snowflake-jdbc:3.12.5,net.snowflake:spark-
snowflake_2.11:2.7.1-spark_2.4,com.datarobot:scoring-code-spark-api_2.4.3:0.0.19,com.datarobot:datarobot-
prediction:2.1.4
If you make further edits while working in Zeppelin, you'll need to restart the interpreter within the Zeppelin environment for the edits to take effect.
You can now establish an SSH tunnel to access the remote Zeppelin server from a local browser. The following command forwards port 8890 on the master node to the local machine. Without using a public DNS entry, additional proxy configuration may be required. This statement leverages "Option 1" in the following topic. A proxy for the second option as well as additional ports and services can be found here.
ssh -i ~/creds.pem -L 8890:ec2-54-121-207-147.compute-1.amazonaws.com:8890
hadoop@ec2-54-121-207-147.compute-1.amazonaws.com -Nv
Navigating to port 8890 on the local machine now brings up the Zeppelin instance where a new note can be created along with the packages, as defined in the environment shell script.
Several helper tools are provided on GitHub to aid in quickly and programmatically performing this process (and others described in this article) via the AWS CLI from a local machine.
env_config.sh contains AWS environment variables, such as profile (if used), tags, VPCs, security groups, and other elements used in specifying a cluster.
snow_bootstrap.sh is an optional file to perform tasks on the EMR cluster nodes after they are allocated, but before applications like Spark are installed.
create_dev_cluster.sh uses the above to create a cluster and provides connectivity strings. It takes no arguments.
Create Secrets¶
You can code credentials into variables during development, although this topic demonstrates how to create a production EMR job with auto-termination upon completion. It is a good practice to store secret values such as database usernames and passwords in a trusted environment. In this case, the IAM Role applied to the EC2 instances has been granted the privilege to interact with the AWS Secrets Manager service.
The simplest form of a secret contains a string reference name and a string of values to store. The process for creating one is straightforward in the AWS GUI and will guide the creation of a secret, with a string representing provided keys and values in JSON. Some helper files are available to do this with the CLI.
secrets.properties is a JSON list of secrets to store.
Example contents:
{
"dr_host":"https://app.datarobot.com",
"dr_token":"N1234567890",
"dr_project":"5ec1234567890",
"dr_model":"5ec123456789012345",
"db_host":"dp12345.us-east-1.snowflakecomputing.com",
"db_user":"snowuser",
"db_pass":"snow_password",
"db_db":"TITANIC",
"db_schema":"PUBLIC",
"db_query_file":"s3://bucket/ybspark/snow.query",
"db_output_table":"PASSENGERS_SCORED",
"s3_output_loc":"s3a://bucket/ybspark/output/",
"output_type":"s3"
}
create_secrets.sh is a script which leverages the CLI to create (or update) the secret name specified within the script with the properties file.
Source SQL Query¶
Instead of putting a SQL extract statement into the code, instead it can be provided dynamically at runtime. It is not necessarily a secret and, given its potential length and complexity, it fits better as simply a file in S3. One of the secrets is pointing to this location, the db_query_file entry. The contents of this file on S3—s3://bucket/ybspark/snow.query is simply a SQL statement against a table with three million passenger records:
select * from passengers_3m
Spark Code (Scala)¶
With supporting components in place, code to construct the model scoring pipeline can begin. It can be run on a spark-shell instance directly on the machine, with a helper to include the necessary packages with run_spark-shell.sh and spark_env.sh. This interactive session may assist in some quick debugging, but it only uses the master node and is not a friendly environment to iterate code development in. The Zeppelin notebook is a more friendly environment to do so in and runs the code in yarn-cluster mode, leveraging the multiple worker nodes available. The code below can be copied or the note can simply be imported from the snowflake_scala_note.json in the GitHub repo for this project.
Import package dependencies¶
import org.apache.spark.sql.functions.{col}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.apache.spark.sql.SaveMode
import java.time.LocalDateTime
import com.amazonaws.regions.Regions
import com.amazonaws.services.secretsmanager.AWSSecretsManagerClientBuilder
import com.amazonaws.services.secretsmanager.model.GetSecretValueRequest
import org.json4s.{DefaultFormats, MappingException}
import org.json4s.jackson.JsonMethods._
import com.datarobot.prediction.spark.Predictors.{getPredictorFromServer, getPredictor}
Create helper functions to simplify process¶
/* get secret string from secrets manager */
def getSecret(secretName: String): (String) = {
val region = Regions.US_EAST_1
val client = AWSSecretsManagerClientBuilder.standard()
.withRegion(region)
.build()
val getSecretValueRequest = new GetSecretValueRequest()
.withSecretId(secretName)
val res = client.getSecretValue(getSecretValueRequest)
val secret = res.getSecretString
return secret
}
/* get secret value from secrets string once provided key */
def getSecretKeyValue(jsonString: String, keyString: String): (String) = {
implicit val formats = DefaultFormats
val parsedJson = parse(jsonString)
val keyValue = (parsedJson \ keyString).extract[String]
return keyValue
}
/* run sql and extract sql into spark dataframe */
def snowflakedf(defaultOptions: Map[String, String], sql: String) = {
val spark = SparkSession.builder.getOrCreate()
spark.read
.format("net.snowflake.spark.snowflake")
.options(defaultOptions)
.option("query", sql)
.load()
}
Retrieve and parse secrets¶
Next, retrieve and parse the secrets data stored in AWS to support the scoring job.
val SECRET_NAME = "snow/titanic"
printMsg("db_log: " + "START")
printMsg("db_log: " + "Creating SparkSession...")
val spark = SparkSession.builder.appName("Score2main").getOrCreate();
printMsg("db_log: " + "Obtaining secrets...")
val secret = getSecret(SECRET_NAME)
printMsg("db_log: " + "Parsing secrets...")
val dr_host = getSecretKeyValue(secret, "dr_host")
val dr_project = getSecretKeyValue(secret, "dr_project")
val dr_model = getSecretKeyValue(secret, "dr_model")
val dr_token = getSecretKeyValue(secret, "dr_token")
val db_host = getSecretKeyValue(secret, "db_host")
val db_db = getSecretKeyValue(secret, "db_db")
val db_schema = getSecretKeyValue(secret, "db_schema")
val db_user = getSecretKeyValue(secret, "db_user")
val db_pass = getSecretKeyValue(secret, "db_pass")
val db_query_file = getSecretKeyValue(secret, "db_query_file")
val output_type = getSecretKeyValue(secret, "output_type")
Read query into a variable¶
Next, read the query hosted on S3 and specified in db_query_file into a variable.
printMsg("db_log: " + "Retrieving db query...")
val df_query = spark.read.text(db_query_file)
val query = df_query.select(col("value")).first.getString(0)
Retrieve the Scoring Code¶
Next, retrieve the Scoring Code for the model from DataRobot. Although this can be done from a local JAR, the code here retrieves it from DataRobot on the fly. This model can be easily swapped out for another by changing the dr_model value referenced in the secrets.
printMsg("db_log: " + "Loading Model...")
val spark_compatible_model = getPredictorFromServer(host=dr_host, projectId=dr_project, modelId=dr_model, token=dr_token)
Run the SQL¶
Now, run the SQL retrieved against the database and bring it into a Spark dataframe.
printMsg("db_log: " + "Extracting data from database...")
val defaultOptions = Map(
"sfURL" -> db_host,
"sfAccount" -> db_host.split('.')(0),
"sfUser" -> db_user,
"sfPassword" -> db_pass,
"sfDatabase" -> db_db,
"sfSchema" -> db_schema
)
val df = snowflakedf(defaultOptions, query)

Score the dataframe¶
The example below scores the dataframe through the retrieved DataRobot model. It creates a subset of the output containing just the identifying column (Passenger ID) and the probability towards the positive class label 1, i.e., the probability of survival for the passenger.
printMsg("db_log: " + "Scoring Model...")
val result_df = spark_compatible_model.transform(df)
val subset_df = result_df.select("PASSENGERID", "target_1_PREDICTION")
subset_df.cache()

Write the results¶
The value output_type dictates whether the scored data is written back to a table in the database or a location in S3.
if(output_type == "s3") {
val s3_output_loc = getSecretKeyValue(secret, "s3_output_loc")
printMsg("db_log: " + "Writing to S3...")
subset_df.write.format("csv").option("header","true").mode("Overwrite").save(s3_output_loc)
}
else if(output_type == "table") {
val db_output_table = getSecretKeyValue(secret, "db_output_table")
subset_df.write
.format("net.snowflake.spark.snowflake")
.options(defaultOptions)
.option("dbtable", db_output_table)
.mode(SaveMode.Overwrite)
.save()
}
else {
printMsg("db_log: " + "Results not written to S3 or database; output_type value must be either 's3' or 'table'.")
}
printMsg("db_log: " + "Written record count - " + subset_df.count())
printMsg("db_log: " + "FINISH")
This approach works well for development and manual or ad-hoc scoring needs. You can terminate the EMR cluster when all work is complete. AWS EMR can also be leveraged to create routinely run production jobs on a schedule as well.
Productionalize the Pipeline¶
A production job can be created to run this job on regular intervals. The process of creating an EMR instance is similar; however, the instance will be set to run some job steps after it comes online. After the steps are completed, the cluster will be automatically terminated as well.
The Scala code however cannot be run as a scripted step. It must be compiled into a JAR for submission. The open source build tool sbt is used for compiling Scala and Java code. In the repo, sbt was installed already (using commands in the snow_bootstrap.sh script). Note this is only required for development to compile the JAR and can be removed from any production job run. Although the code does not need to be developed on the actual EMR master node, it does present a good environment for development because that is where the code will ultimately be run. The main files of interest in the project are:
snowscore/build.sbt
snowscore/create_jar_package.sh
snowscore/spark_env.sh
snowscore/run_spark-submit.sh
snowscore/src/main/scala/com/comm_demo/SnowScore.scala
-
build.sbtcontains the prior referred to packages for Snowflake and DataRobot, and includes two additional packages for working with AWS resources. -
create_jar_package.sh,spark_env.sh, andrun_spark-submit.share helper functions. The first function runs a clean package build of the project, and the latter two functions allow for submission to the spark cluster of the built package JAR simply from the command line. -
SnowScore.scalacontains the same code referenced above, arranged in a main class to be called when submit to the cluster for execution.
Run the create_jar_package.sh to create the output package JAR, which calls sbt clean and sbt package. This creates the JAR ready for job submission, target/scala-2.11/score_2.11-0.1.0-SNAPSHOT.jar.
The JAR can be submitted with the run_spark-submit.sh script; however, to use it in a self-terminating cluster it needs to be hosted on S3.
In this example, it has been copied over to s3://bucket/ybspark/score_2.11-0.1.0-SNAPSHOT.jar.
If on a development EMR instance, after the JAR has been copied over to S3, the instance can be terminated.
Lastly, the run_emr_prod_job.sh script can be run to call an EMR job using the AWS CLI to create an EMR instance, run a bootstrap script, install necessary applications, and execute a step function to call the main class of the S3 hosted package JAR. The --steps argument in the script creates the step to call the spark-submit job on the cluster. Note that the --packages argument submits the snapshot JAR and the main class that are specified in this attribute at runtime. Upon completion of the JAR, the EMR instance self-terminates.
The production job creation is now complete. This may be run by various triggers or scheduling tools. By updating the snow.query file hosted on S3, the input can be modified; in addition, the output targets of tables in the database or object storage on S3 can also be modified. Different machine learning models from DataRobot can easily be swapped out as well, with no additional compilation or coding required.
Performance and cost considerations¶
Consider this example as a reference: A MacBook containing a i5-7360U CPU @ 2.30GHz and running a local (default option) Scoring Code CSV job scored at a rate of 5,660 rec/s. When using a system with m5.xlarge (4 vCPU 16GB RAM) for MASTER and CORE EMR nodes, running a few tests from 3 million to 28 million passenger records ran from 12,000–22,000 rec/s per CORE node .
There is startup time required to construct an EMR cluster; this varies and takes 7+ minutes. There is additional overhead in simply running a Spark job. Scoring 418 records on a 2-CORE node system through the entire pipeline took 512 seconds total. However, scoring 28 million on a 4-CORE node system took 671 seconds total. Pricing, another consideration, is based on instance hours for EC2 compute and EMR services.
Examination of the scoring pipeline job alone as coded, without any tweaks to code, shows Spark, or EMR, scaling of 28 million records—from 694 seconds on 2 CORE nodes to 308 seconds on 4 CORE nodes.
AWS EMR cost calculations can be a bit challenging due to the way they are measured with normalized instance hours and when the clock starts ticking for cluster payment. A GitHub project is available to create approximate costs for resources over a given time period or when given a specific cluster-id. This project can be found on GitHub.
An estimate for the 28 million passenger scoring job with 4 CORE servers follows:
$ ./aws-emr-cost-calculator cluster --cluster_id=j-1D4QGJXOAAAAA
CORE.EC2 : 0.16
CORE.EMR : 0.04
MASTER.EC2 : 0.04
MASTER.EMR : 0.01
TOTAL : 0.25
Related code for this article can be found on DataRobot Community GitHub.