AWS Lambda reporting to MLOps¶
This topic describes a serverless method of reporting actuals data back to DataRobot once results are available for predicted items. Python 3.7 is used for the executable.
Architecture¶
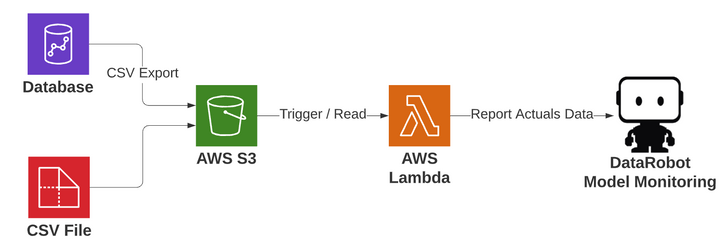
The process works as follows:
- CSV file(s) arrive at AWS S3 containing results to report back to DataRobot. These can be files created from any process. Examples above include a database writing results to S3 or a process sending a CSV file to S3.
- Upon arrival in the monitored directory, a serverless compute AWS Lambda function is triggered.
- The related deployment in DataRobot is specified in the S3 bucket path name to the CSV file, so the Lambda works generically for any deployment.
-
The Lambda parses out the deployment, reads through the CSV file, and reports results back to DataRobot for processing. You can then explore the results from various angles within the platform.
Create or use an existing S3 bucket¶
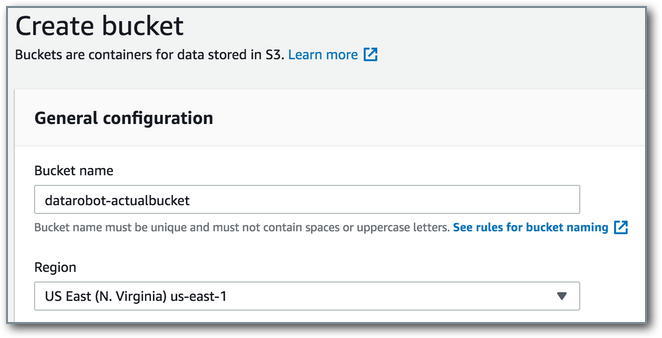
Actual CSV prediction results are written to a monitored area of an AWS S3 bucket. If one does not exist, create the new area to receive the results. Files are expected to be copied into this bucket from external sources such as servers, programs, or databases. To create a bucket, navigate to the S3 service within the AWS console and click Create bucket. Provide a name (like datarobot-actualbucket) and region for the bucket, then click Create bucket. Change the defaults if required for organizational policies.
Create an IAM Role for the Lambda¶
Navigate to Identity and Access Management (IAM). Under Roles, select Create role. Select AWS service and Lambda as a use case and then navigate to Next: Permissions. Search for and add the AWSLambdaBasicExecutionRole policy. Proceed with the next steps, provide the Role name lambda_upload_actuals_role. Complete the task by clicking Create role.
Two policies must be attached to this role:
- The AWS-managed policy, AWSLambdaBasicExecutionRole.
- An inline policy used for accessing and managing the S3 objects/files associated with this Lambda. Specify the inline policy for monitoring the S3 bucket as follows:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::datarobot-actualbucket",
"arn:aws:s3:::datarobot-actualbucket/*"
]
}
]
}
Create the Lambda¶
Navigate to the AWS Lambda service in the GUI console and from the dashboard, click Create function. Provide a name, such as lambda_upload_actuals. In the Runtime environment section, choose Python 3.7. Expand the execution role section, select Use an existing role, and choose the lambda_upload_actuals_role created above.
Add the Lambda trigger¶
This Lambda will run any time a CSV file lands in the path it is monitoring. From the Designer screen, choose +Add trigger, and select S3 from the dropdown list. For the bucket, choose the one specified in the IAM role policy you created above. (Optional) Specify a prefix if the bucket is used for other purposes. For example, use the value upload_actuals/ as a prefix if you want to only monitor objects that land in s3://datarobot-actualbucket/upload_actuals/.
(Note that the data for this example would be expected to arrive similar to s3://datarobot-actualbucket/upload_actuals/2f5e3433_DEPLOYMENT_ID_123/actuals.csv.) Click Add to save the trigger.
Create and add a Lambda layer¶
Lambda layers provide the opportunity to build Lambda code on top of libraries, and separate that code from the delivery package. Although not required to separate the libraries, using layers simplifies the process of bringing in necessary packages and maintaining code. This code will require the requests and pandas libraries, which are not part of the base Amazon Linux image Lambda runs in, and must be added via a layer. This can be done by creating a virtual environment. In this example, the environment used to execute the code below is an Amazon Linux EC2 box. (See the instructions to install Python 3 on Amazon Linux here.)
Creating a ZIP file for a layer can then be done as follows:
python3 -m venv my_app/env
source ~/my_app/env/bin/activate
pip install requests
pip install pandas
deactivate
Per the Amazon documentation, this must be placed in the python or site-packages directory and expanded under /opt.
cd ~/my_app/env
mkdir -p python/lib/python3.7/site-packages
cp -r lib/python3.7/site-packages/* python/lib/python3.7/site-packages/.
zip -r9 ~/layer.zip python
Copy the layer.zip file to a location on S3; this is required if the Lambda layer is larger than 10MB.
aws s3 cp layer.zip s3://datarobot-bucket/layers/layer.zip
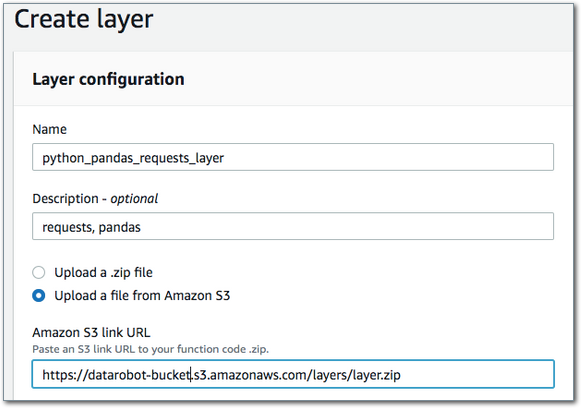
Navigate to Lambda service > Layers > Create Layer. Provide a name and link to the file in S3. Note that this will be the Object URL of the uploaded ZIP. It is recommended but not necessary to set compatible environments. This will make them more easily accessible in a dropdown menu when adding them to a Lambda. Select to save the layer and its ARN.
Navigate back to the Lambda and click Layers (below the Lambda title). Add a layer and provide the ARN from the previous step.
Define the Lambda code¶
import boto3
import os
import os.path
import urllib.parse
import pandas as pd
import requests
import json
# 10,000 maximum allowed payload
REPORT_ROWS = int(os.environ["REPORT_ROWS"])
DR_API_TOKEN = os.environ["DR_API_TOKEN"]
DR_INSTANCE = os.environ["DR_INSTANCE"]
s3 = boto3.resource("s3")
def report_rows(list_to_report, url, total):
print("reporting " + str(len(list_to_report)) + " records!")
df = pd.DataFrame(list_to_report)
# this must be provided as a string
df["associationId"] = df["associationId"].apply(str)
report_json = json.dumps({"data": df.to_dict("records")})
response = requests.post(
url,
data=report_json,
headers={
"Authorization": "Bearer " + DR_API_TOKEN,
"Content-Type": "application/json",
},
)
print("response status code: " + str(response.status_code))
if response.status_code == 202:
print("success! reported " + str(total) + " total records!")
else:
print("error reporting!")
print("response content: " + str(response.content))
def lambda_handler(event, context):
# get the object that triggered lambda
bucket = event["Records"][0]["s3"]["bucket"]["name"]
key = urllib.parse.unquote_plus(event["Records"][0]["s3"]["object"]["key"], encoding="utf-8")
filenm = os.path.basename(key)
fulldir = os.path.dirname(key)
deployment = os.path.basename(fulldir)
print("bucket is " + bucket)
print("key is " + key)
print("filenm is " + filenm)
print("fulldir is " + fulldir)
print("deployment is " + deployment)
url = DR_INSTANCE + "/api/v2/deployments/" + deployment + "/actuals/fromJSON/"
session = boto3.session.Session()
client = session.client("s3")
line_no = -1
total = 0
rows_list = []
for lines in client.get_object(Bucket=bucket, Key=key)["Body"].iter_lines():
# if the header, make sure the case sensitive required fields are present
if line_no == -1:
header = lines.decode("utf-8").split(",")
col1 = header[0]
col2 = header[1]
expectedHeaders = ["associationId", "actualValue"]
if col1 not in expectedHeaders or col2 not in expectedHeaders:
print("ERROR: data must be csv with 2 columns, headers case sensitive: associationId and actualValue")
break
else:
line_no = 0
else:
input_dict = {}
input_row = lines.decode("utf-8").split(",")
input_dict.update({col1: input_row[0]})
input_dict.update({col2: input_row[1]})
rows_list.append(input_dict)
line_no += 1
total += 1
if line_no == REPORT_ROWS:
report_rows(rows_list, url, total)
rows_list = []
line_no = 0
if line_no > 0:
report_rows(rows_list, url, total)
# delete the processed input
s3.Object(bucket, key).delete()
Set Lambda environment variables¶
Three variables need to be set for the Lambda.
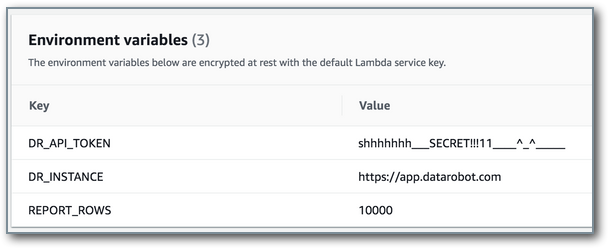
DR_API_TOKENis the API token of the account with access to the deployment, which will be used for submitting the actuals to the DataRobot environment. It is advised to use a service account for this configuration, rather than a personal user account.DR_INSTANCEis the application server of the DataRobot instance that is being used.REPORT_ROWSis the number of actuals records to upload in a payload; 10000 is the maximum.
Set Lambda resource settings¶
Edit the Basic settings to set configuration items for the Lambda. When reading input data to buffer and submit payloads, the Lambda uses a fairly low amount of local compute and memory. 512MB should be more than sufficient for memory settings, allocating half a vCPU accordingly. The Timeout is the amount of time allowed for the Lambda to not provide output, causing AWS to terminate it. This is most likely to happen when waiting for a response after submitting the payload. The default of 3 seconds is likely too short, especially when using the max size: 10,000-record payloads. Although 5-6 seconds is likely adequate, the configuration tested in this example was set to 30 seconds.
Run the Lambda¶
The Lambda is coded to expect a report-ready pair of data columns. It expects a CSV file with a header and case-sensitive columns associationId and actualValue. Sample file contents are shown below for a Titanic passenger scoring model.
associationId,actualValue
892,1
893,0
894,0
895,1
896,1
The following is an AWS CLI command to leverage the S3 service and copy a local file to the monitored directory:
aws s3 cp actuals.csv s3://datarobot-actualbucket/upload_actuals/deploy/ 5aa1a4e24eaaa003b4caa4 /actuals.csv
Note that the deployment ID is included as part of the path (shown above in red). This is the DataRobot deployment with which the actuals will be associated. Similarly, files from a process or database export can be written directly to S3.
Consider that the maximum length of time for a Lambda to run is 15 minutes. In the testing for this article, this length of time was sufficient for 1 million records. In production usage, you may want to explore approaches that include more files with fewer records. Also, you may want to report actuals for multiple deployments simultaneously. It may be prudent to disable API rate limiting for the associated API token/service account reporting these values.
Flesh out any additional error handling, such as sending an email, sending a queue data message, creating custom code to fit into an environment, moving the S3 file, etc. This Lambda deletes the input file upon successful processing and writes errors to the log in the event of failure.
Wrap-up¶
At this point, the Lambda is complete and ready to report any actuals data fed to it (i.e., the defined S3 location receives a file in the expected format). Set up a process to perform this operation once actual results arrive, then monitor and manage the model with DataRobot MLOps to understand how it’s performing for your use case.