DataRobot and Snowflake: Large batch scoring and object storage¶
With DataRobot's Batch Prediction API, you can construct jobs to mix and match source and target data sources with scored data destinations (JDBC databases and cloud object storage options such as AWS S3, Azure Blob, and Google GCS) across various local files . For examples of leveraging the Batch Prediction API via the UI, as well as raw HTTP endpoint requests to create batch scoring jobs, see:
- Server-side scoring with Snowflake
- Batch Prediction API documentation
- Python SDK library functions
The critical path in a scoring pipeline is typically the amount of resources available to actually run a deployed machine learning model. Although you can extract data from a database quickly, scoring throughput is limited to available scoring compute. Inserts to shredded columnar cloud databases (e.g., Snowflake, Synapse) are also most efficient when done with native object storage bulk load operations, such as COPY INTO when using a Snowflake Stage. An added benefit, particularly in Snowflake, is that warehouse billing can be limited to running just a bulk load vs. a continual set of JDBC inserts during a job. This reduces warehouse running time and thus warehouse compute costs. Snowflake and Synapse adapters can leverage bulk extract and load operations to object storage, as well as object storage scoring pipelines.
Snowflake adapter integration¶
The examples provided below leverage some of the credential management Batch Prediction API helper code presented in the server-side scoring example.
Rather than using the Python SDK (which may be preferred for simplicity), this section demonstrates how to use the raw API with minimal dependencies. As scoring datasets grow larger, the object storage approach described here can be expected to reduce both the end-to-end scoring time and the database write time.
Since the Snowflake adapter type leverages object storage as an intermediary, batch jobs require two sets of credentials: one for Snowflake and one for the storage layer, like S3. Also, similar to jobs, adapters can be mixed and matched.
Snowflake JDBC to DataRobot to S3 stage to Snowflake¶
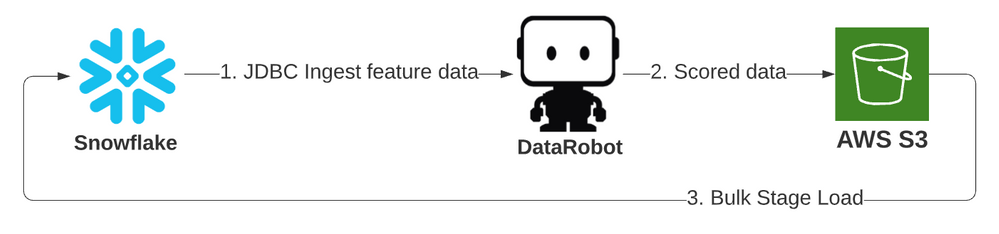
This first example leverages the prior existing JDBC adapter intake type as well as the Snowflake adapter output type, which uses the Snowflake stage object on bulk load. Only job details are specified below; see the full code on GitHub. The job explicitly provides all values, although many have defaults that could be used without specification. This survival model scores Titanic passengers by specifying input tables.
job_details = {
"deploymentId": DEPLOYMENT_ID,
"numConcurrent": 16,
"passthroughColumns": ["PASSENGERID"],
"includeProbabilities": True,
"predictionInstance" : {
"hostName": DR_PREDICTION_HOST,
"datarobotKey": DATAROBOT_KEY
},
"intakeSettings": {
"type": "jdbc",
"dataStoreId": data_connection_id,
"credentialId": snow_credentials_id,
"table": "PASSENGERS_6M",
"schema": "PUBLIC",
},
'outputSettings': {
"type": "snowflake",
"externalStage": "S3_SUPPORT",
"dataStoreId": data_connection_id,
"credentialId": snow_credentials_id,
"table": "PASSENGERS_SCORED_BATCH_API",
"schema": "PUBLIC",
"cloudStorageType": "s3",
"cloudStorageCredentialId": s3_credentials_id,
"statementType": "insert"
}
}
Snowflake to S3 stage to DataRobot to S3 stage to Snowflake¶
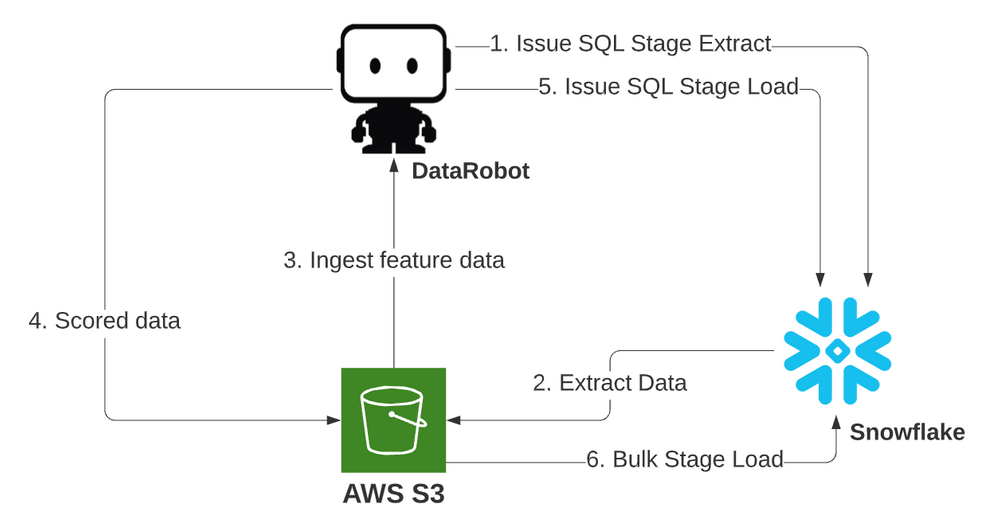
This second example uses the Snowflake adapter for both intake and output operations, with data dumped to an object stage, scored through an S3 pipeline, and loaded in bulk back from stage. This is the recommended flow for performance and cost.
- The stage pipeline (from S3 to S3) will keep a constant flow of scoring requests against Dedicated Prediction Engine (DPE) scoring resources and will fully saturate their compute.
- No matter how long the scoring component takes, the Snowflake compute resources only need to run for the duration of the initial extract and, once all data is scored, for a single final bulk load of the scored data. This maximizes the efficiency of the load, which is beneficial for the costs of running all Snowflake compute resources.
In this example, the job is similar to the first example. To illustrate the option, a SQL query is used as input rather than the source table name.
job_details = {
"deploymentId": DEPLOYMENT_ID,
"numConcurrent": 16,
"chunkSize": "dynamic",
"passthroughColumns": ["PASSENGERID"],
"includeProbabilities": True,
"predictionInstance" : {
"hostName": DR_PREDICTION_HOST,
"datarobotKey": DATAROBOT_KEY
},
"intakeSettings": {
"type": "snowflake",
"externalStage": "S3_SUPPORT",
"dataStoreId": data_connection_id,
"credentialId": snow_credentials_id,
"query": "select * from PASSENGERS_6m",
"cloudStorageType": "s3",
"cloudStorageCredentialId": s3_credentials_id
},
'outputSettings': {
"type": "snowflake",
"externalStage": "S3_SUPPORT",
"dataStoreId": data_connection_id,
"credentialId": snow_credentials_id,
"table": "PASSENGERS_SCORED_BATCH_API",
"schema": "PUBLIC",
"cloudStorageType": "s3",
"cloudStorageCredentialId": s3_credentials_id,
"statementType": "insert"
}
}
Code for this exercise is available in GitHub.
If running large scoring jobs with Snowflake or Azure Synapse, it's best to take advantage of the related adapter. Using one of these adapters for both intake and output ensures the scoring pipelines scale as data volumes increase in size.