スマートダウンサンプリング¶
スマートダウンサンプリングは、マジョリティークラスのサイズを減らすことで、合計データセットサイズを減少させる技法です。これにより、精度を犠牲にせずにモデルを短時間で構築できます。 スマートダウンサンプリングを有効にすると、すべての分析およびモデル構築は、ダウンサンプルデータ後の新しいデータセットサイズに基づいて行われます。
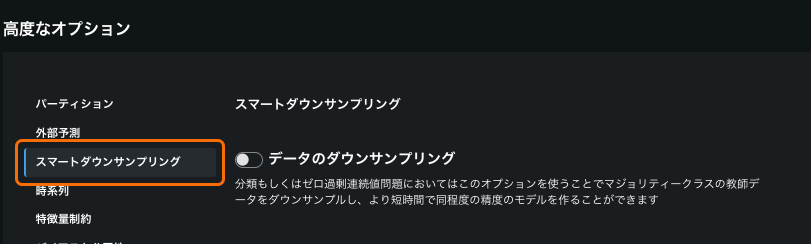
ダウンサンプリングの割合を設定するには、スマートダウンサンプリング後のマジョリティークラスのサイズを指定します。 たとえば、70%のスマートダウンサンプリングデータ率では、100行のマジョリティークラスが70行にダウンサンプルされます。
ダウンサンプリングを行うべき場合¶
スマートダウンサンプリングからメリットが得られる問題には2種類あります。
不均衡な分類:これは、2つのターゲットクラスのうち、片方のクラスがデータセットの中で他のクラスよりもはるかに頻繁に出現する問題です。 たとえば、ダイレクトメール応答データセットは、レコードの99.5%に対する負の応答と0.5%の正の応答で構成されている場合があります。
不均衡なデータでも大丈夫?
二値分類の問題ではデータのバランスを取る必要があるという俗説があり、多くのデータサイエンティストが誤ってデータを再サンプリングする原因となっています。 アップサンプリングはここで起こりうる最悪のミスですが、ダウンサンプリングでも問題を引き起こす可能性があります。 人間は不均衡なデータを理解するのに苦労しますが、コンピューターはそうではありません。 たとえば、定数値を予測するモデルの精度が99%であることは勘ではわかりませんが、不均衡によってデータが99%単一の値である場合は、これが発生します。
ほとんどの分類モデルは、クラスバランスの問題を自然に処理する LogLossで最適化されます。 ダウンサンプリングが適用される場合、マジョリティークラスのみに影響します。 ダウンサンプリングされると、DataRobotはデータを重み付けしてサンプリングを補正し、予測される確率が正しいことを確認します。
ダウンサンプリング(またはアップサンプリング)の必要がないのであれば、なぜDataRobotはそれを行うのでしょうか? ダウンサンプリングすることで、ほぼ同等の精度で、より高速なモデリングが可能になります。
ゼロ過剰の連続値:これは、データセットの50%以上に値ゼロが表示される問題です。 この一般的な例は保険金の請求データで、90%の契約では損失がゼロで、残りの10%の契約では様々な金額の保険金が請求されます。
両方のケースで、 DataRobotは、まずマジョリティークラスをダウンサンプリングしてクラスのバランスをとり、次に加重を追加して、結果として得られるデータセットの効果が元のクラスのバランスを模倣するようにします。 該当する最適化指標は、クラスが加重されていることを示します。
スマートダウンサンプリングの条件¶
スマートダウンサンプリングを使用する際は、以下の点に注意してください。
-
データセットは500MBを超えるものである必要があります。
-
ターゲット特徴量は2つの値(二値分類)だけを取るか、50%以上の値が正確にゼロである数値(ゼロブースト回帰)である必要があります。 時系列プロジェクトの場合、ゼロが多い時のモデリングでは、別の計算が使用されます。
-
ランダムパーティショニングは選択できません(スマートダウンサンプリングを有効にすると自動的に無効化されます)。
-
スマートダウンサンプリングが有効な場合、異常検知モデルは作成されません。
-
有効にすると、マジョリティークラスがマイノリティークラスよりも小さくなるようなダウンサンプリングの割合は選択できません。
これらの条件が満たされていない場合、この機能を有効にすることはできません。 スマートダウンサンプリングオプションでは、現在のターゲットが二値分類またはゼロブースト回帰問題ではないことを示すメッセージが表示されます。
分類(二値)を使用すると、マジョリティークラスがダウンサンプルされます。 連続値を使用すると、ゼロ値がダウンサンプルされます。 スマートダウンサンプリングは、次の両方の条件を満たす場合にデフォルトで選択されます。
- マジョリティークラスがマイノリティークラスの2倍以上である。
- データセットのサイズが500MBを超えている。
スマートダウンサンプリングの有効化¶
スマートダウンサンプリングを有効にして、データページの高度なオプションリンクからサンプリングパーセンテージを指定します。
-
データセットをインポートするか、モデルがまだ構築されていないプロジェクトを開いて、二値分類またはゼロブースト連続値問題になるターゲット特徴量を入力します。
-
高度なオプションを表示リンクをクリックして、スマートダウンサンプリングオプションを選択します。
-
データのダウンサンプリングをオンにします。

-
ボックスに入力するか、スライダーを使用して、マジョリティークラスのダウンサンプリングの割合を指定します。 以下の点に注意してください。
-
最小の割合の値は許容される最小の割合の値です。 表示されている最小値よりも小さい値を設定すると、マジョリティークラスがマイノリティークラスよりも小さい結果になります。
-
パーセンテージ率を変更すると、「ダウンサンプリングの結果…」の下に表示されているマジョリティー行が更新され、マジョリティークラスの新しいサイズが表示されます。
-
-
ページの一番上までスクロールし、モデリングモードを選択し、開始をクリックしてモデリングを開始します。
-
モデルのビルドが完了した後、ツールバーからモデルを選択します。 モデルの結果がダウンサンプリングに基づくことを示すアイコンがリーダーボードに表示されます。
-
そのアイコンをクリックして、ダウンサンプリング結果のレポートを表示します。
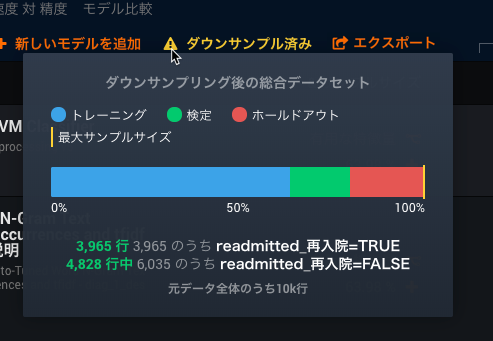
そのレポートで、マイノリティークラス(readmitted=true)はダウンサンプリングで変更されなかったことが確認できます。 マジョリティークラス(readmitted=false)は25%削減されています。 言い換えれば、維持されたマジョリティークラスのパーセンテージは75%です。