Covalent¶
プレミアム機能
Covalentのサポートは、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
DataRobotでは、オープンソースの分散コンピューティングプラットフォームであるCovalentを提供します。これは、複雑なAIおよび高性能コンピューティングアプリケーションを簡単に構築および拡張できるコードファーストのソリューションです。 ユーザーは、コンピューティングのニーズ(CPU、GPU、ストレージ、デプロイなど)をPythonコード内で直接定義できます。残りの処理はCovalentが行うため、複雑なサーバー管理やクラウド設定に煩わされることはありません。 Covalentは、高度なコンピューティングオーケストレーションと最適化により、エージェント型AIアプリケーションの開発を加速します。
DataRobotのユーザーであれば、Python環境(DataRobotのノートブックまたは独自の開発環境)でCovalent SDKにアクセスし、DataRobot APIキーを使用して、ファインチューニングやモデルの提供など、Covalentのすべての機能を利用できます。 Covalent SDKを使用すると、モデルのトレーニングやテストといった計算負荷の高いワークロードを、サーバーで管理されるワークフローとして実行できます。 ワークロードは、ワークフローに配置されたタスクに分割されます。 タスクとワークフローは、それぞれCovalentのelectronインターフェイスとlatticeインターフェイスで装飾されたPython関数です。
Covalentのすべてのドキュメントは、Covalentドキュメントサイトからアクセスできます。
Covalentのインターフェイス¶
Covalentが構築するタスクとワークフローは、それぞれCovalentのelectronインターフェイスとlatticeインターフェイスで装飾されたPython関数です。
Electron¶
Covalentにおける計算作業の最も単純な単位はelectronと呼ばれるタスクです。これは、Covalent APIで関数に@covalent.electronデコレーターを使用して作成されます。
オブジェクト指向のコードを説明する際には、クラスとオブジェクトを区別することが重要です。 このドキュメントで使用されている表記規則を以下に示します。
Electron (大文字の“E”)
Covalentエグゼキューターが実行できる計算タスクを表すCovalent APIクラス。
electron (小文字の“e”)****
Electronクラスをインスタンス化したオブジェクト。
@covalent.electron
デコレーターは次の目的で使用されます:
(1) 関数をelectronに変換する。
(2) 関数をelectronでラップする。
(3) 修飾された関数を含むElectronのインスタンスを生成する。
3つの説明はすべて同じです。
@covalent.electronデコレーターは、関数をCovalentエグゼキューターで実行可能にします。 他の方法で関数を変更することはありません。
@covalent.electronで修飾される関数には、任意のPython関数を指定できます。ただし、単一のタスクとして考え、操作する必要があります。 ベストプラクティスは、単一の明確な目的を持つelectronを書くことです。たとえば、ある入力に対して単一の変換を実行したり、ファイルやデータベースに対してレコードを書き込んだり読み出したりすることです。
2つの数字を足す簡単なelectronを以下に示します。
import covalent as ct
@ct.electron
def add(x, y):
return x + y
electronは構築ブロックであり、そこからlatticeを構成します。
Lattice¶
Covalentで実行可能なワークフローはlatticeと呼ばれ、@covalent.latticeデコレーターで作成されます。 electronと同様に、以下のような表記規則があります。
Lattice (大文字の“L”)
Covalentディスパッチャーが実行できるワークフローを表すCovalent APIクラス。
lattice (小文字の“l”)
Latticeクラスをインスタンス化したオブジェクト。
@covalent.lattice
Latticeクラスで関数をラップしてlatticeを作成するために使用されるデコレーター。 (electronについて述べた3つの類似の説明は、ここでも当てはまります。)
@covalent.latticeで修飾された関数には、1つ以上のelectronが含まれている必要があります。 latticeはワークフローであり、Pythonコードでインスタンス化された1つ以上のデータセットに対する一連の操作です。
Covalentが正しく動作するために、latticeはelectronを呼び出すことによってのみデータを操作する必要があります。 「適切に動作する」とは、「すべてのタスクをエグゼキューターにディスパッチする」ことを意味します。Covalentの柔軟性と能力は、タスク(electron)をエクゼキューターに割り当てたり、割り当て直したりできることにあります。これには、主にハードウェアの独立性と並列化という2つ利点があります。
ハードウェアの独立性¶
タスクのコードは、それが実行されるハードウェアの詳細から切り離されています。
並列化¶
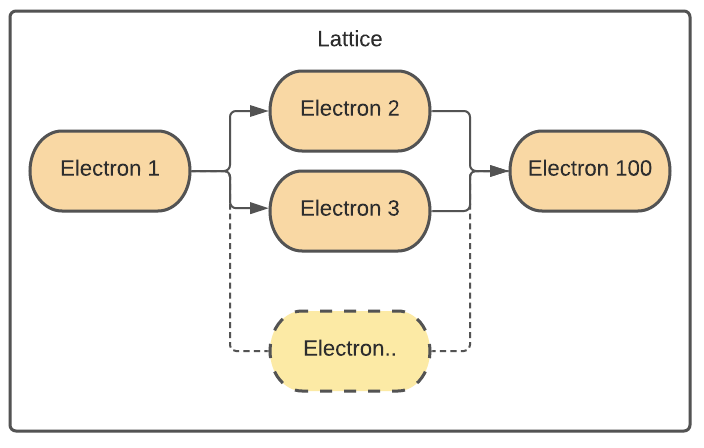
独立したタスクを同じバックエンドでも異なるバックエンドでも並列に実行できます。 ここでいう「独立」とは、2つのタスクの入力が、互いの実行結果(つまり出力や副作用)に影響されないことを意味します。 Covalentのディスパッチャーは、独立したelectronを並列に実行できます。 たとえば、以下に示すワークフロー構造では、electron 2とelectron 3が並列に実行されます。
使用例¶
関数からタスクを作成し、結果として得られたワークフローをディスパッチするコードスニペットを確認します。
import covalent as ct
import covalent_cloud as cc
import sklearn
import sklearn.svm
import yfinance as yf
from sklearn.model_selection import train_test_split
cc.create_env(
name="sklearn",
pip=["numpy==2.2.4", "pytz==2025.2", "scikit-learn==1.6.1", "yfinance==0.2.55"],
wait=True,
)
cpu_ex = cc.CloudExecutor(
env="sklearn",
num_cpus=2,
memory="8GB",
time_limit="2 hours"
)
# One-task workflow when stacking decorators:
@ct.lattice(executor=cpu_ex)
@ct.electron
def fit_svr_model_and_evaluate(ticker, n_chunks, C=1):
ticker_data = yf.download(ticker, start='2022-01-01', end='2023-01-01')
data = ticker_data.Close.to_numpy()
X = [data[i:i+n_chunks].squeeze() for i in range(len(data) - n_chunks)]
y = data[n_chunks:].squeeze()
# Split data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, shuffle=False)
# Fit SVR model
model = sklearn.svm.SVR(C=C).fit(X_train, y_train)
# Predict and calculate MSE
predictions = model.predict(X_test)
mse = sklearn.metrics.root_mean_squared_error(y_test, predictions)
return model, mse
# Run the one-task workflow
runid = cc.dispatch(fit_svr_model_and_evaluate)('AAPL', n_chunks=6, C=10)
model, mse = cc.get_result(runid, wait=True).result.load()
print(model, mse)