March 2024¶
March 27, 2024
This page provides announcements of newly released features available in DataRobot's SaaS single- and multi-tenant AI Platform, with links to additional resources. From the release center, you can also access:
In the spotlight¶
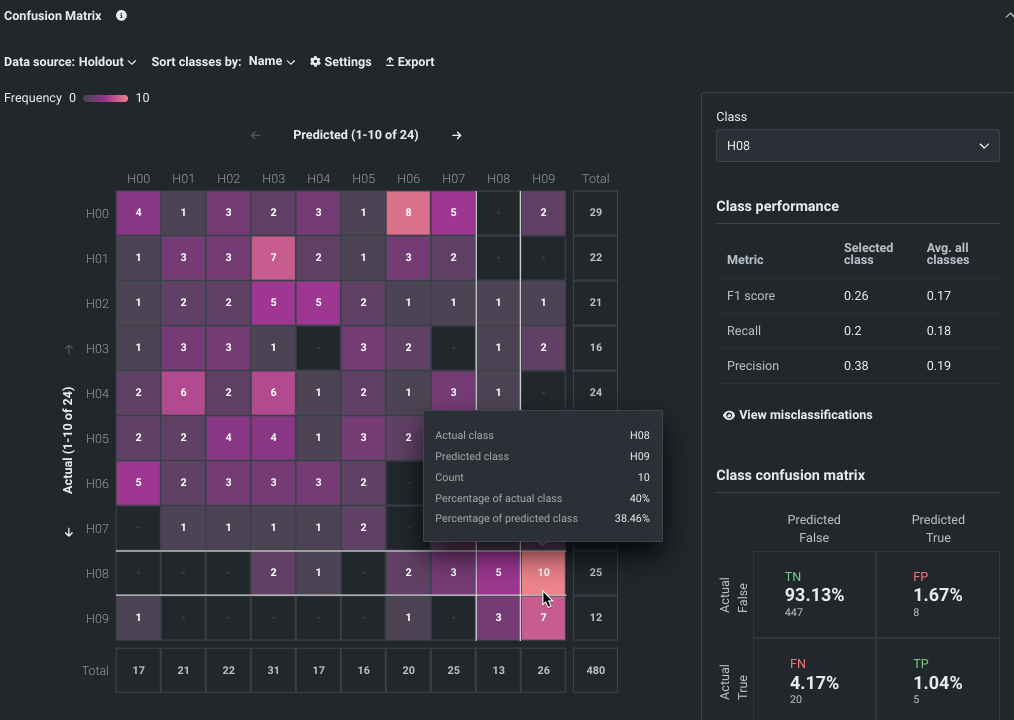
Multiclass modeling and confusion matrix¶
Multiclass experiments are now available in Workbench as a preview feature.
Video: Multiclass modeling
When building experiments, DataRobot determines the type based on the number of values for a given target feature. If more than two, the experiment is handled as either multiclass or regression (for numeric targets). Special handling by DataRobot allows:
- Changing a regression experiment to multiclass.
- Using aggregation, with configurable settings, to support more than 1000 classes.
Once a model is built, a multiclass confusion matrix helps to visualize where the model is, perhaps, mislabeling one class as another.
Preview documentation
Feature flag ON by default: Unlimited multiclass
March features¶
The following table lists each new feature:
Features grouped by capability
GA¶
Support for Parquet file ingestion¶
Ingestion of Parquet files is now GA for the AI Catalog, training datasets, and predictions datasets. The following Parquet file types are supported:
- Single Parquet files
- Single zipped Parquet files
- Multiple Parquet files (registered as separate datasets)
- Zipped multi-Parquet file (merged to create a single dataset in DataRobot)
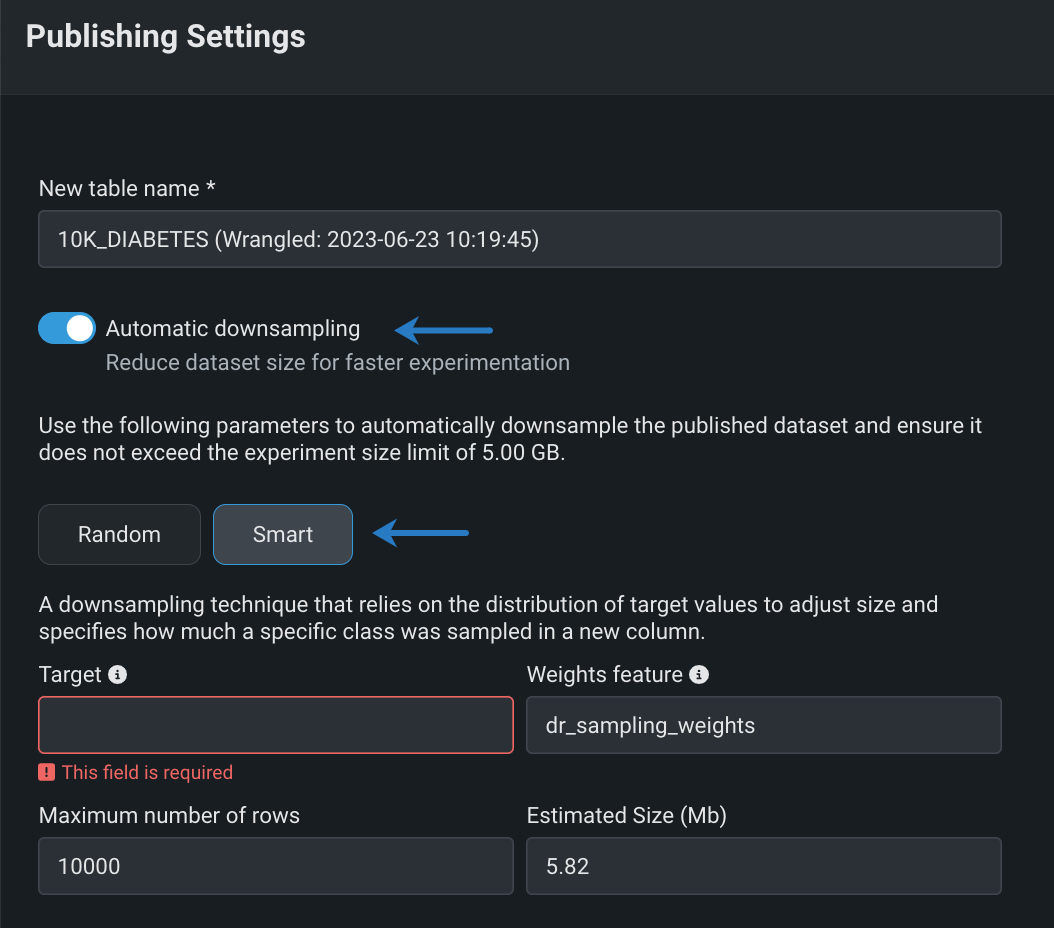
Publish wrangling recipes with smart downsampling¶
After building a wrangling recipe in Workbench, enable smart downsampling in the publishing settings to reduce the size of your output dataset and optimize model training. Smart downsampling is a data science technique that reduces the time it takes to fit a model without sacrificing accuracy, as well as account for class imbalance by stratifying the sample by class.
Uploading, modeling, and generating insights on 10GB for OTV experiments¶
To improve the scalability and user experience for OTV (out-of-time validation) experiments, this deployment introduces scaling for larger datasets. When using out-of-time validation as the partitioning method, DataRobot no longer needs to downsample for datasets as large as 10GB. Instead, a multistage Autopilot process supports the greatly expanded input allowance.
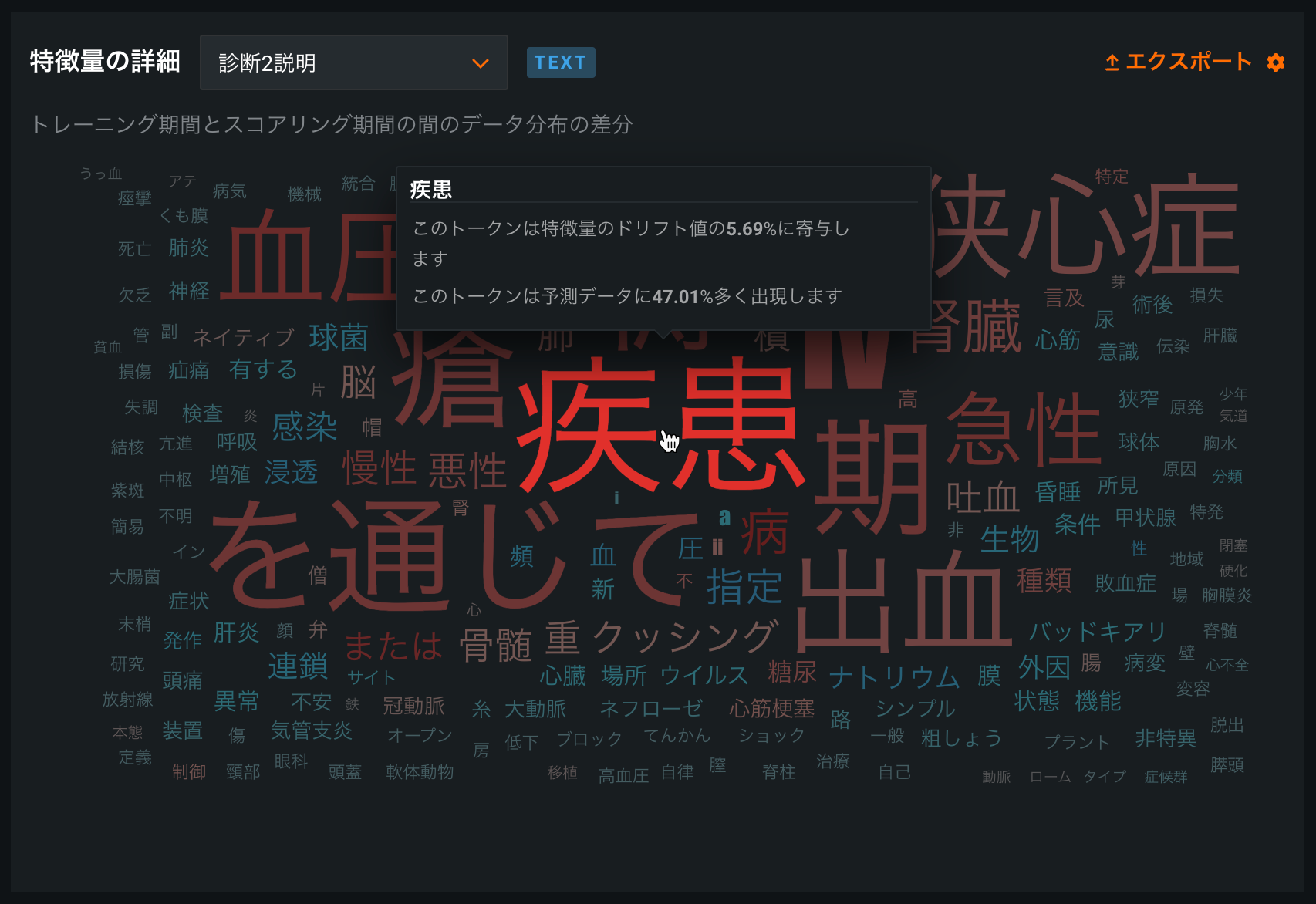
Tokenization improvements for Japanese text feature drift¶
Text tokenization for the Feature Details chart on the Data Drift tab is improved for Japanese text features, implementing word-gram-based data drift analysis with MeCab tokenization. In addition, default stop-word filtering is improved for Japanese text features.
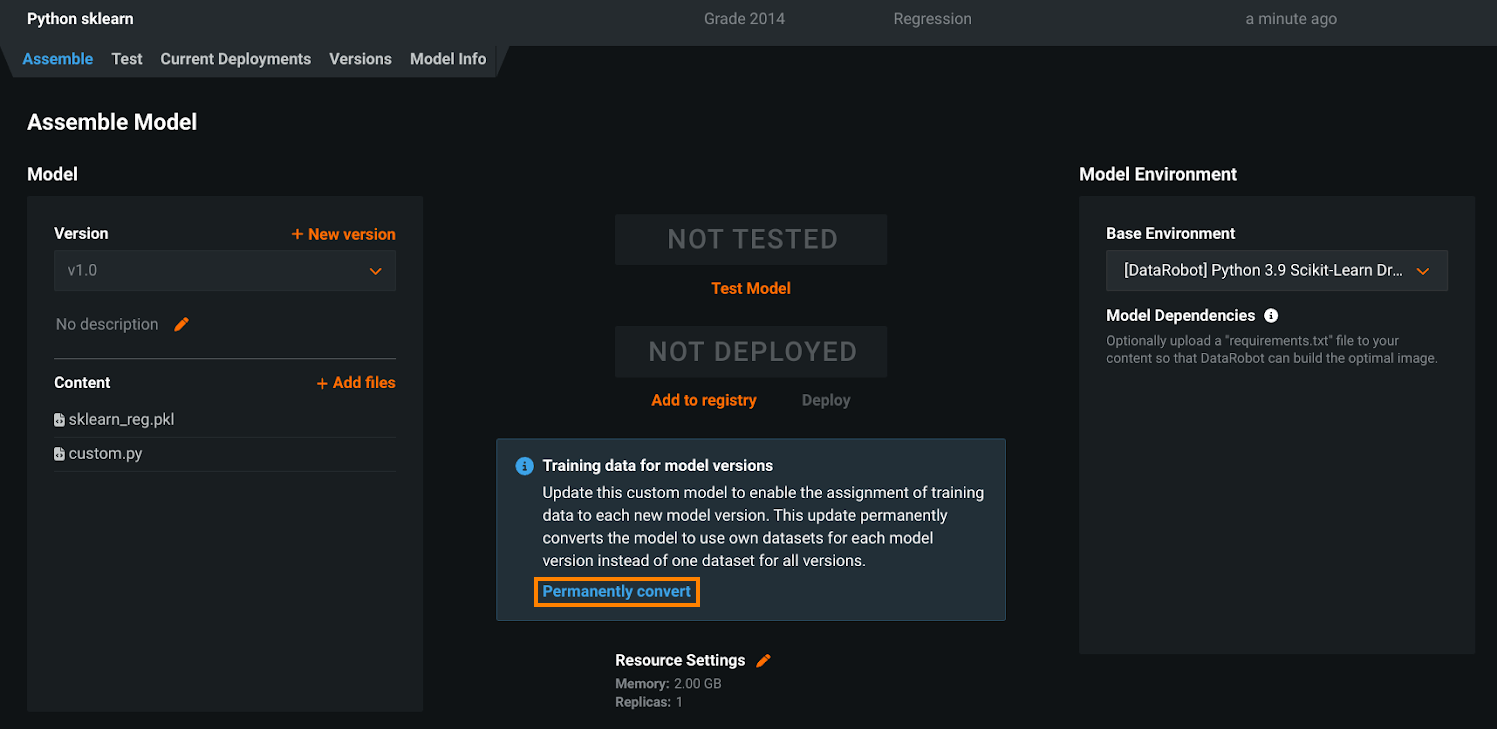
Custom model training data assignment update¶
In April 2024, the assignment of training data to a custom model version—announced in the March 2023 release—replaces the deprecated method of assigning training data at the custom model level. This means that the “per custom model version” method becomes the default, and the “per custom model” method is removed. In preparation, you can review the manual conversion instructions in the Add training data to a custom model documentation:
The automatic conversion of any remaining custom models using the “per custom model” method will occur automatically when the deprecation period ends, assigning the training data at the custom model version level. For most users, no action is required; however, if you have any remaining automation relying on unconverted custom models using the “per custom model” assignment method, you should update them to support the “per custom model version” method to avoid any gaps in functionality.
For a summary of the assignment method changes, you can view the Custom model training data assignment update documentation.
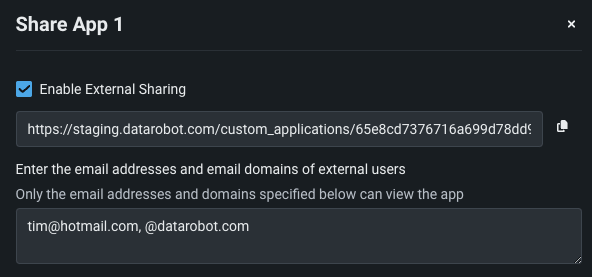
Share custom applications¶
You can share custom apps with both DataRobot and non-DataRobot users, expanding the reach of custom applications you create. Access sharing functionality from the actions menu in the Apps workshop. To share a custom app with non-DataRobot users, you must toggle on Enable external sharing and specify the email domains and addresses that are permitted access to the app. DataRobot provides a link to share with these users after configuring the sharing settings.
Manage notebook file systems with codespaces¶
Now generally available, DataRobot Workbench includes codespaces to enhance the code-first experience, especially when working with DataRobot Notebooks. A codespace, similar to a repository or folder file tree structure, can contain any number of files and nested folders. Within a codespace, you can open, view, and edit multiple notebook and non-notebook files at the same time. You can also execute multiple notebooks in the same container session (with each notebook running on its own kernel).
For Managed AI Platform users, DataRobot provides backup functionality and retention policies for codespaces. DataRobot takes snapshots of the codespace volume on session shutdown and on codespace deletion and will retain the contents for 30 days in the event you want to restore the codespace data.
Preview¶
Generative AI with NeMo Guardrails on NVIDIA GPUs¶
Use NVIDIA with DataRobot to quickly build out end-to-end generative AI (GenAI) capabilities by unlocking accelerated performance and leveraging the very best of open-source models and guardrails. The DataRobot integration with NVIDIA creates an inference software stack that provides full, end-to-end Generative AI capability, ensuring performance, governance, and safety through significant functionality out of the box.
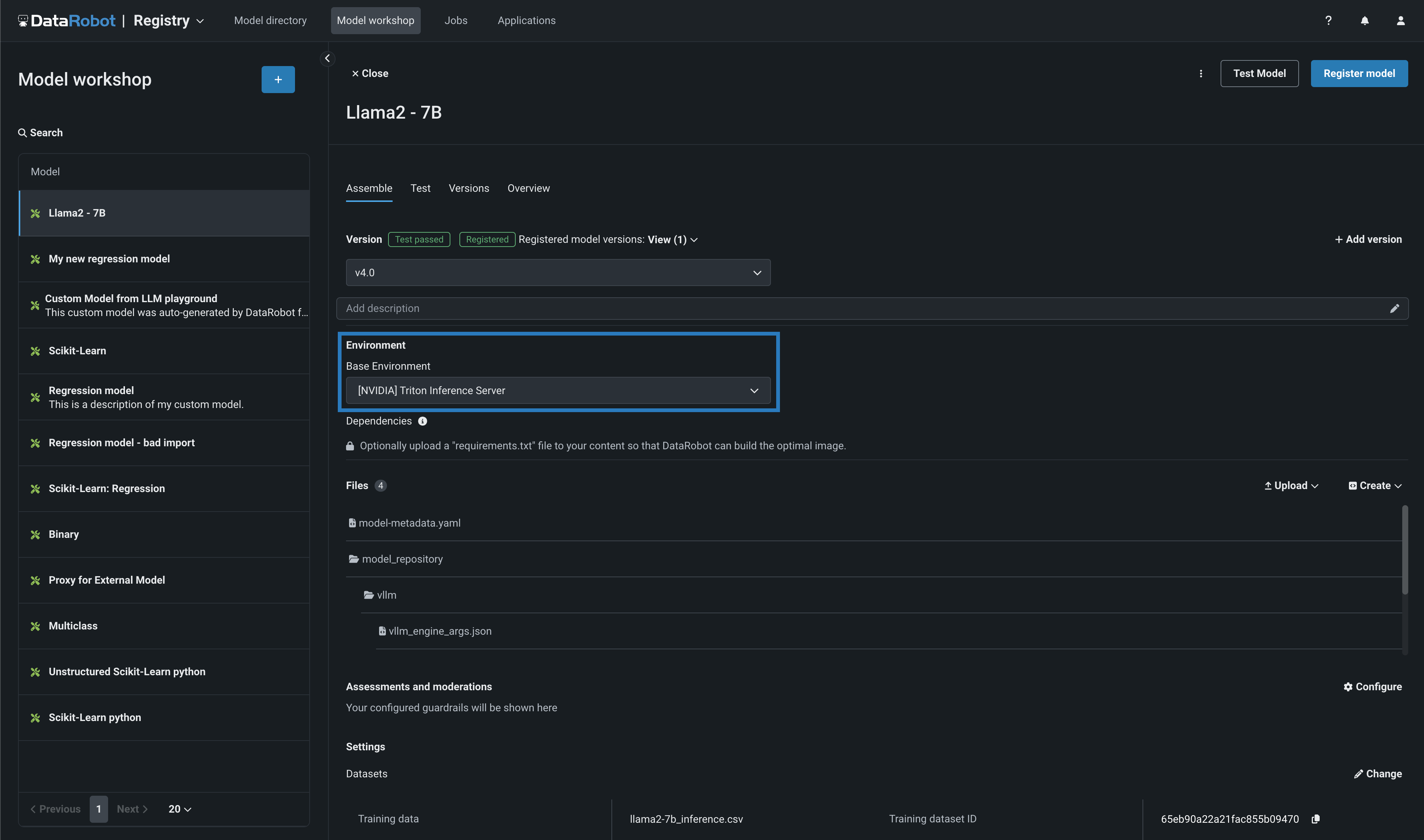
When you create a custom Generative AI model in the NextGen DataRobot Model workshop, you can select an [NVIDIA] Triton Inference Server (vLLM backend) base environment. DataRobot has natively built in the NVIDIA Triton Inference Server to provide extra acceleration for all of your GPU-based models as you build and deploy them onto NVIDIA devices.
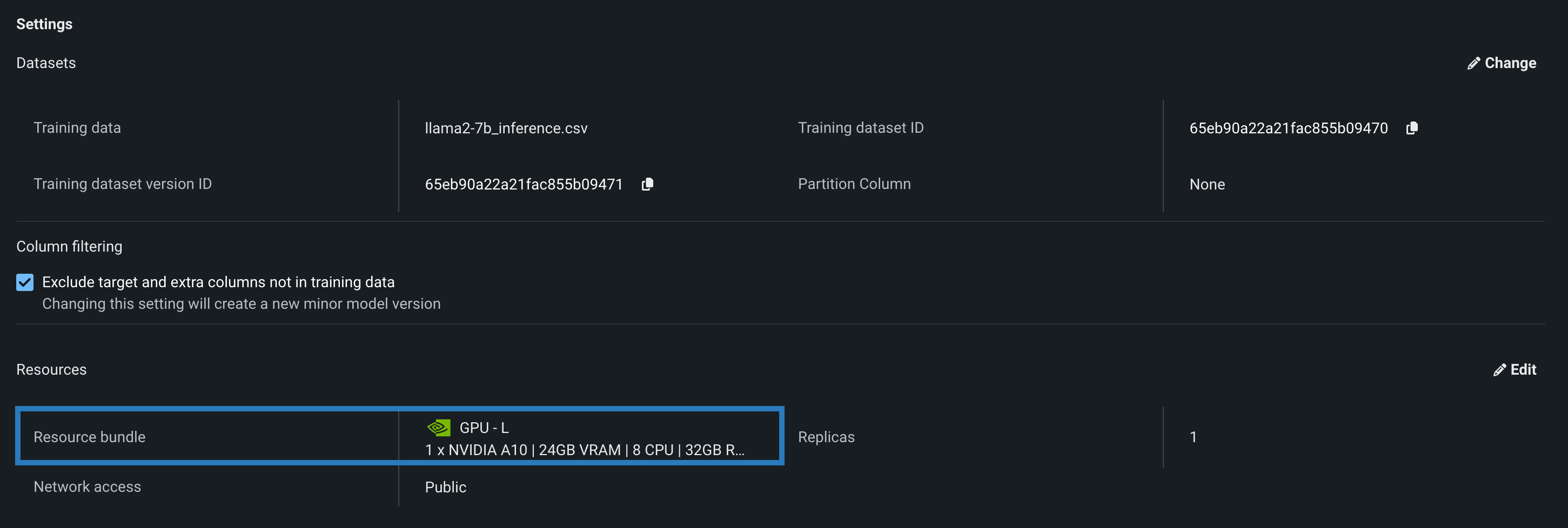
Then, navigating to the custom model's resources settings, you can select a resource bundle from the range of NVIDIA devices available as build environments in DataRobot.
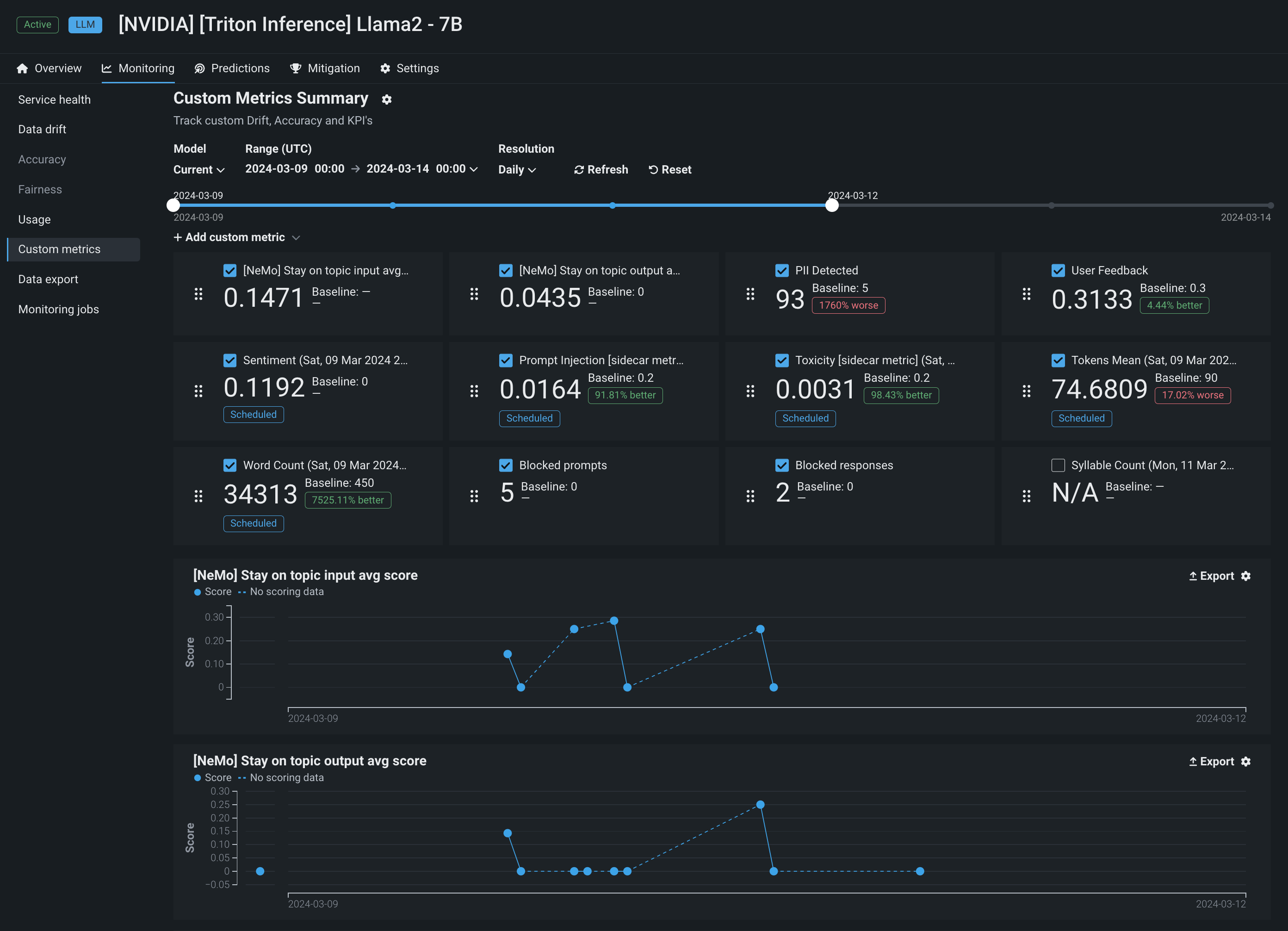
In addition, DataRobot also provides a powerful interface to create custom metrics through an integration with NeMo Guardrails. The integration with NeMo provides powerful rails to ensure your model stays on topic, using interventions to block prompts and completions if they violate the "on topic" principles provided by NeMo.
Preview documentation.
Feature flags OFF by default: The NVIDIA and NeMo Guardrails integrations require access to premium features for GenAI experimentation, LLM assessment, and GPU inference. Contact your DataRobot representative or administrator for information on enabling the required features.
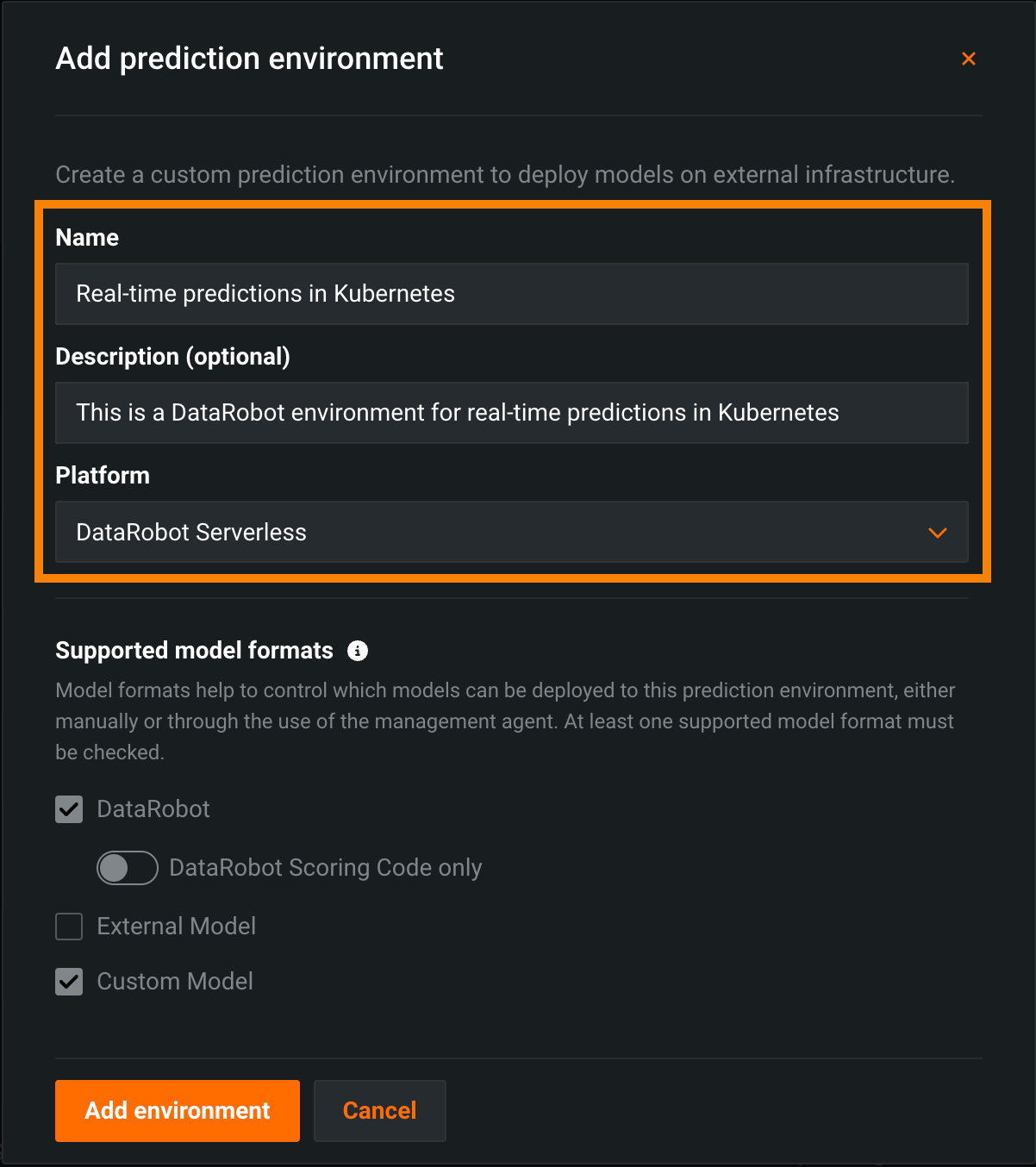
Real-time predictions on DataRobot serverless prediction environments¶
Create DataRobot serverless prediction environments to make scalable real-time predictions on Kubernetes, with configurable compute instance settings. To create a DataRobot serverless prediction environment for real-time predictions in Kubernetes, when you add a prediction environment, set the Platform to DataRobot Serverless:
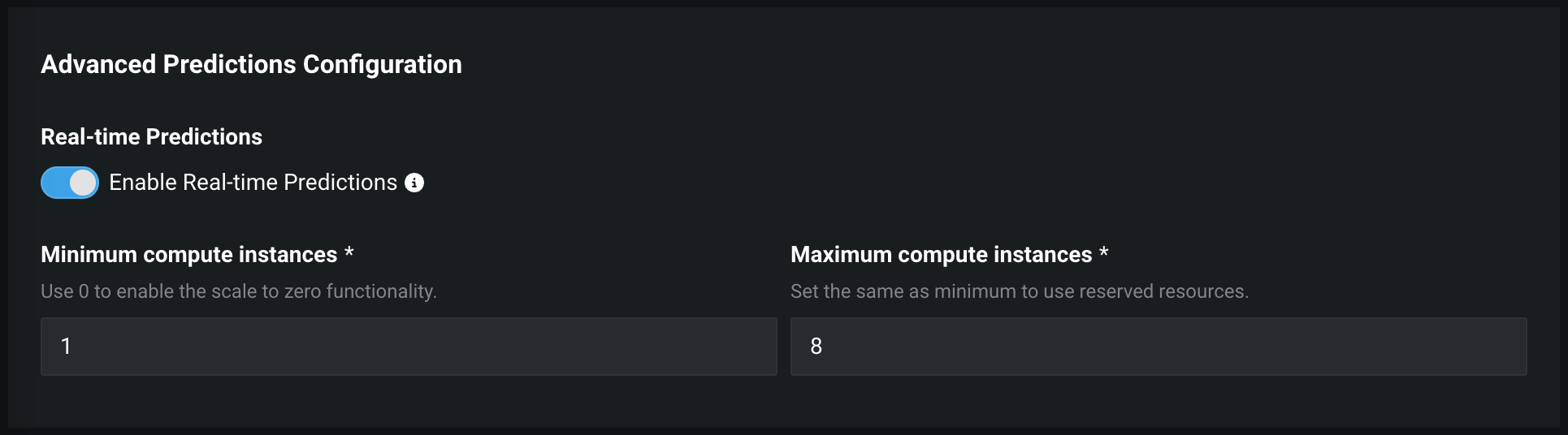
When you deploy a model to a DataRobot serverless prediction environment, you can configure the compute instance settings in Advanced Predictions Configuration:
Preview documentation.
Feature flag OFF by default: Enable Serverless Predictions on K8s
Create hosted custom metrics from custom jobs¶
When you create a new custom job in the Registry, you can create new hosted custom metrics or add metrics from the gallery. In the NextGen interface, click Registry > Jobs and then click + Add new (or the button when the custom job panel is open) to select one of the following custom metric types:
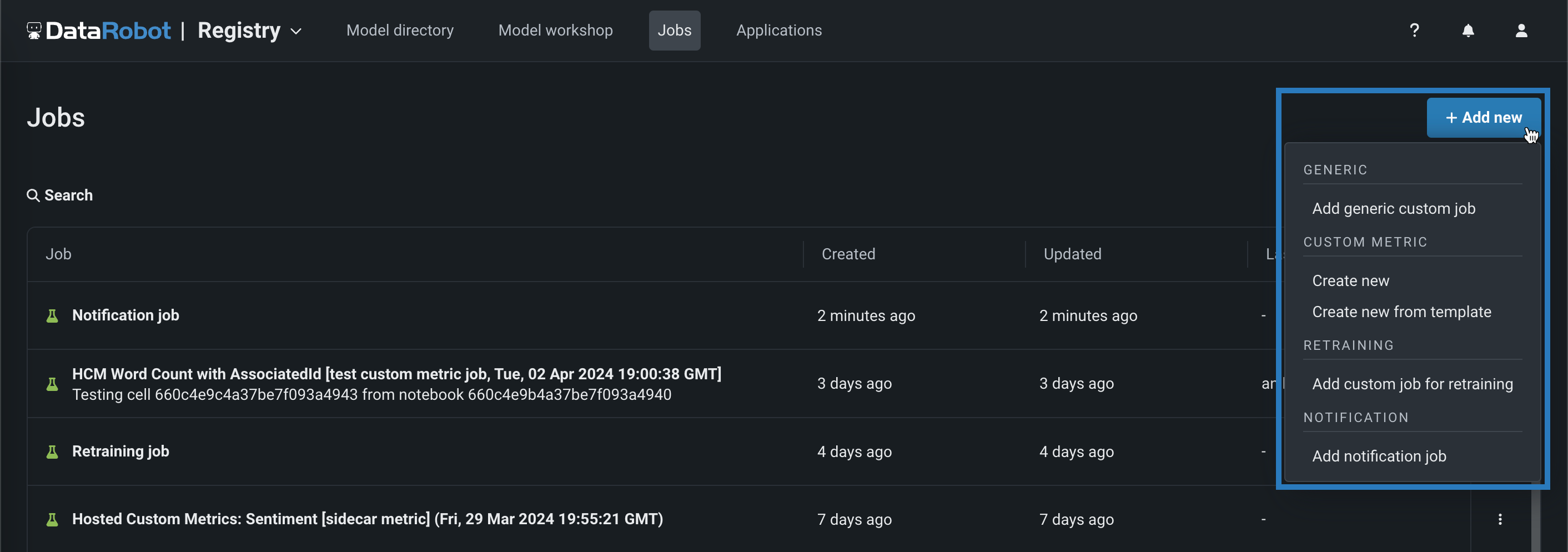
| Custom job type | Description |
|---|---|
| Add generic custom job | Add a custom job to implement automation (for example, custom tests) for models and deployments. |
| Create new | Add a custom job for a new hosted custom metric, defining the custom metric settings and associating the metric with a deployment. |
| Create new from template | Add a custom job for a custom metric from a template provided by DataRobot, associating the metric with a deployment and setting a baseline. |
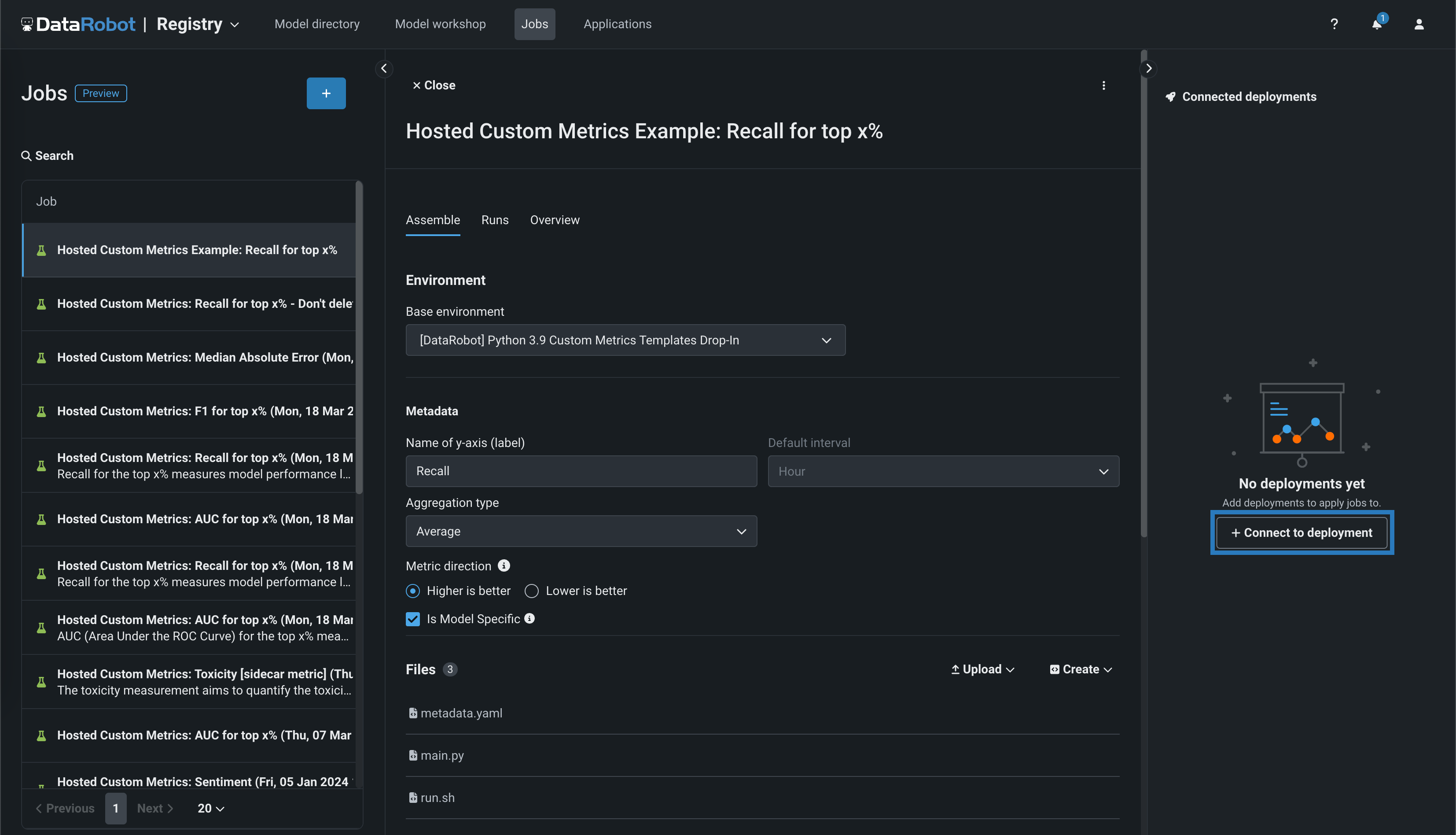
After you create a custom metric job on the Registry > Jobs tab, on the custom metric job's Assemble tab, you can access the Connected deployments panel. Click + Connect to deployment, define a custom metric name, and then select a deployment ID to link the metric to a deployment:
Preview documentation.
Feature flags OFF by default: Enable Hosted Custom Metrics, Enable Notebooks Custom Environments
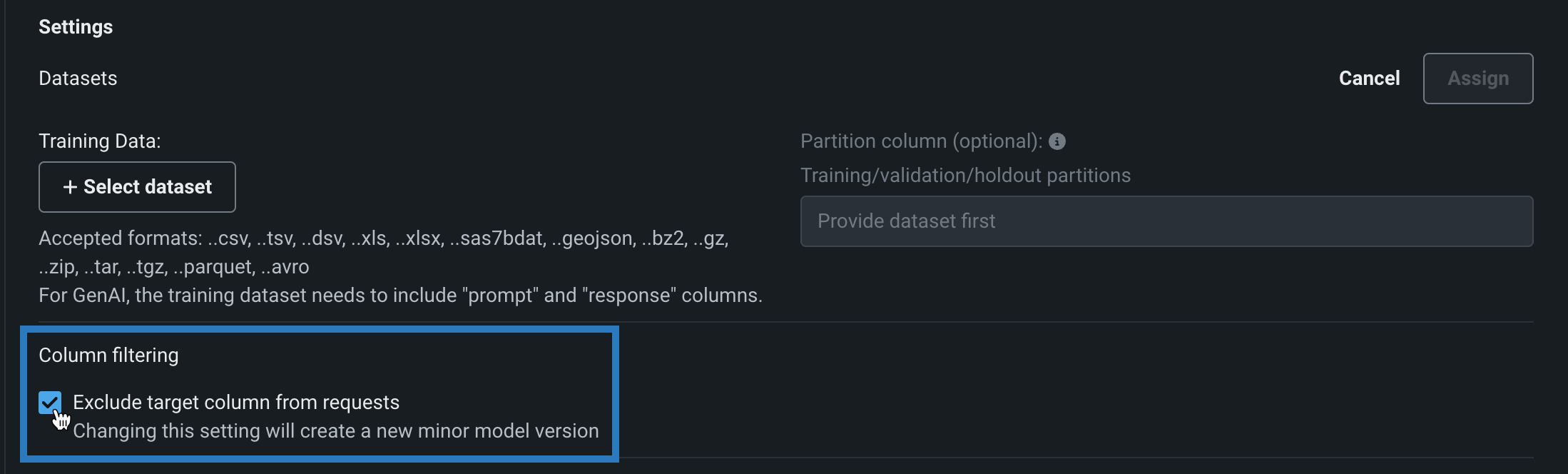
Disable column filtering for prediction requests¶
When you assemble a custom model, you can enable or disable column filtering for custom model predictions. The filtering setting you select is applied in the same way during custom model testing and deployment. By default, the target column is filtered out of prediction requests and, if training data is assigned, any additional columns not present in the training dataset are filtered out of any scoring requests sent to the model. Alternatively, if the prediction dataset is missing columns, an error message appears to notify you of the missing features.
You can disable this column filtering when you assemble a custom model. In the Model workshop, open a custom model to the Assemble tab, and, in the Settings section, under Column filtering, clear Exclude target column from requests (or, if training data is assigned, clear Exclude target and extra columns not in training data):
Preview documentation.
Feature flag OFF by default: Enable Feature Filtering for Custom Model Predictions
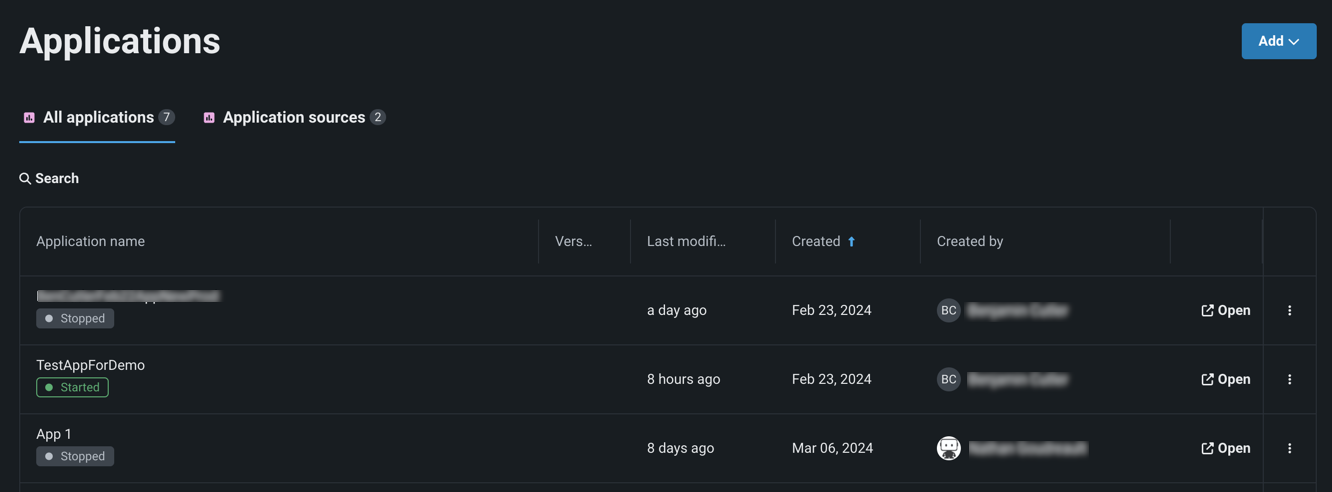
Manage custom applications in the Registry¶
Now available for preview, the Applications page in the NextGen Registry is home to all built custom applications and application sources available to you. You can now create application sources, which contain the files, environment, and runtime parameters for custom applications you want to build. You can now build custom applications directly from these sources. You can also use the Applications page to manage applications by sharing or deleting them.
Preview documentation.
Feature flag OFF by default: Enable Custom Applications Workshop
API¶
New import path for the datarobot-mlops package¶
In the datarobot-mlops and datarobot-mlops-connected-client Python packages, the import path is changing from import datarobot.mlops.mlops to import datarobot_mlops.mlops. This fixes an issue where the DataRobot package and the MLOps packages conflict with each other when installed to the same Python environment. You must manually update this import. The example below shows how you can update your code to be compatible by attempting both import paths:
try:
from datarobot_mlops.mlops import MLOps
except ImportError:
from datarobot.mlops.mlops import MLOps
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.