July 2024¶
July 24, 2024
This page provides announcements of newly released features available in DataRobot's SaaS single- and multi-tenant AI Platform, with links to additional resources. From the release center, you can also access:
In the spotlight: Feature Discovery in Workbench¶
Perform Feature Discovery in Workbench¶
Perform Feature Discovery in Workbench to discover and generate new features from multiple datasets. You can initiate Feature Discovery in two places:
- The Data tab, to the right of the dataset that will serve as the primary dataset, click the Actions menu > Feature Discovery.
- The data explore page of a specific dataset, click Data actions > Start feature discovery.
On this page, you can add secondary datasets and configure relationships between the datasets.
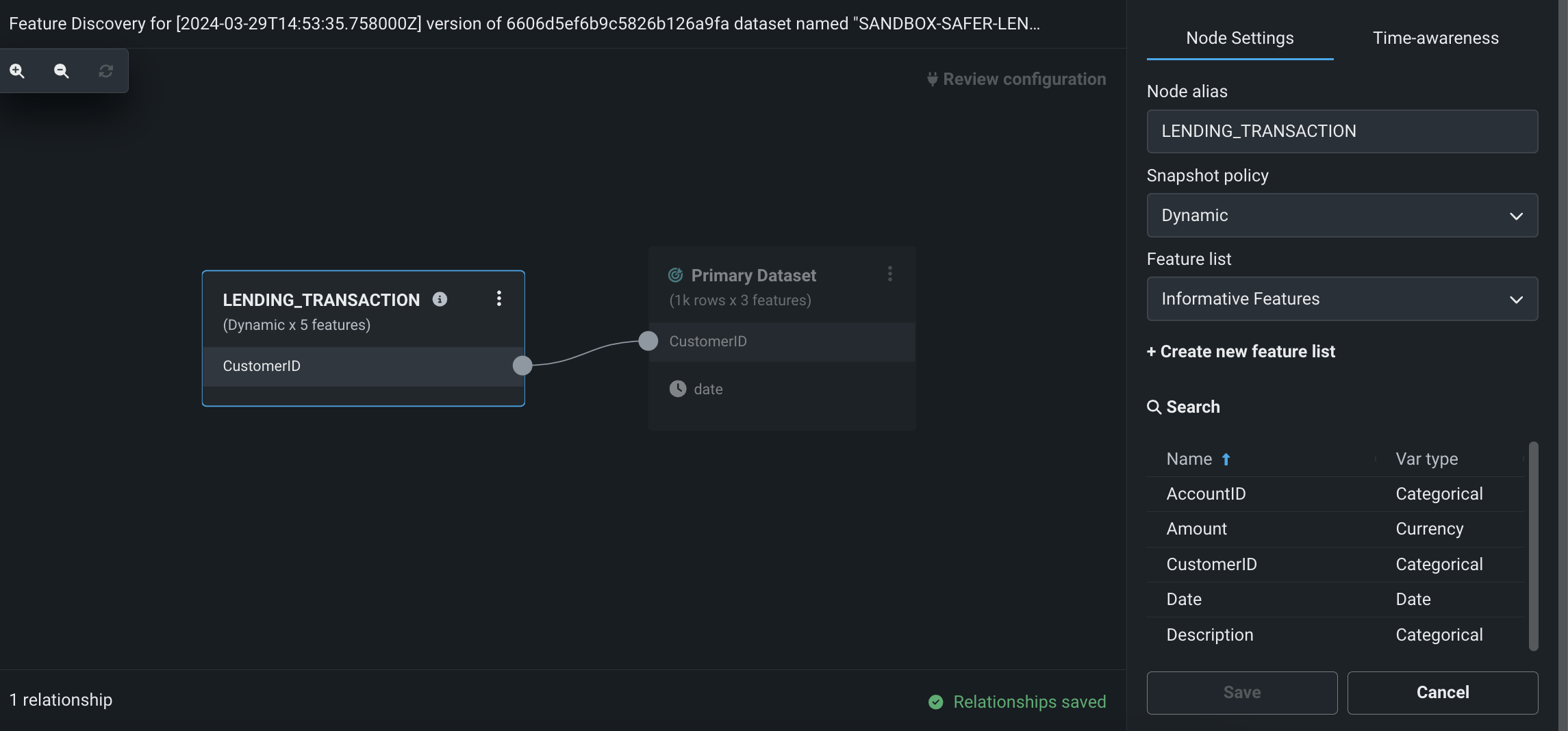
After configuring Feature Discovery and completing an automated relationship assessment, you can immediately proceed to experiment set up and modeling. As part of model building, DataRobot uses this recipe to perform joins and aggregations, generating a new output dataset that is then registered in the Data Registry and added to your current Use Case.
July features¶
The following table lists each new feature:
Features grouped by capability
* Premium feature
GA¶
New LLMs available from the playground¶
With this deployment, several new large language models (LLMs) are available from the playground, expanding the offerings of out-of-the-box LLMs you can choose to build your generative AI experiments. The addition of these LLMs is an indicator of DataRobot’s commitment to delivering newly released LLMs as they are made available. The new options include:
- Anthropic Claude 3 Haiku
- Anthropic Claude 3 Sonnet
- Google Gemini 1.5 Flash
- Google Gemini 1.5 Pro
A list of available LLMs is maintained here.
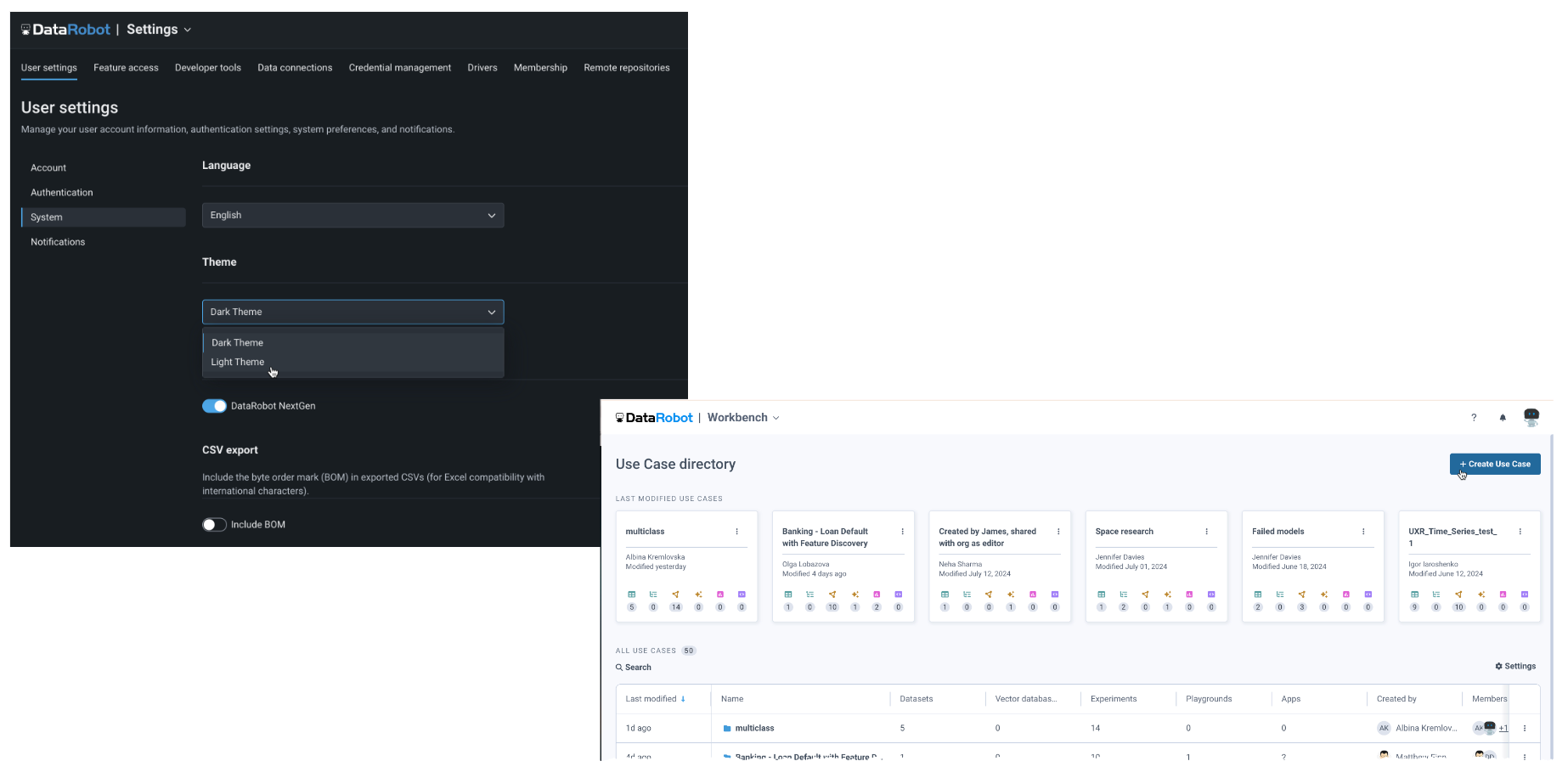
Light theme now available for application display¶
You can now change the display theme of the DataRobot application, which displays in the dark theme by default. To change the color of the display, from your profile avatar in the upper-right corner, navigate to User Settings > System and use the Themes dropdown:
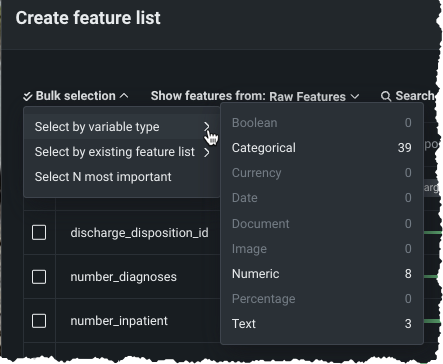
Data tab and custom feature list functionality now GA¶
The ability to add new, custom feature lists to an existing predictive or forecasting experiment through the UI was introduced in April as a preview feature. Now generally available, you can create your own lists from the Feature Lists or Data tabs (also both now GA) in the Experiment information window accessed from the Leaderboard. Use bulk selections to choose multiple features with a single click:
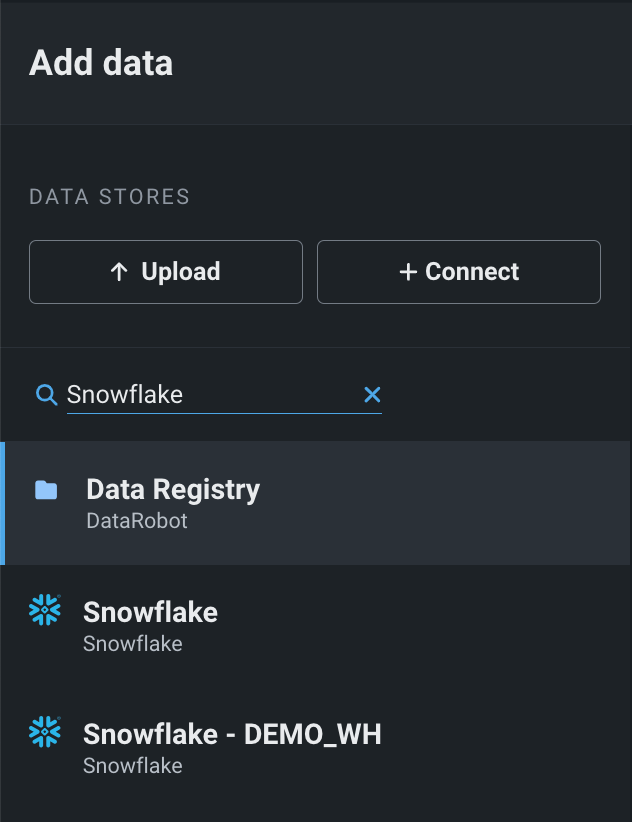
Search for data connections in the Add Data modal¶
You can search for specific data connections in the Add Data modal of Workbench instead of scrolling through the list of all existing connections.
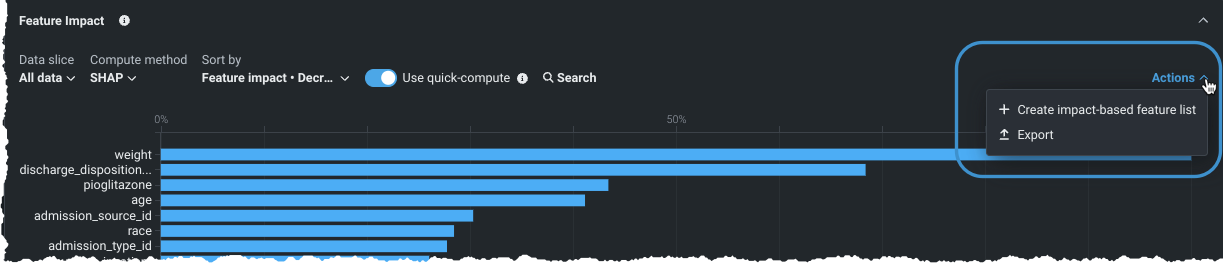
Create custom feature lists from Feature Impact¶
You can now create feature lists based on the relative impact of features from the Feature Impact insight, accessed from the Model Overview. Using the same familiar interface as the other feature list creation options in NextGen, any lists created in Feature Impact are available for use across the experiment.
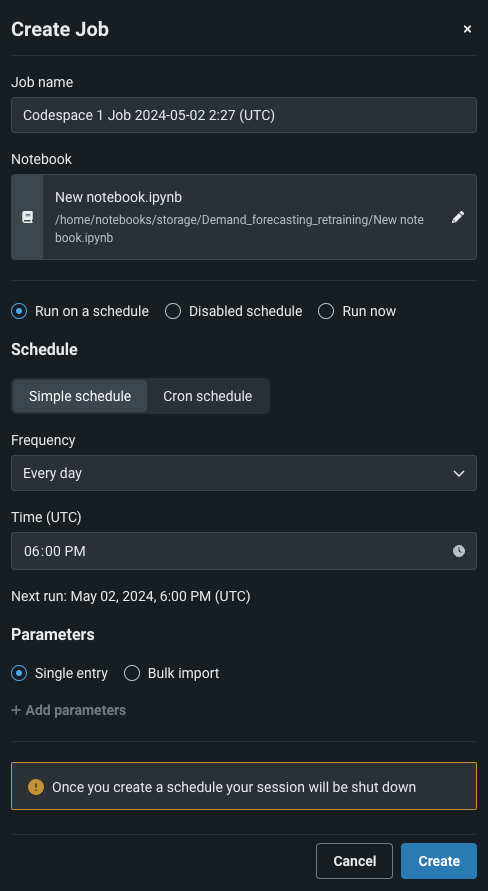
Create schedules for codespaces¶
Now generally available, you can automate your code-based workflows by scheduling notebooks in codespaces to run on a schedule in non-interactive mode. Scheduling is managed by notebook jobs, and you can only create a new notebook job when your codespace is offline. You can also parameterize a notebook to enhance the automation experience enabled by notebook scheduling. By defining certain values in a codespace as parameters, you can provide inputs for those parameters when a notebook job runs instead of having to continuously modify the notebook itself to change the values for each run.
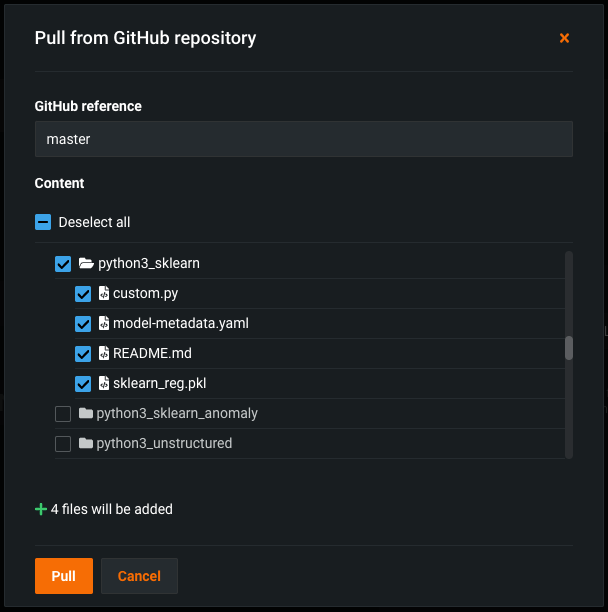
Remote repository file browser for custom models and tasks¶
With this release, while adding a model or task to the Custom Model Workshop in DataRobot Classic, you can browse and select folders and files in a remote repository, such as Bitbucket, GitHub, GitHub Enterprise, S3, GitLab, and GitLab Enterprise. When you pull from a remote repository, you can select the checkbox for any files or folders you want to pull into the custom model, or, you can select every file in the repository.
Note
This example uses GitHub; however, the process is the same for each repository type.
Preview¶
Perform wrangling on Data Registry datasets¶
You can now build wrangling recipes and perform pushdown on datasets stored in the Data Registry. To wrangle Data Registry datasets, you must first add the dataset to your Use Case. Then, begin wrangling from the Actions menu next to the dataset.
This feature is only available for multi-tenant SaaS users and installations with AWS VPC or Google VPC environments.
Preview documentation.
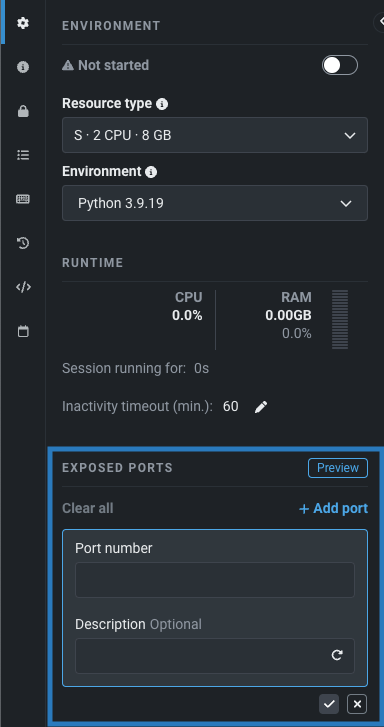
Enable port forwarding to access web applications in notebooks and codespaces¶
In the environment settings for notebooks and codespaces, you can now enable port forwarding to access web applications launched by tools and libraries like MLflow and Streamlit. When developing locally, the web application is accessible at http://localhost:PORT; however, when developing in a hosted DataRobot environment, the port that the web application is running on (in the session container) must be forwarded to access the application.
Preview documentation.
Feature flag ON by default: Enables Session Port Forwarding
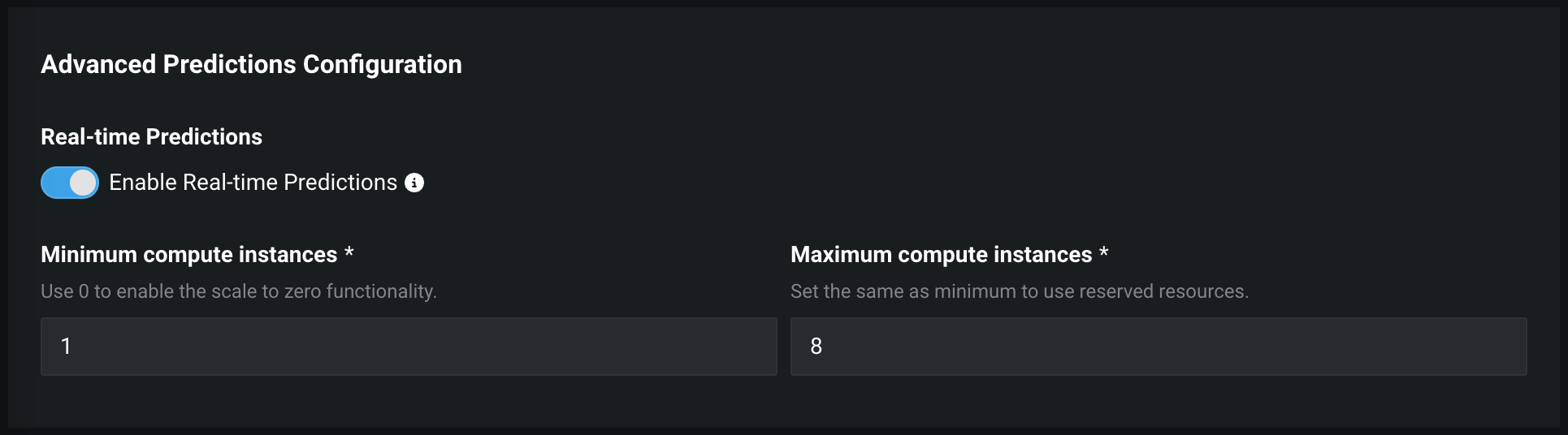
Configure minimum compute instances for serverless predictions¶
Now available as a premium feature, when creating a DataRobot Serverless prediction environment, you can increase the minimum compute instances setting from the default of 0. This setting accepts a number from 0 to 8. If the minimum compute instances setting is set to 0 (the default), the inference server is stopped after an inactivity period of 30 minutes or more.
Preview documentation.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.