April 2024¶
April 24, 2024
This page provides announcements of newly released features available in DataRobot's SaaS single- and multi-tenant AI Platform, with links to additional resources. From the release center, you can also access:
In the spotlight¶
Vector database and LLM playground functionality now generally available¶
With the April, 2024 deployment, DataRobot makes the generative AI (GenAI) vector database and LLM playground functionality generally available. A premium feature, GenAI was originally introduced in November, 2023 with the ability to create vector databases, compare models in the playground, and deploy LLM blueprints. The GA version of the vector database builder and LLM playground—with improved navigation—unblocks users from getting data into the DataRobot GenAI flow and models into production. Some of the many enhancements include:
-
More chatting flexibility with LLMs, including controlling how chat context is used while prompting the LLM.
-
The addition of “chats” in the playground to organize and separate conversations with LLMs.
-
Sharing functionality to easily share your playground and gather feedback; take that feedback to an AI accelerator, fine-tune in GCP or AWS, and bring that model back into DataRobot.
-
Configuration and application of evaluation and moderation assessment metrics.
-
Tracing logs to view all components and prompting activity used in generating LLM responses.
-
Citations report to better understand which documents were retrieved by an LLM when prompting a vector database.
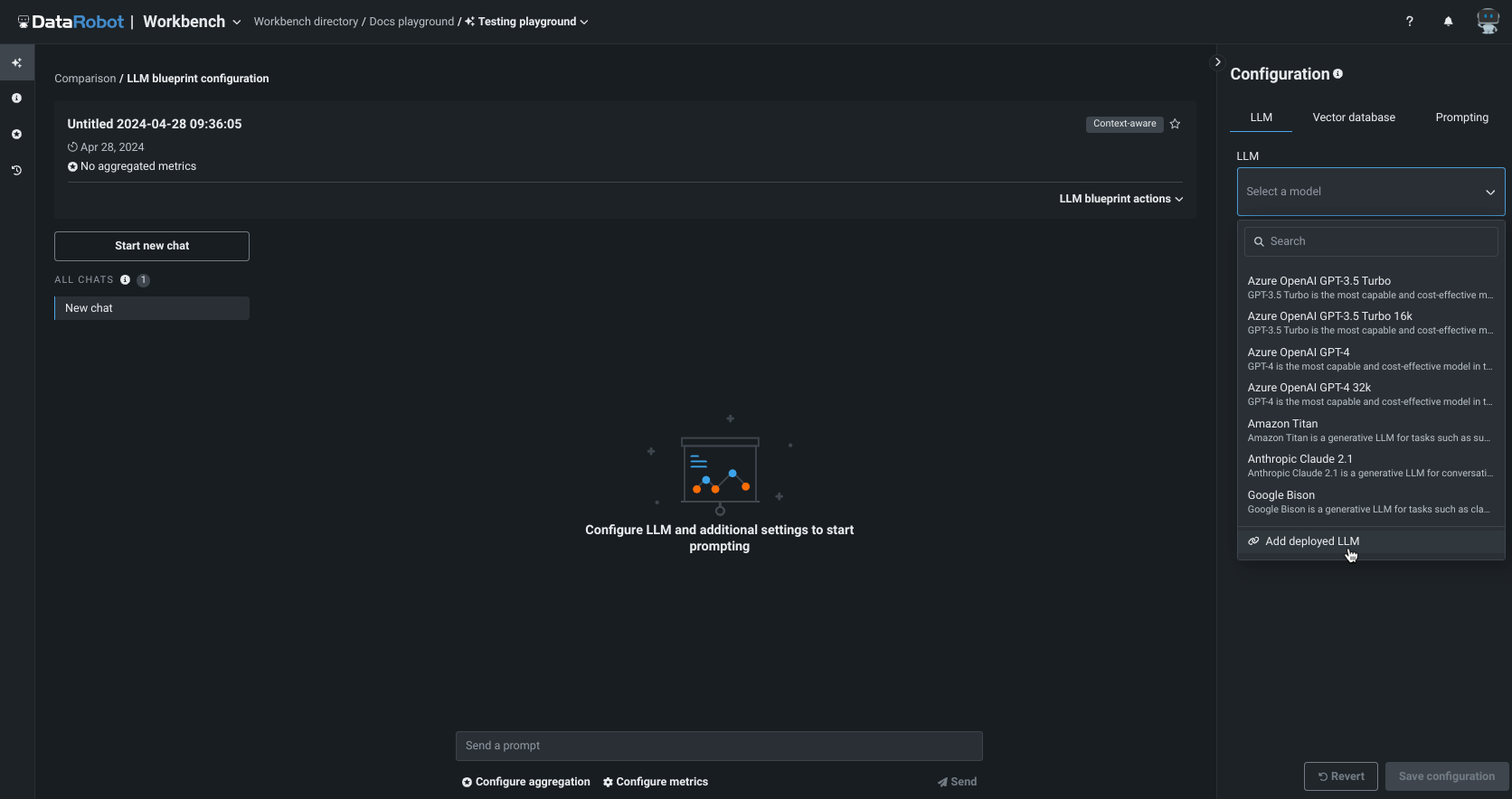
Updated layout for the NextGen Console¶
This update to the NextGen Console provides important monitoring, predictions, and mitigation features in a modern user interface with a new and intuitive layout.
Video: NextGen Console
This updated layout provides a seamless transition from model experimentation in Workbench and registration in Registry, to model monitoring and management in Console—while maintaining the features and functionality available in DataRobot Classic.
For more information, see the documentation.
April features¶
The following table lists each new feature:
Features grouped by capability
* Premium feature
GA¶
NVIDIA RAPIDS GPU-accelerated libraries now available¶
This deployment introduces NVIDIA RAPIDS-powered notebooks, which allow creating GPU powered workflows for data prep and modeling needs. RAPIDS is a suite of GPU-accelerated data science and AI libraries with APIs that match popular open-source data tools.
Single-tenant SaaS¶
DataRobot has released a single-tenant SaaS solution, featuring a public internet access networking option. With this enhancement, you can seamlessly leverage DataRobot's AI capabilities while securely connecting across the web, unlocking unprecedented flexibility and scalability.
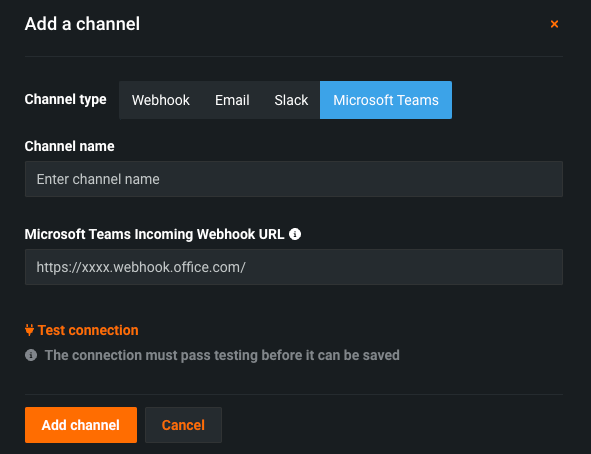
Add a Microsoft Teams notification channel¶
Admins can now configure a notification channel for Microsoft Teams. Notification channels are mechanisms for delivering notifications created by admins. You may want to set up several channels for each type of notification; for example, a webhook with a URL for deployment-related events, and a webhook for all project-related events.
Build and use a chat generation Q&A application¶
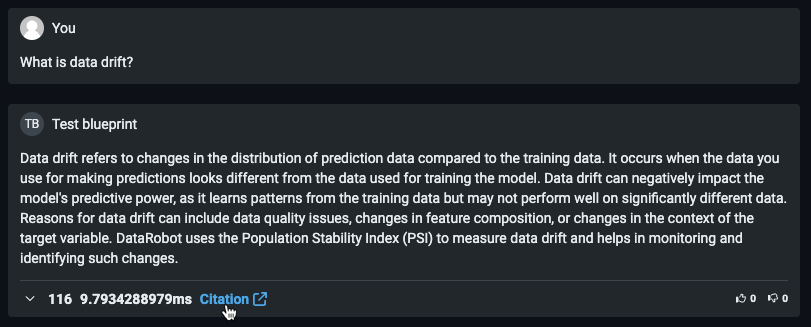
Now available as a premium feature, you can create a chat generation Q&A application with DataRobot to explore knowledge base Q&A use cases while leveraging Generative AI to repeatedly make business decisions and showcase business value. The Q&A app offers an intuitive and responsive way to prototype, explore, and share the results of LLM models you've built. The Q&A app powers generative AI conversations backed by citations. Additionally, you can share the app with non-DataRobot users to expand its usability.
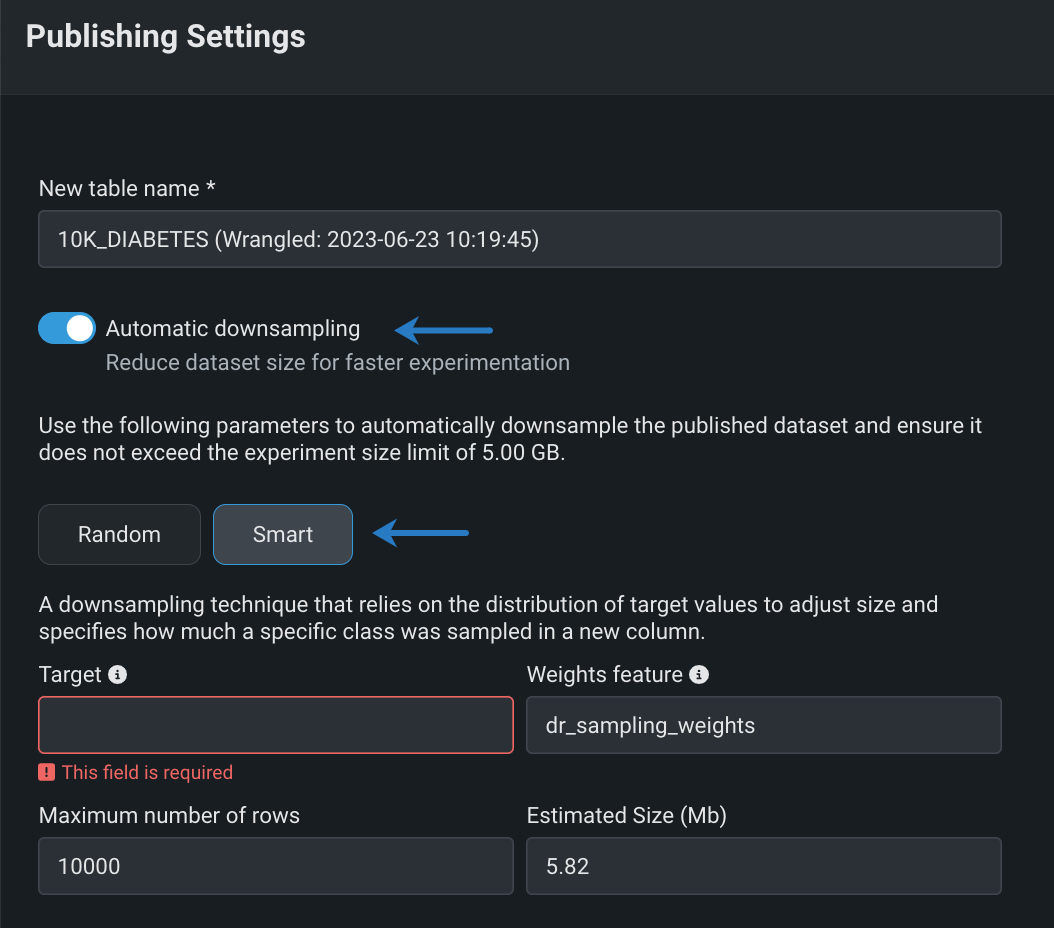
Publish wrangling recipes with smart downsampling¶
After building a wrangling recipe in Workbench, enable smart downsampling in the publishing settings to reduce the size of your output dataset and optimize model training. Smart downsampling is a data science technique that reduces the time it takes to fit a model without sacrificing accuracy, as well as account for class imbalance by stratifying the sample by class.
Native Databricks connector added¶
The native Databricks connector, which lets you access data in Databricks on Azure or AWS, is now generally available in DataRobot. In addition to performance enhancements, the new connector also allows you to:
- Create and configure data connections.
- Authenticate a connection via service principal as well as sharing service principal credentials through secure configurations.
- Add Databricks datasets to a Use Case.
- Wrangle Databricks datasets, and then publish recipes to Databricks to materialize the output in the Data Registry.
- Use the public python API client to access data via the Databricks connector.
Native AWS S3 connector added¶
The new AWS S3 connector is now generally available in DataRobot. In addition to performance enhancements, this connector also enables support for AWS S3 in Workbench, allowing you to:
- Create and configure data connections.
- Add AWS S3 datasets to a Use Case.
Improved recipe management in Workbench¶
This release introduces the following enhancements when wrangling data in Workbench:
- When you wrangle a dataset in your Use Case, including re-wrangling the same dataset, DataRobot creates and saves a copy of the recipe in the Data tab regardless of whether or not you add operations to it. Then, each time you modify the recipe, your changes are automatically saved. Additionally, you can open saved recipes to continue making changes.
- In a Use Case, the Datasets tab has been replaced by the Data tab, which now lists both datasets and recipes. New icons have also been added to the Data tab to quickly distinguish between datasets and recipes.
- During a wrangling session, add a helpful name and description to your recipe for context when re-wrangling a recipe in the future.
NextGen Registry GA¶
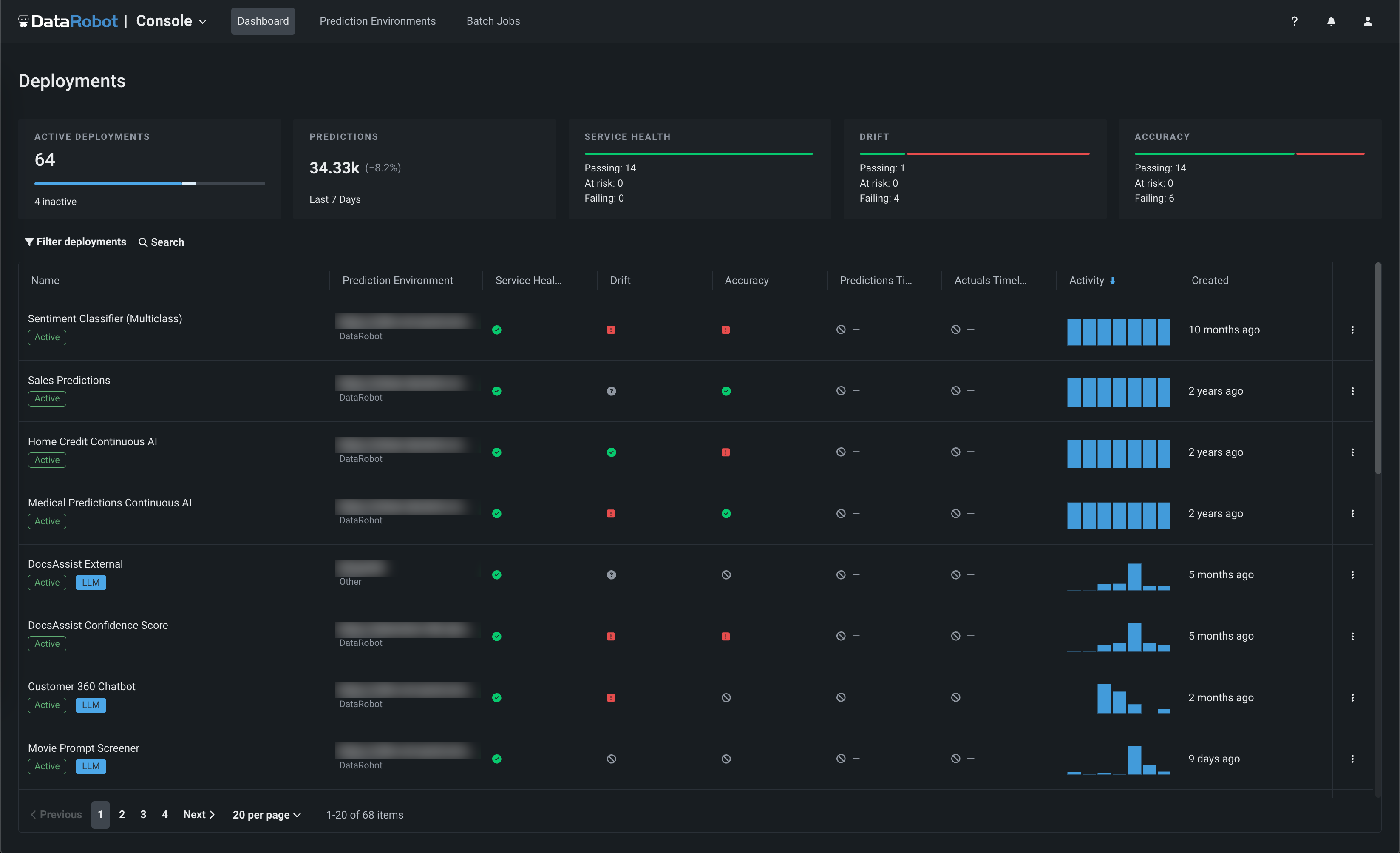
Now generally available in the NextGen Experience, the Registry is an organizational hub for the variety of models used in DataRobot. The Registry > Model directory page lists registered models, each containing deployment-ready model packages as versions. These registered models can contain DataRobot, custom, and external models as versions, allowing you to track the evolution of your predictive and generative models and providing centralized management:
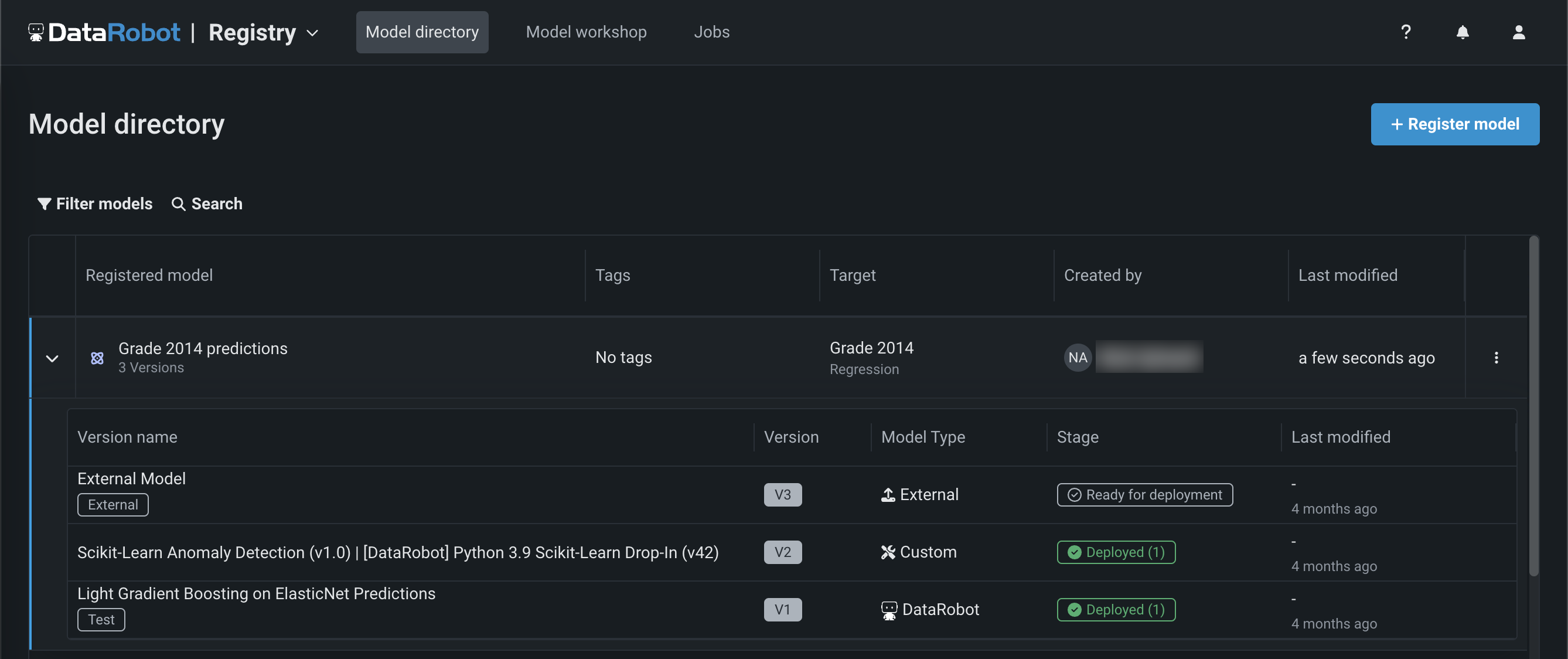
With this release, the registry tracks the System stage and the configurable User stage of a registered model version. Changes to the registered model version stage generate system events. These events can be tracked with notification policies:
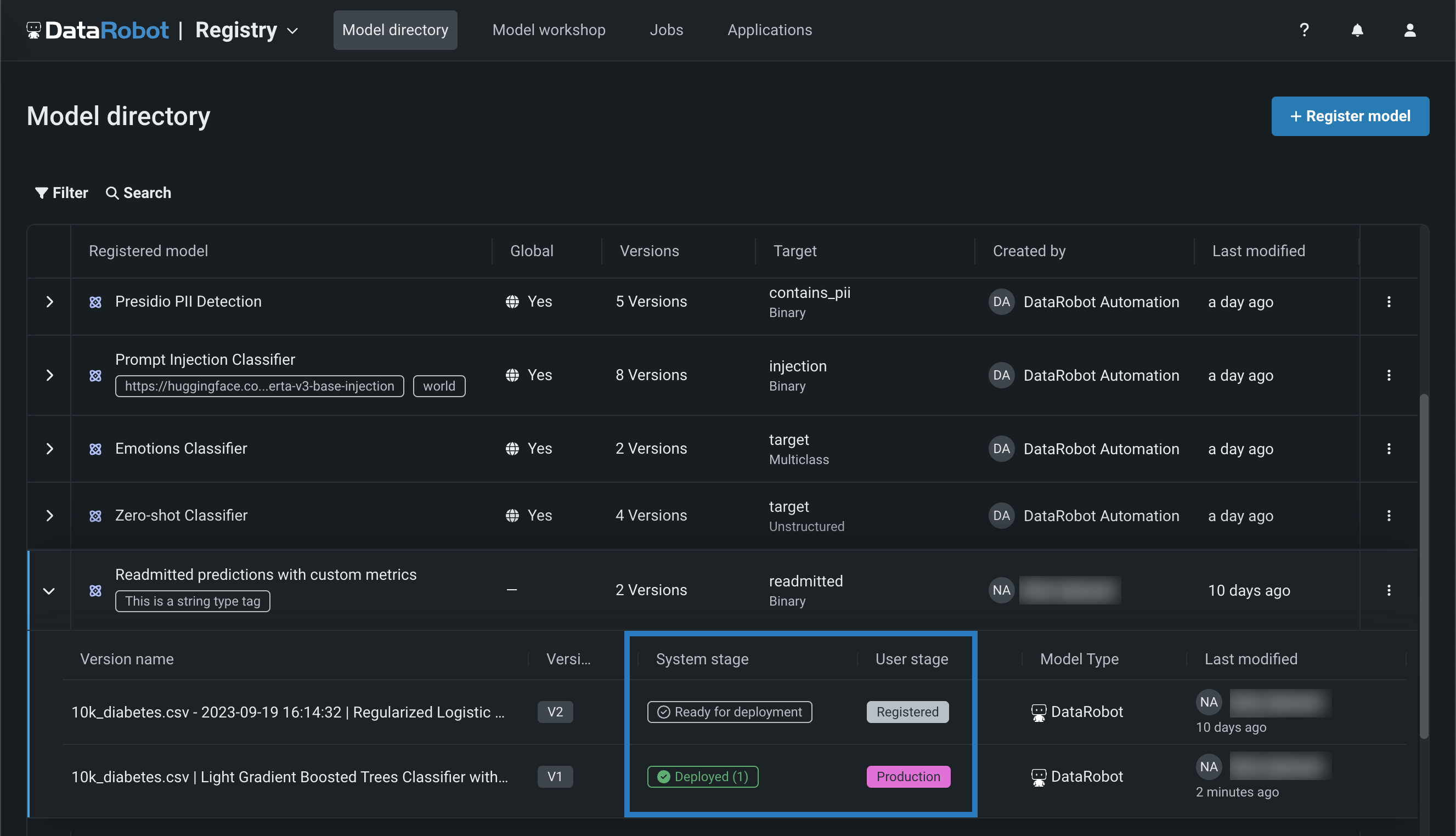
The Registry > Model workshop page allows you to upload model artifacts to create, test, register, and deploy custom models to a centralized model management and deployment hub. Custom models are pre-trained, user-defined models that support most of DataRobot's MLOps features. DataRobot supports custom models built in a variety of languages, including Python, R, and Java. If you've created a model outside of DataRobot and want to upload your model to DataRobot, define the model content and the model environment in the model workshop:
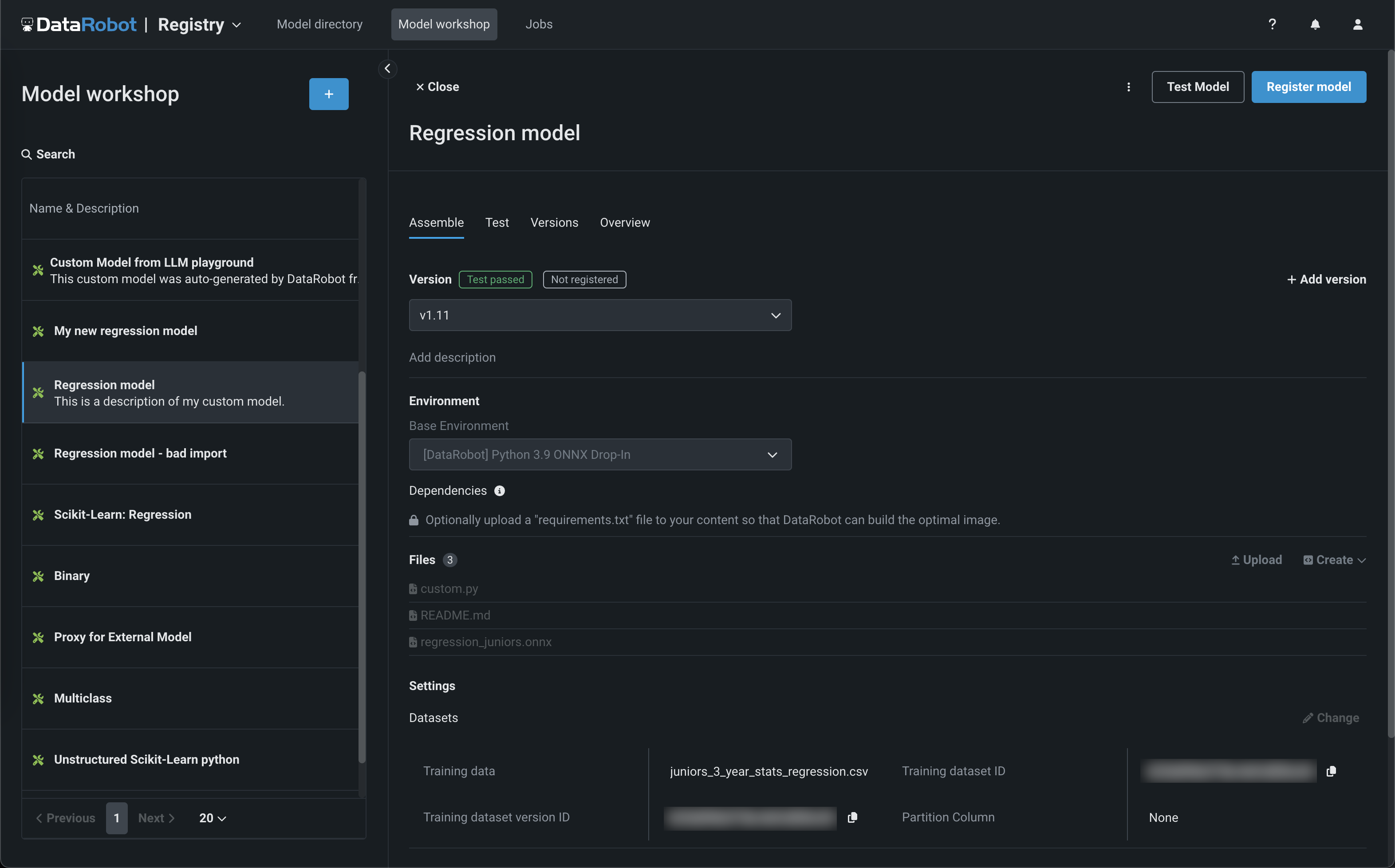
The Registry > Jobs page uses jobs to implement automation (for example, custom tests, metrics, or notifications) for models and deployments. Each job serves as an automated workload, and the exit code determines if it passed or failed. You can run the custom jobs you create for one or more models or deployments. The automated workloads defined through custom jobs can make prediction requests, fetch inputs, and store outputs using DataRobot's Public API:
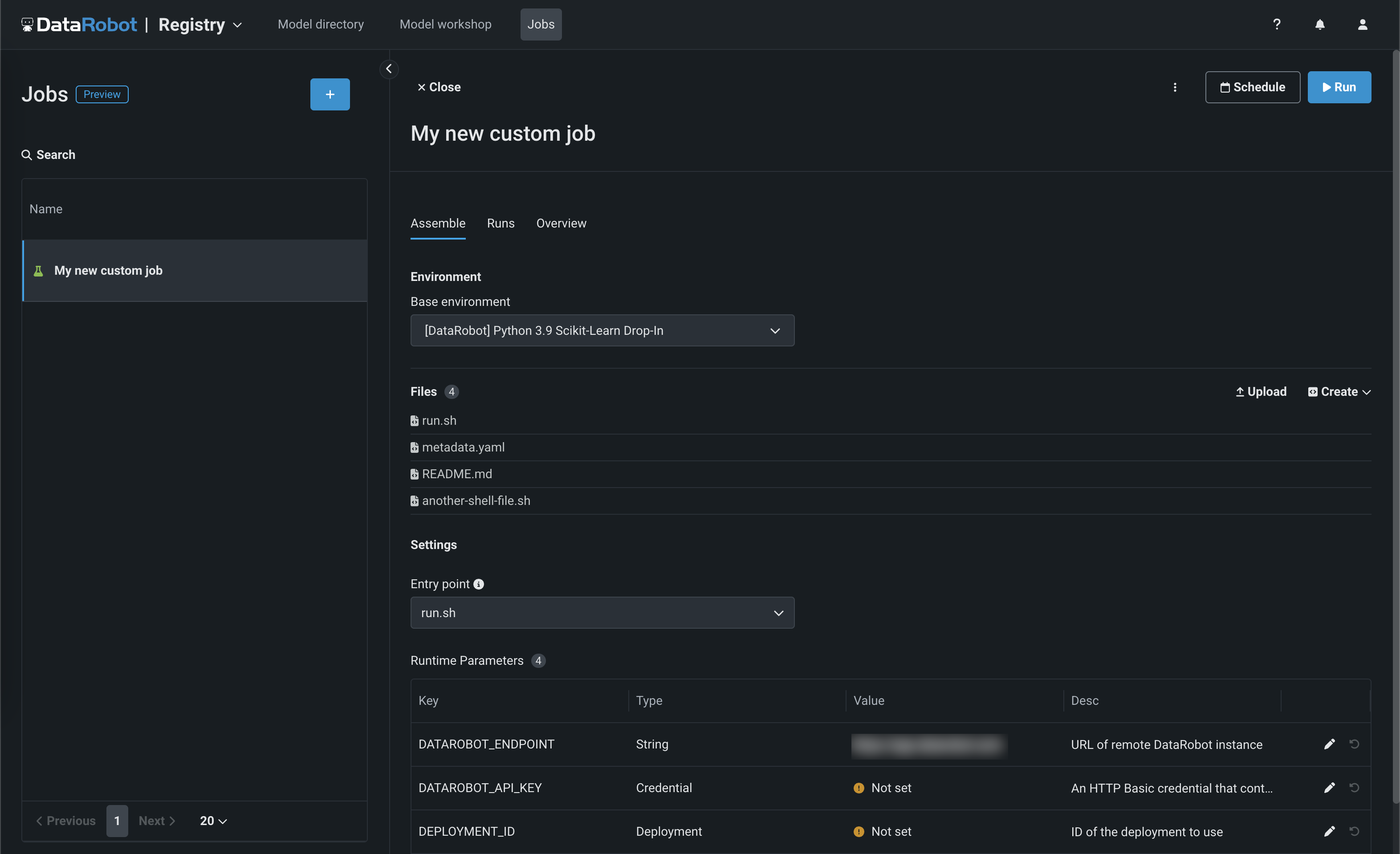
With this release, custom jobs include a Resources settings section where you can configure the resources the custom job uses to run and the egress traffic of the custom job:
For more information, see the documentation.
Global models in the Registry¶
Deploy pre-trained, global models for predictive or generative use cases from the Registry (NextGen) and Model Registry (Classic). These high-quality, open-source models are trained and ready for deployment, allowing you to make predictions immediately after installing DataRobot. For GenAI use cases, you can now find global models for personally identifiable information (PII) identification, zeroshot classification, and emotions classification.
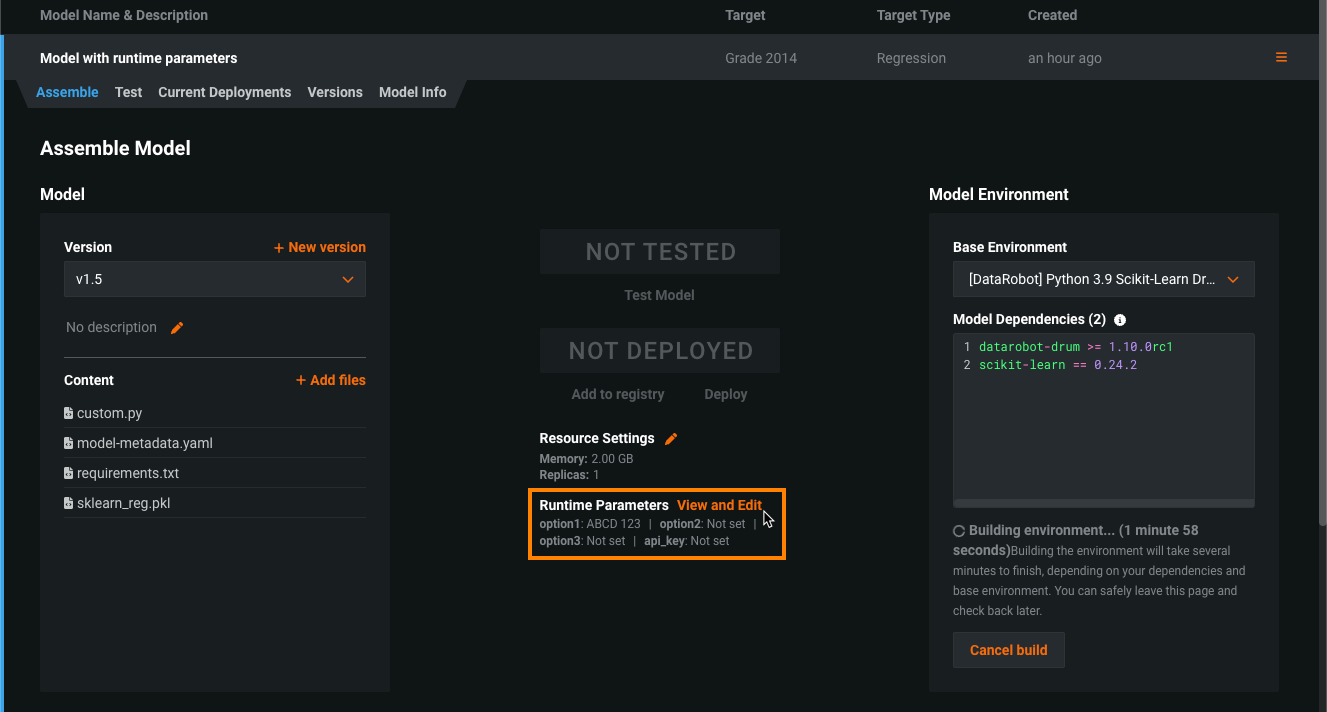
Runtime parameters for custom models¶
Define runtime parameters through runtimeParameterDefinitions in the model-metadata.yaml file, and manage them on the Assemble tab of a custom model in the Runtime Parameters section:
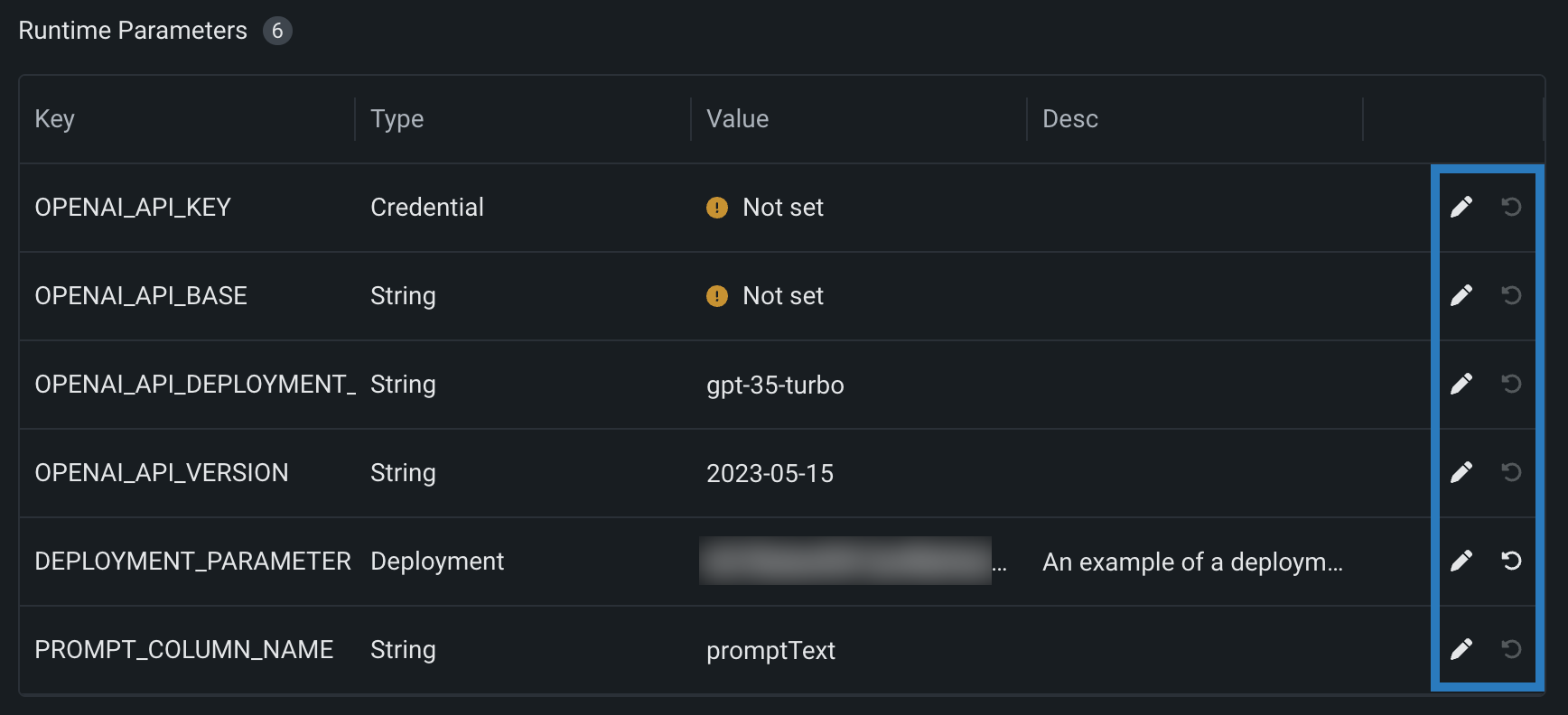
If any runtime parameters have allowEmpty: false in the definition without a defaultValue, you must set a value before registering the custom model.
For more information, see the Classic documentation or NextGen documentation.
Notification policies for deployments¶
Configure deployment notifications through the creation of notification policies, you can configure and combine notification channels and templates. The notification template determines which events trigger a notification, and the channel determines which users are notified. The available notification channel types are webhook, email, Slack, Microsoft Teams, User, Group, and Custom Job. When you create a notification policy for a deployment, you can use a policy template without changes or as the basis of a new policy with modifications. You can also create an entirely new notification policy:
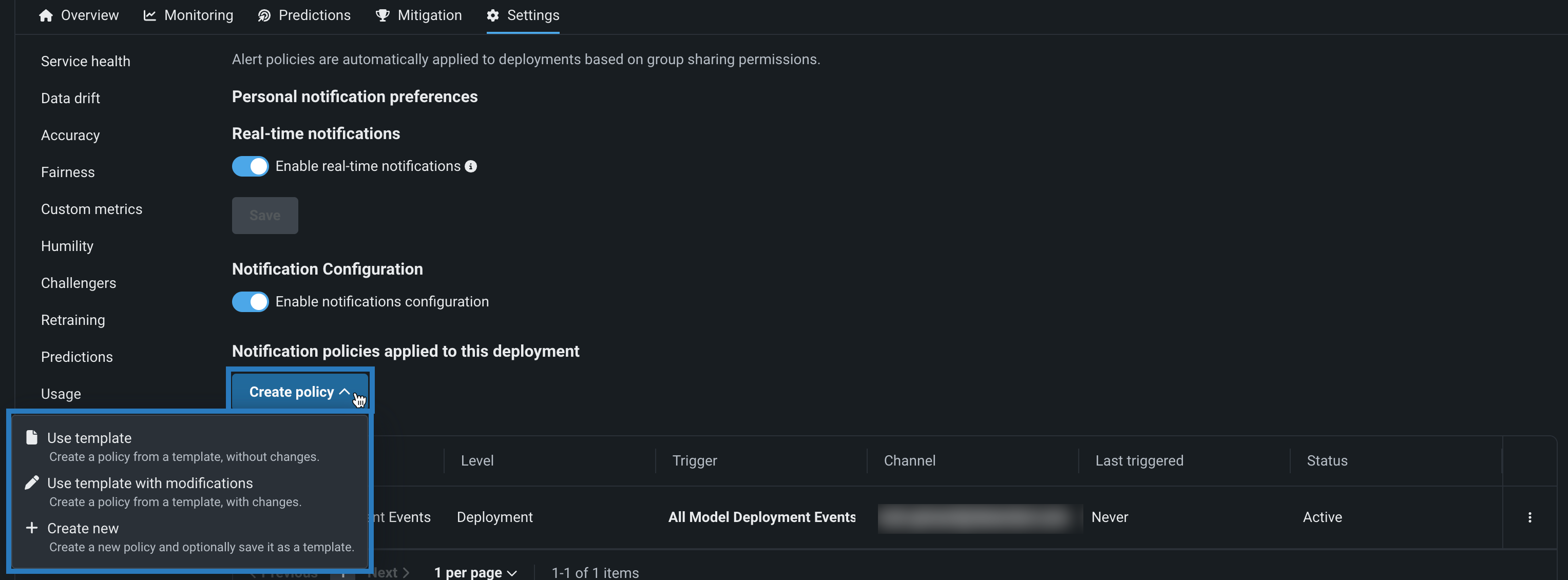
Preview¶
LLM evaluation and moderation metrics for LLM blueprints and deployments¶
LLM evaluation tools enable better understanding of LLM blueprint performance and whether or not they are ready for production. For example, evaluation metrics help your organization report on prompt injection and hateful, toxic, or inappropriate prompts and responses. Many evaluation metrics connect a playground-built LLM to a deployed guard model. Moderations can intervene when prompt injection, PII leakage, and off topic discussions are detected, enabling your organization to address the most common LLM security problems.
Now in preview, tools available from the playground allow you to:
-
Configure evaluation metrics to understand LLM performance in your playground and send final models to the model workshop.
-
Add guardrails to prevent the most common LLM security problems, such as prompt injection, PII leakage, staying on topic, and more.
-
Bring in evaluation datasets. Or, DataRobot can generate an evaluation dataset, based on your vector database, to leverage during assessment in the playground.
-
Integrate with popular guardrail frameworks like NVIDIA’s NeMo and Guardrails.
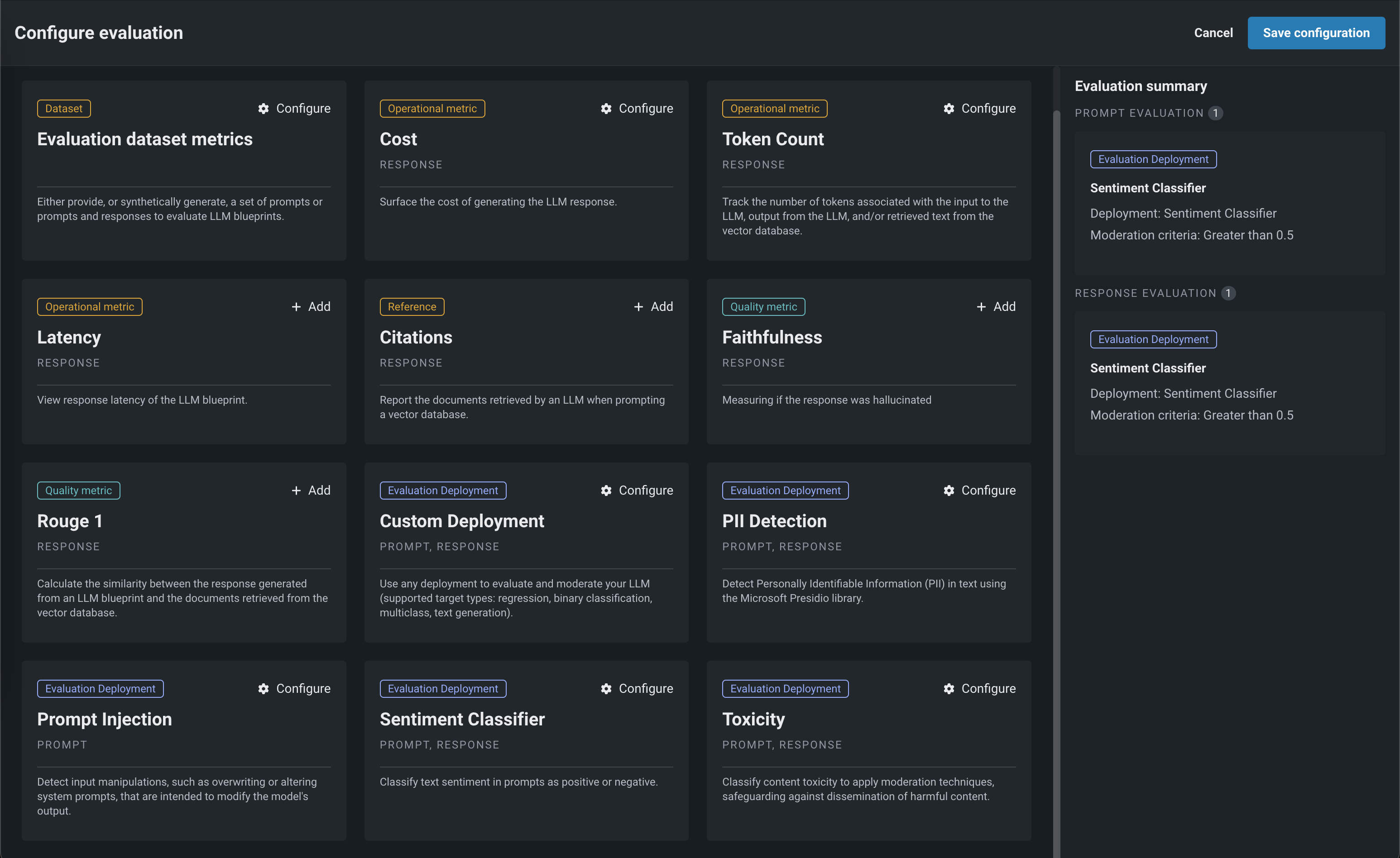
Preview documentation.
Feature flag OFF by default: GenAI capabilities are premium features. Contact your DataRobot representative or administrator for information on enabling them.
SHAP-based Individual Prediction Explanations in Workbench¶
SHAP-based explanations help to understand what drives predictions on a row-by-row basis by providing an estimation of how much each feature contributes to a given prediction differing from the average. With their introduction to Workbench, SHAP explanations are available for all model types; XEMP-based explanations are not available in Use Case experiments. Use the controls in the insight to set the data partition, apply slices, and set a prediction range.
Note
To better communicate this feature’s functionality as a local explanation method that calculates SHAP values for each individual row, we have updated the name from SHAP Prediction Explanations to Individual Prediction Explanations.
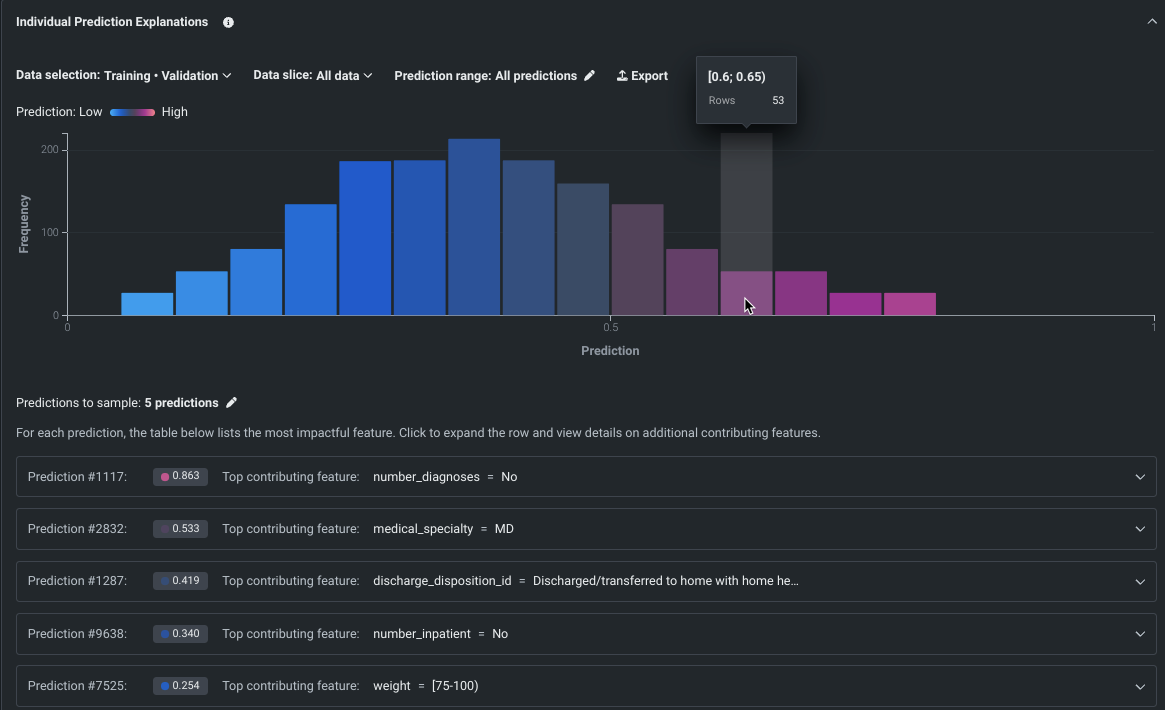
Preview documentation.
Feature flag ON by default: Universal SHAP in NextGen
Create custom feature lists in existing experiments¶
In Workbench, you can now add new, custom feature lists to an existing predictive or forecasting experiment through the UI. DataRobot automatically creates several feature lists, which control the subset of features that DataRobot uses to build models and make predictions, on data ingest. Now, you can create your own lists from the Feature Lists or Data tabs in the Experiment information window accessed from the Leaderboard. Use bulk selections to choose multiple features with a single click:
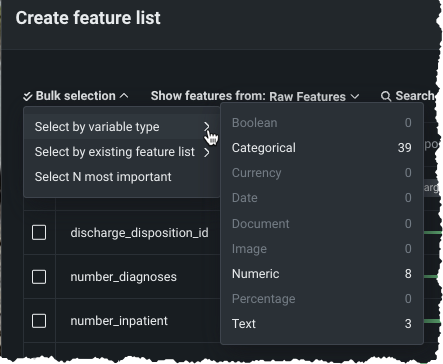
Preview documentation.
Feature flags ON by default: Enable Data and Feature Lists tabs in Workbench, Enable Feature Lists in Workbench Preview, Enable Workbench Feature List Creation
Scalability up to 100GB now available with incremental learning¶
Available as a preview feature, you can now train models on up to 100GB of data using incremental learning (IL) for binary and regression project types. IL is a model training method specifically tailored for large datasets that chunks data and creates training iterations. Configuration options allow you to control whether a top model trains on one—or all—iterations and whether training stops if accuracy improvements plateau. After model building begins, you can compare trained iterations and optionally assign a different active version or continue training. The active iteration is the basis for other insights and is used for making predictions.
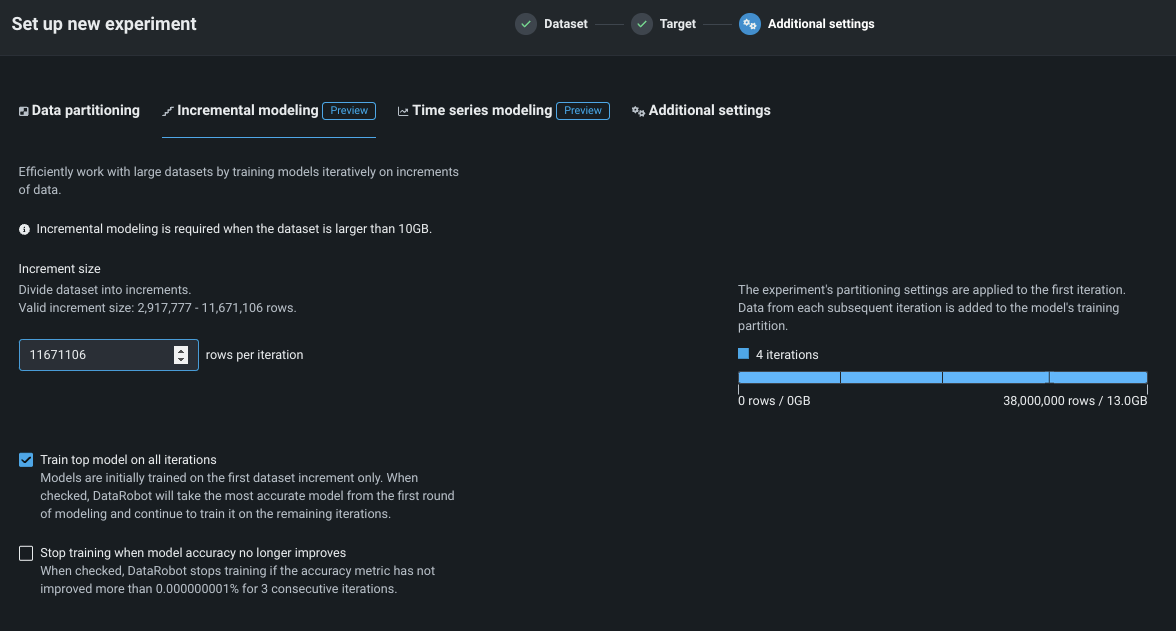
Preview documentation.
Feature flags OFF by default:: Enable Incremental Learning, Enable Data Chunking
Configure actuals and predictions upload limits¶
Now available as a preview feature, from the Usage tab, you can monitor the hourly, daily, and weekly upload limits configured for your organization's deployments. View charts that visualize the number of predictions and actuals processed and tiles that display the table size limits for returned prediction results.
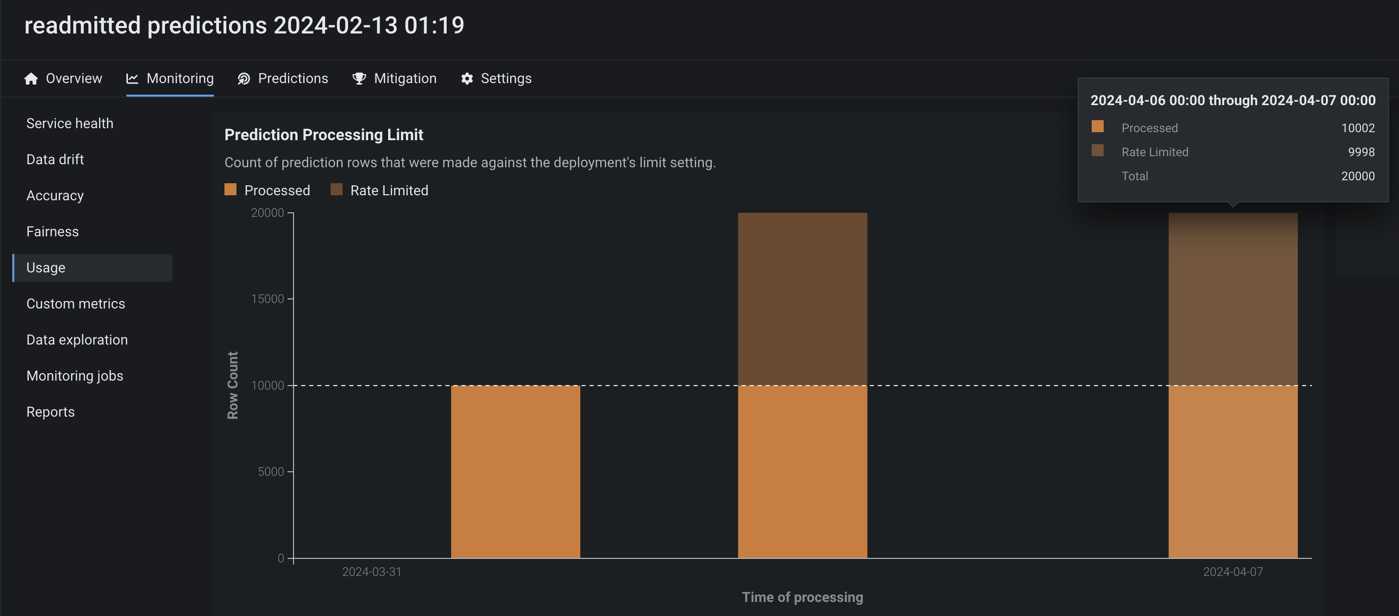
Feature flag OFF by default: Enable Configurable Prediction and Actuals Limits
Preview documentation.
Configure runtime parameters and resource bundles for custom applications¶
Now available as a preview feature, you can configure the resources and runtime parameters for application sources in the NextGen Registry. The resources bundle determines the maximum amount of memory and CPU that an application can consume to minimize potential environment errors in production. You can create and define runtime parameters used by the custom application by including them in the metadata.yaml file built from the application source.
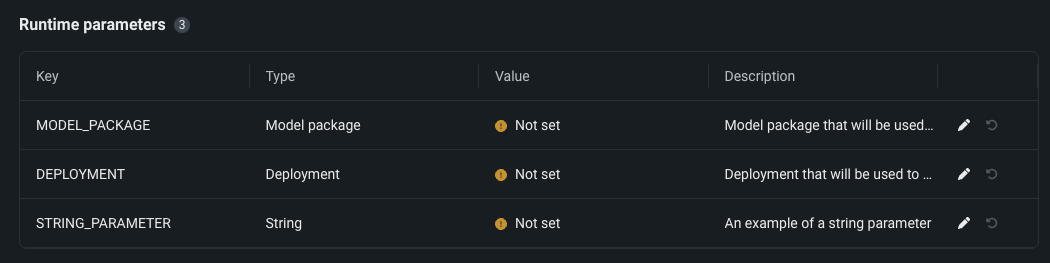
Feature flags OFF by default: Enable Runtime Parameters and Resource Limits, Enable Resource Bundles
Preview documentation.
Perform Feature Discovery in Workbench¶
Now available for preview, perform Feature Discovery in Workbench to discover and generate new features from multiple datasets. You can initiate Feature Discovery in two places:
- The Data tab, to the right of the dataset that will serve as the primary dataset, click the Actions menu > Feature Discovery.
- The data explore page of a specific dataset, click Data actions > Start feature discovery.
On this page, you can add secondary datasets and configure relationships between the datasets.
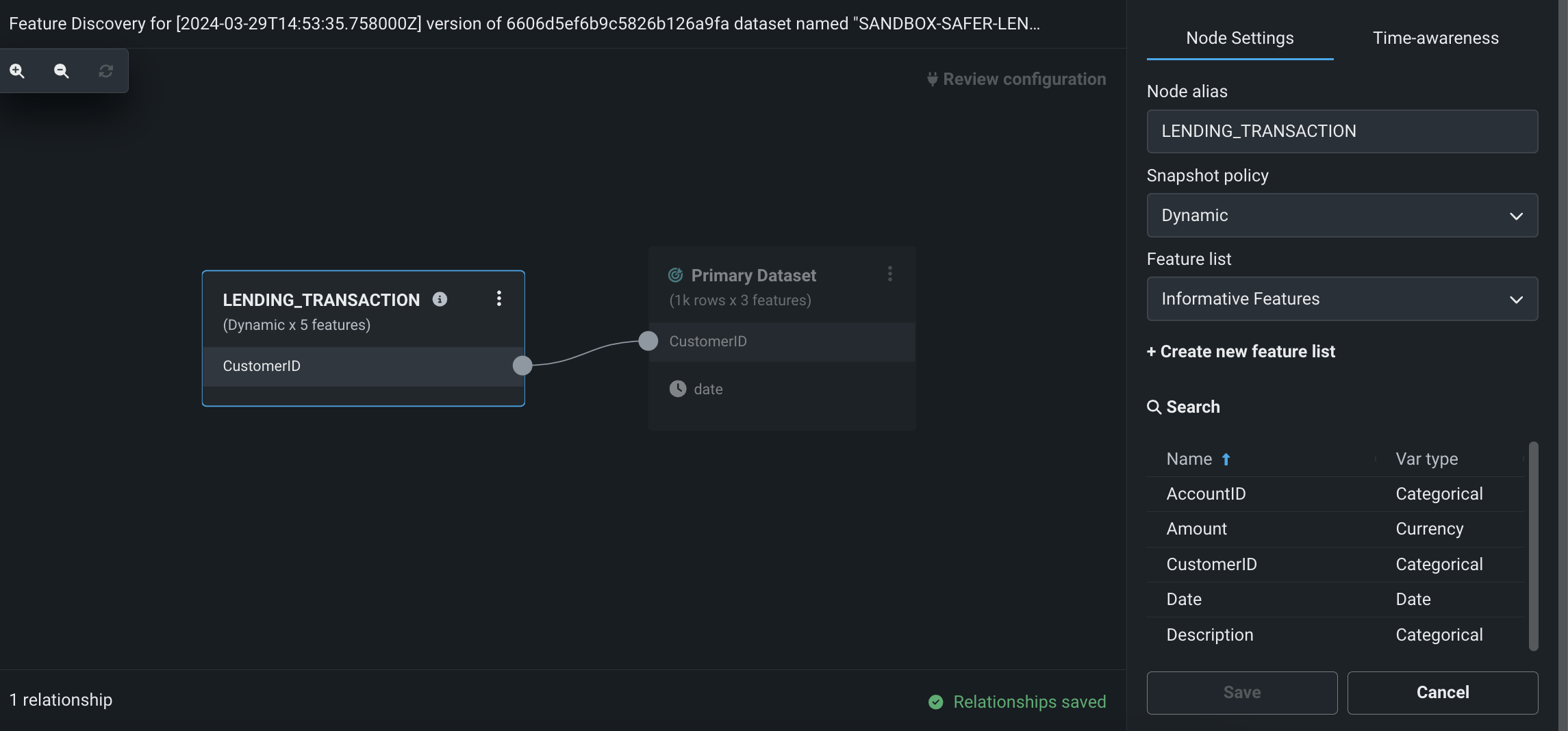
Publishing a Feature Discovery recipe instructs DataRobot to perform the specific joins and aggregations, generating a new output dataset that is then registered in the Data Registry and added to your current Use Case.
Preview documentation.
Feature flag(s) ON by default: Enable Feature Discovery in Workbench
Data improvements added to Workbench¶
This release introduces the following enhancements, available for preview, when working with data in Workbench:
- The data explore page now supports dataset versioning, as well as the ability to rename and download datasets.
- The feature list dropdown is now a separate tab on the data explore page.
- Autocomplete functionality has been improved for the Compute New Feature operation.
- You can now use dynamic datasets to set up an experiment.
Feature flag(s) OFF by default: Enable Enhanced Data Explore View
Make Feature Discovery predictions with distributed mode¶
Now available for preview, when enabled, DataRobot processes batch predictions in distributed mode, increasing scalability. Note that DataRobot will automatically run in distributed mode if the dataset comes from the AI Catalog.
Preview documentation.
Feature flag(s) OFF by default: Enables distributed mode when making predictions in Feature Discovery projects, Enable Feature Discovery in Distributed Mode
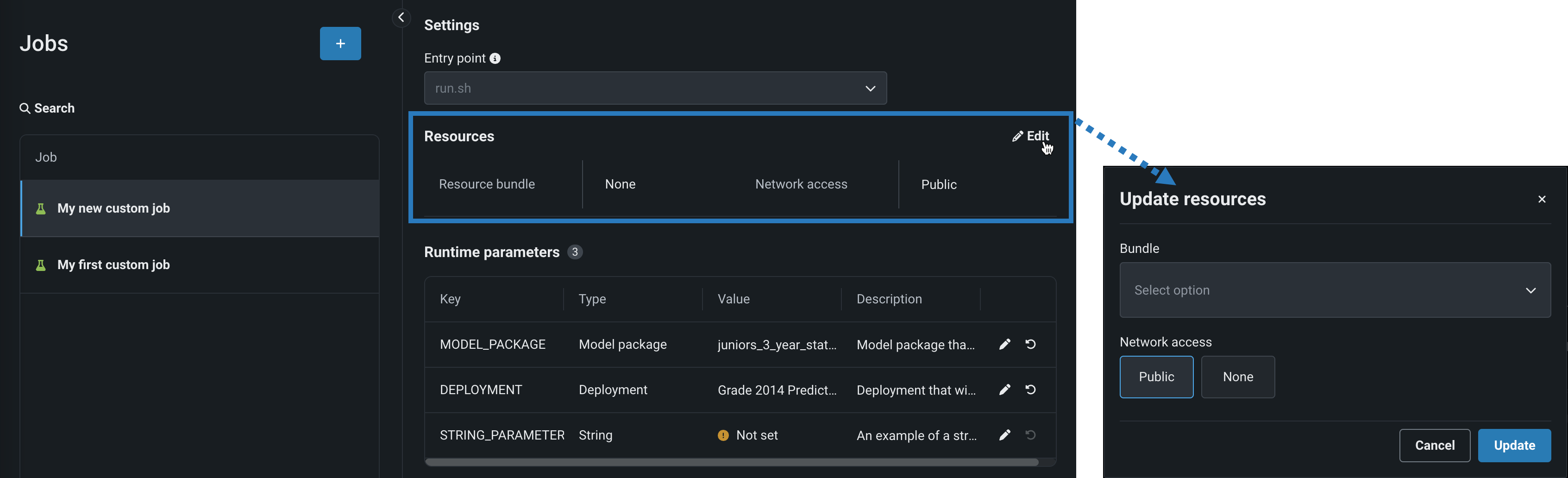
Resource bundles for custom models¶
Select a Resource bundle—instead of Memory—when you assemble a model and configure the resource settings. Resource bundles allow you to choose from various CPU and GPU hardware platforms for building and testing custom models. In a custom model's Settings section, open the Resources settings to select a resource bundle. In this example, the model is built to be tested and deployed on an NVIDIA A10 device.
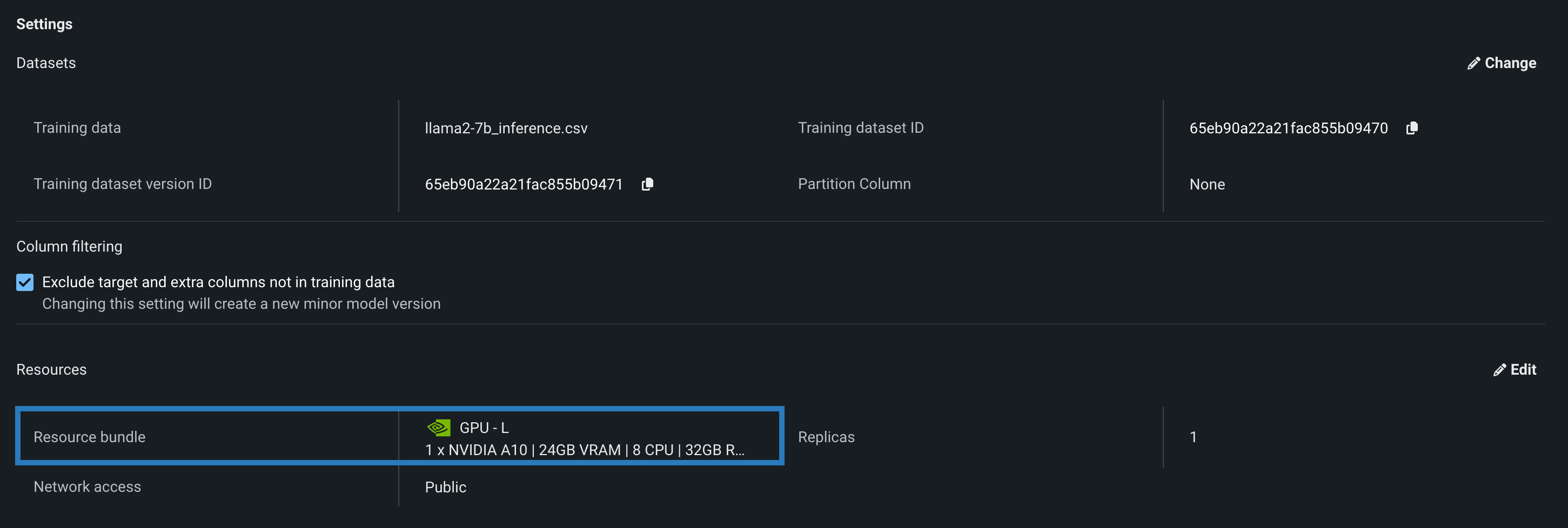
Click Edit to open the Update resource settings dialog box and, in the resource Bundle field, review the CPU and NVIDIA GPU devices available as build environments:
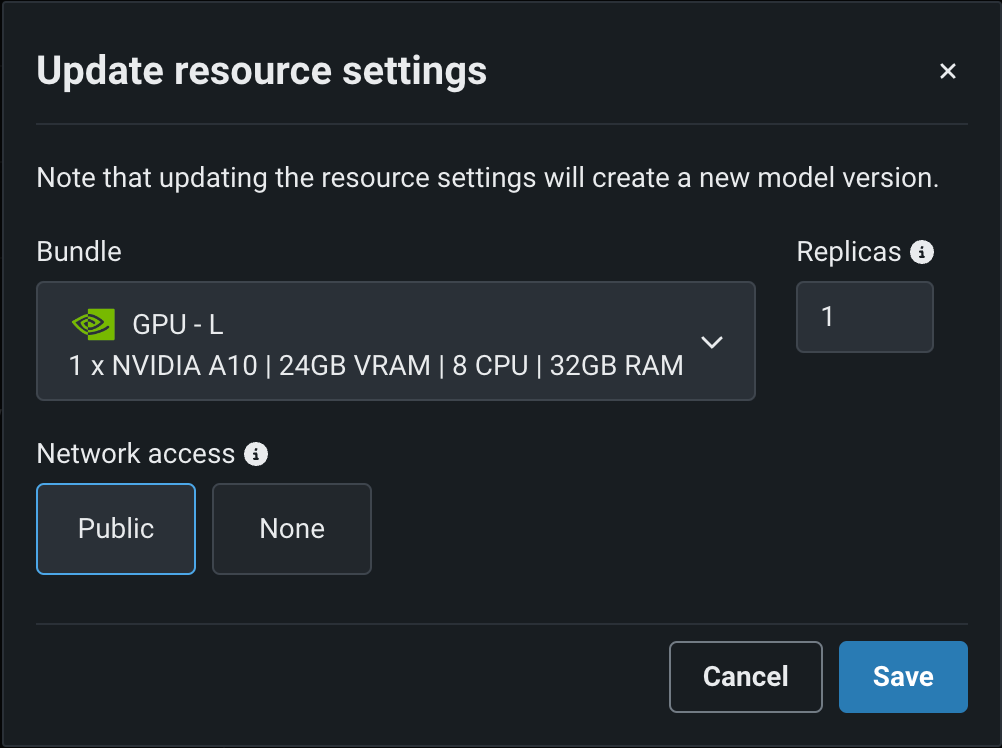
Preview documentation.
Feature flags OFF by default: Enable Resource Bundles, Enable Custom Model GPU Inference
Evaluation and moderation for text generation models¶
Evaluation and moderation guardrails help your organization block prompt injection and hateful, toxic, or inappropriate prompts and responses. It can also prevent hallucinations or low-confidence responses and, more generally, keep the model on topic. In addition, these guardrails can safeguard against the sharing of personally identifiable information (PII). Many evaluation and moderation guardrails connect a deployed text generation model (LLM) to a deployed guard model. These guard models make predictions on LLM prompts and responses and then report these predictions and statistics to the central LLM deployment. To use evaluation and moderation guardrails, first, create and deploy guard models to make predictions on an LLM's prompts or responses; for example, a guard model could identify prompt injection or toxic responses. Then, when you create a custom model with the Text Generation target type, define one or more evaluation and moderation guardrails.
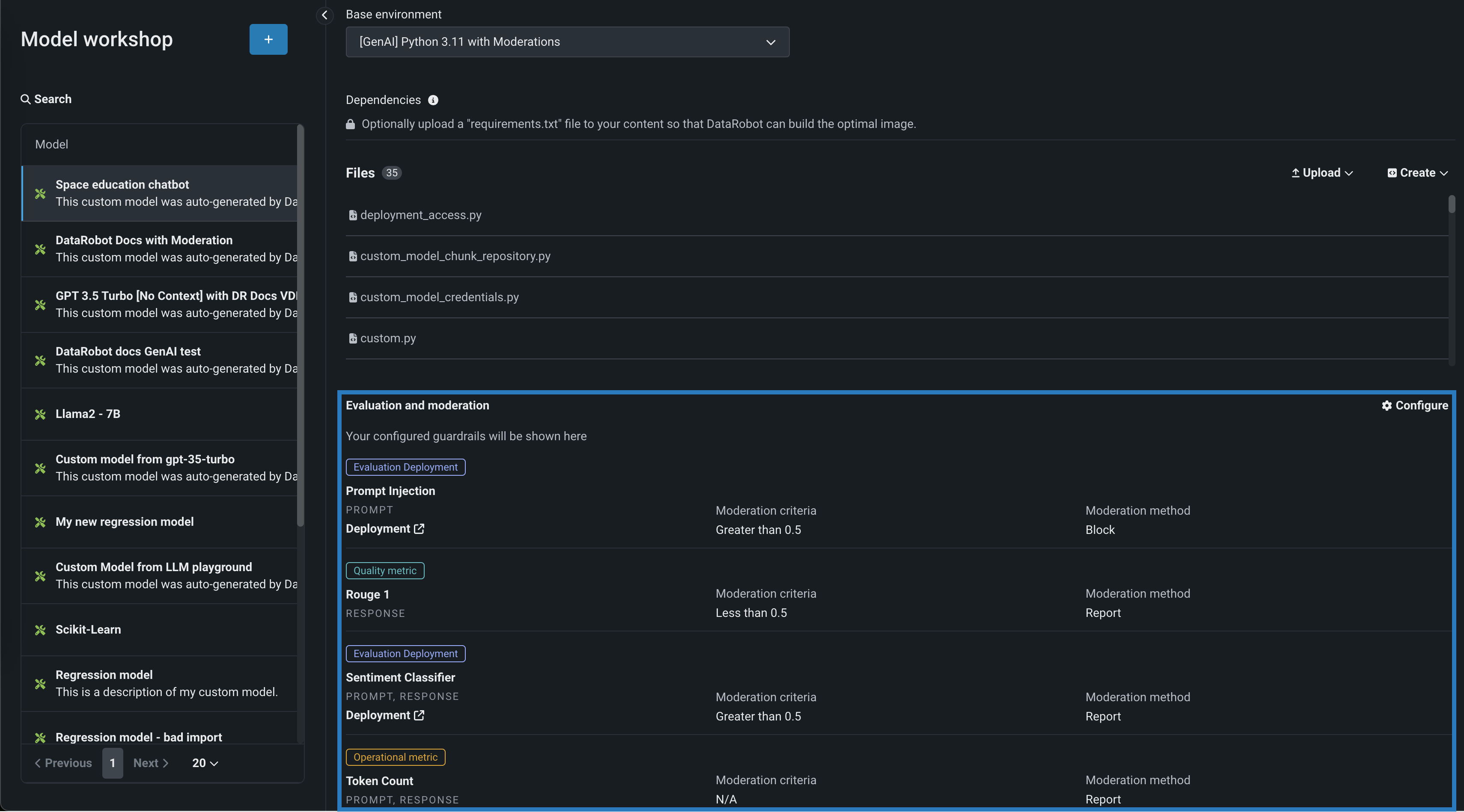
Preview documentation.
Feature flags OFF by default: Enable Moderation Guardrails, Enable Global Models in the Model Registry (Premium), Enable Additional Custom Model Output in Prediction Responses
Time series custom models¶
Create time series custom models by selecting Time Series (Binary) or Time Series (Regression) as a Target type and configuring time series-specific fields, in addition to the fields required for binary classification and regression models:
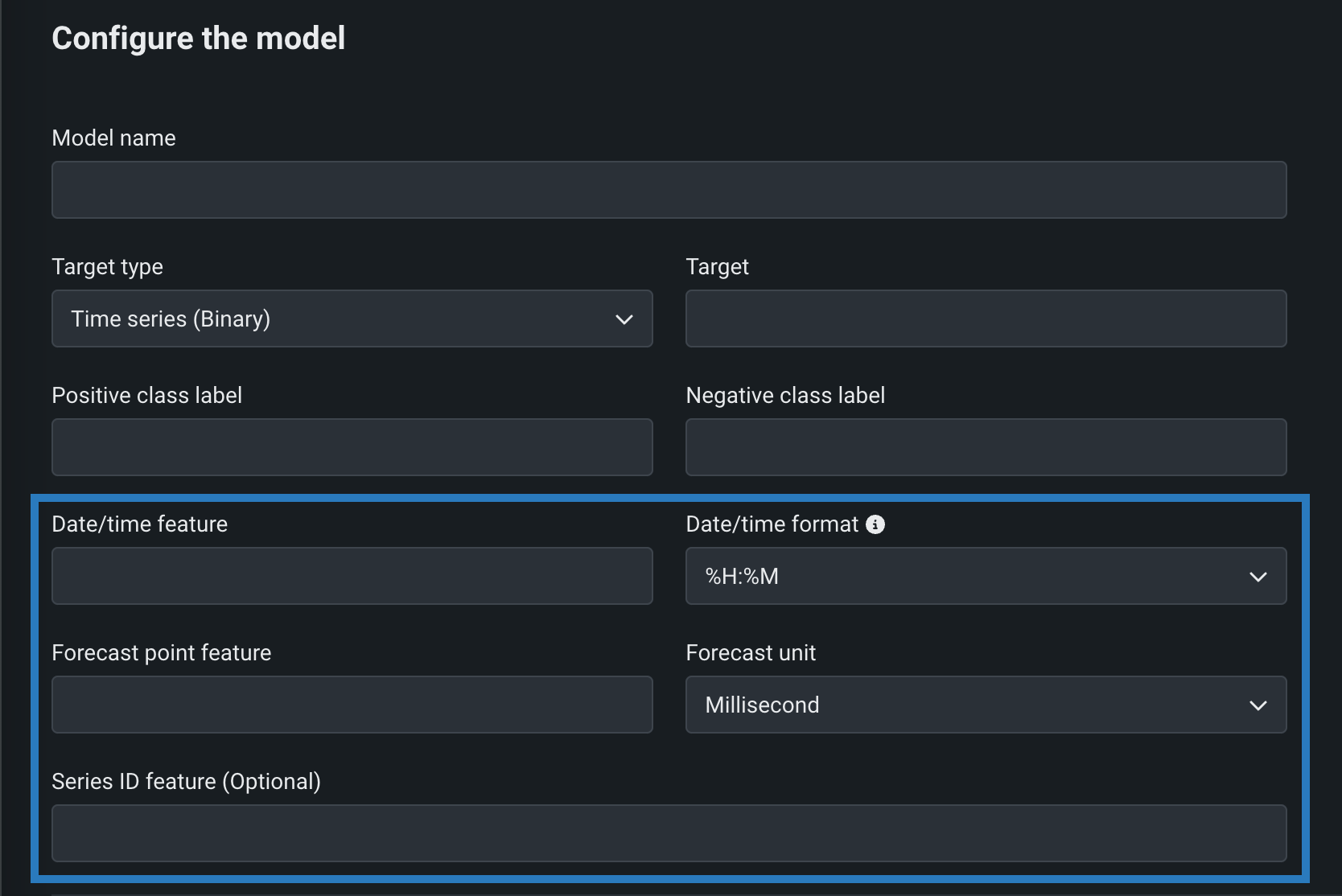
Preview documentation.
Feature flags OFF by default: Enable Time Series Custom Models, Enable Feature Filtering for Custom Model Predictions
Data tracing for deployments¶
On the Data exploration tab of a Generative AI deployment, click Tracing to explore prompts, responses, user ratings, and custom metrics matched by association ID. This view provides insight into the quality of the Generative AI model's responses, as rated by users and based on any Generative AI custom metrics you implement:
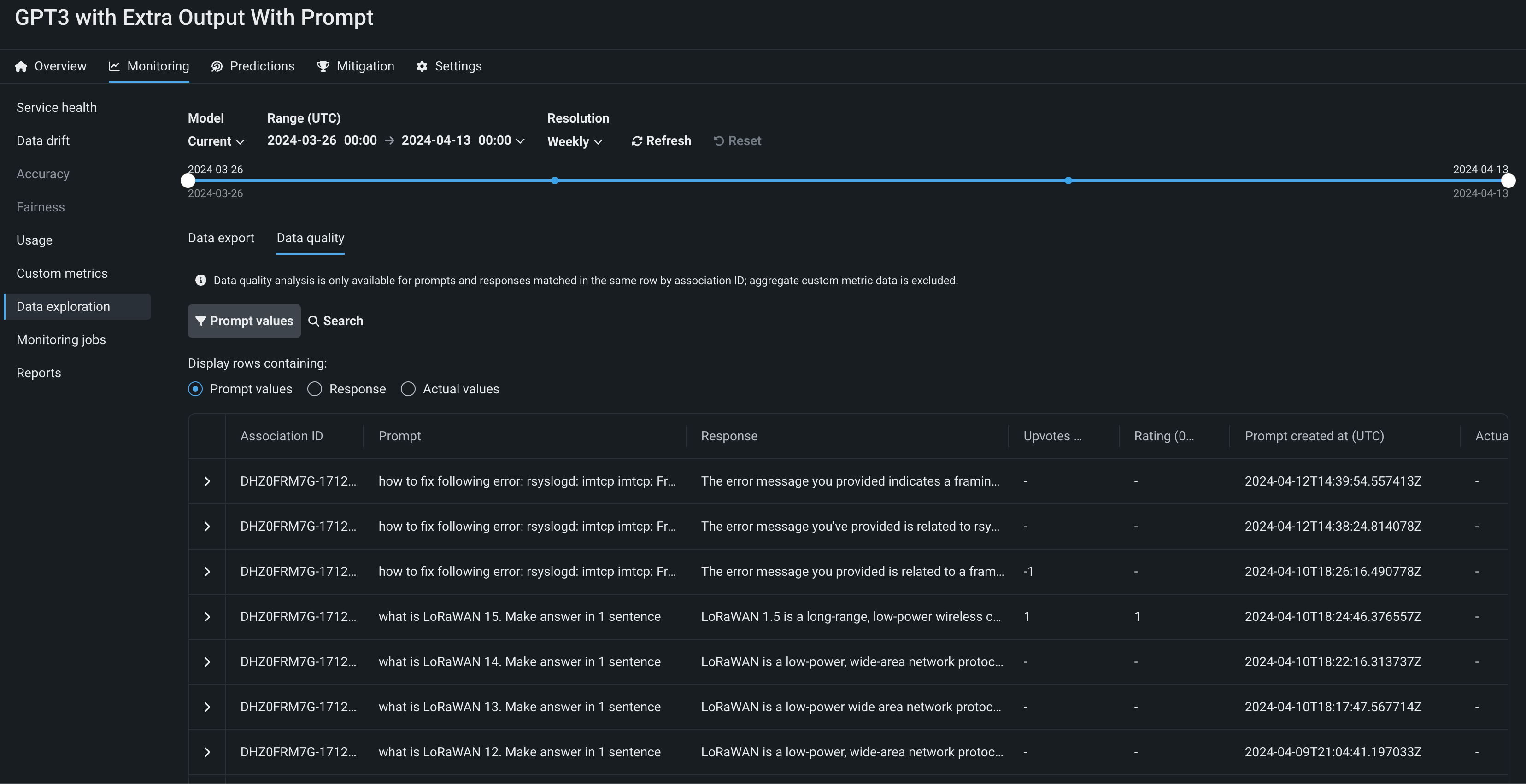
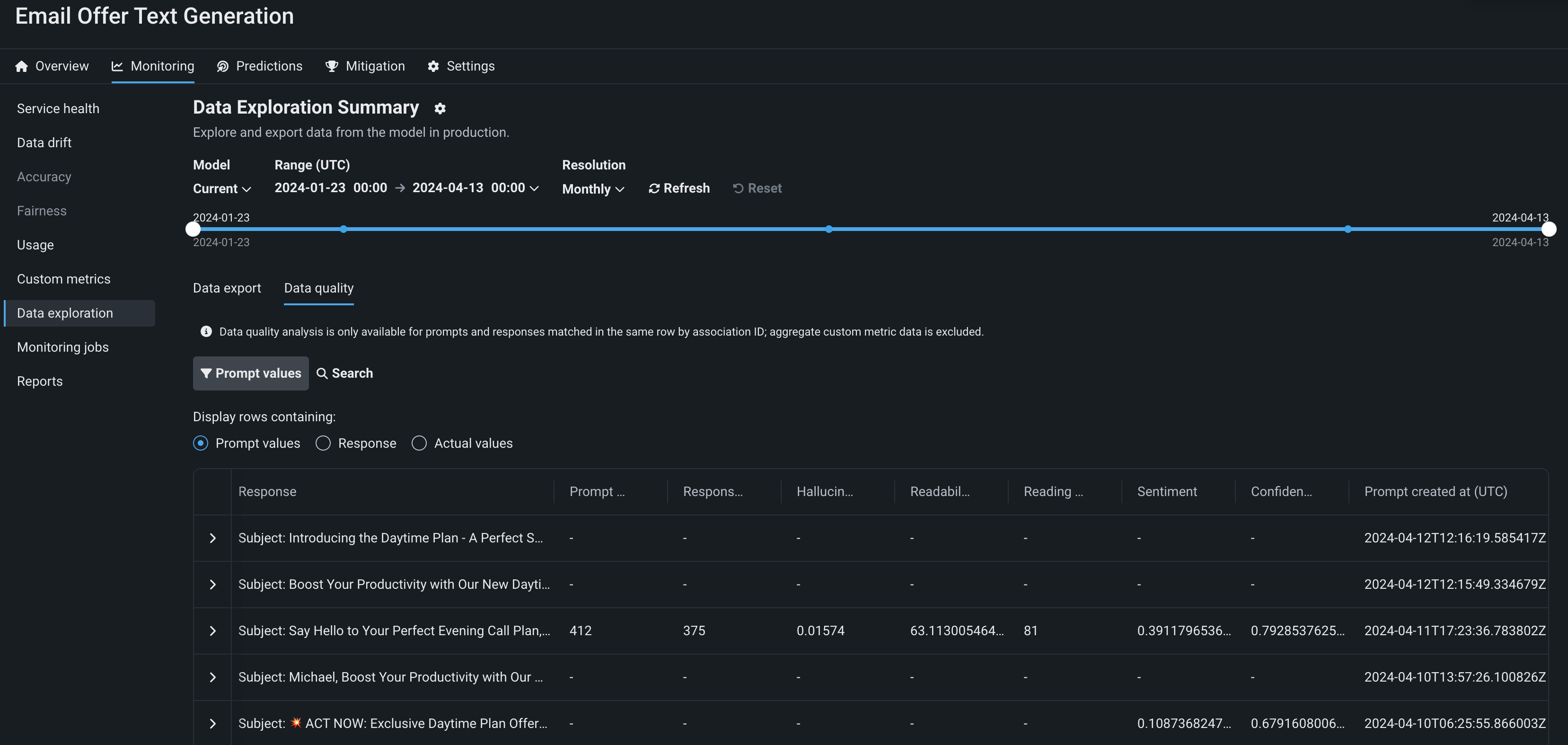
Preview documentation.
Feature flags OFF by default: Enable Data Quality Table for Text Generation Target Types (Premium feature), Enable Actuals Storage for Generative Models (Premium feature)
Code-based retraining jobs¶
When you create a custom job on the NextGen Registry > Jobs page, you can now create code-based retraining jobs. Click + Add new (or the button when the custom job panel is open), and then click Add custom job for retraining. After you create a custom job for retraining, you can add it to a deployment as a retraining policy.
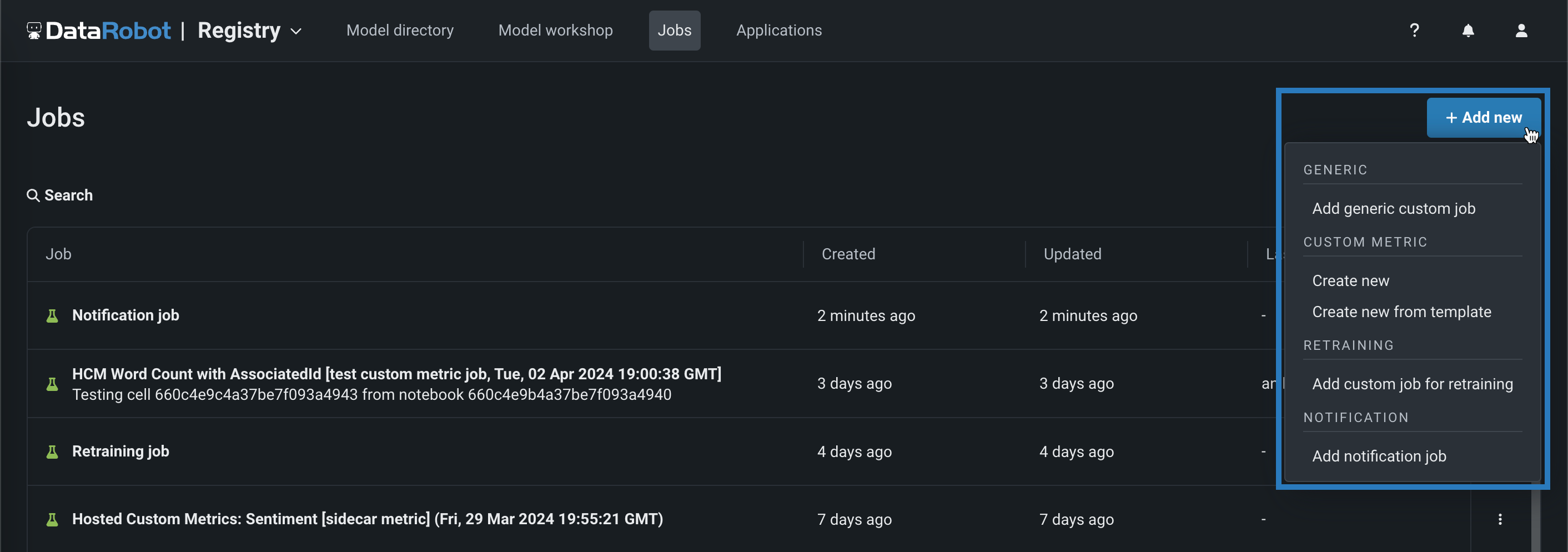
Preview documentation.
Wrangler recipes in batch predictions¶
Use a deployment's Predictions > Make predictions tab to efficiently score Wrangler datasets with a deployed model by making batch predictions. Batch predictions are a method of making predictions with large datasets, in which you pass input data and get predictions for each row. In the Prediction dataset box, click Choose file > Wrangler to make predictions with a Wrangler dataset:
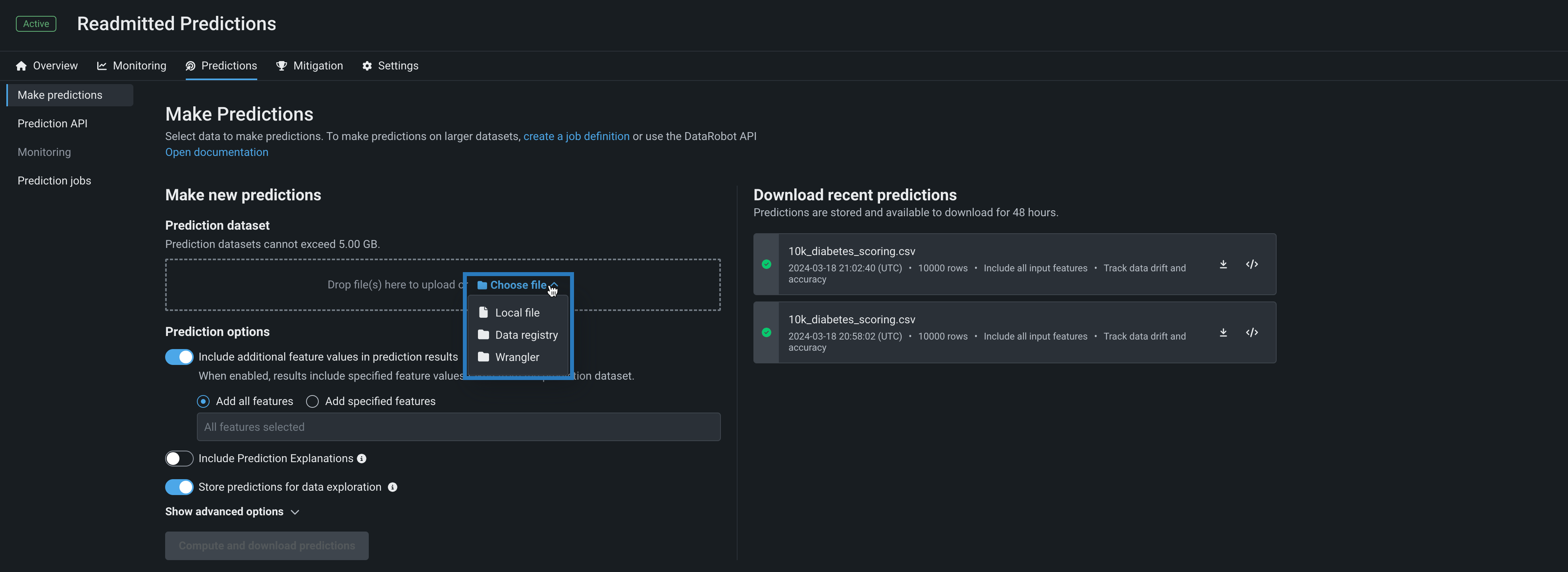
Predictions in Workbench
Wrangler is also available as a prediction dataset source in Workbench. To make predictions with a model before deployment, select the model from the Models list in an experiment and then click Model actions > Make predictions.
You can also schedule batch prediction jobs by specifying the prediction data source and destination and determining when DataRobot runs the predictions.
For more information, see the documentation.
Migrate projects and notebooks from DataRobot Classic to NextGen¶
Now available for preview, DataRobot allows you to transfer projects and notebooks created in DataRobot Classic to DataRobot NextGen. You can export projects in DataRobot Classic and add them to a Use Case in Workbench as an experiment. Notebooks can also be exported from Classic and added to a Use Case in Workbench.
Preview documentation.
Feature flag OFF by default: Enable Asset Migration
API¶
Python client v3.4¶
v3.4 for DataRobot's Python client is now generally available. For a complete list of changes introduced in v3.4, view the Python client changelog.
DataRobot REST API v2.33¶
DataRobot's v2.33 for the REST API is now generally available. For a complete list of changes introduced in v2.33, view the REST API changelog.
Deprecations and migrations¶
Tableau extension removal¶
DataRobot previously offered two Tableau Extensions, Insights, and What-If, that have now been deprecated and removed from the application. The extensions have also been removed from the Tableau store.
Custom model training data assignment update¶
In April 2024, the assignment of training data to a custom model version—announced in the March 2023 release—replaced the deprecated method of assigning training data at the custom model level. This means that the “per custom model version” method becomes the default, and the “per custom model” method is removed.
The automatic conversion of any remaining custom models using the “per custom model” method occurred automatically when the deprecation period ended, assigning the training data at the custom model version level. For most users, no action is required; however, if you have any remaining automation relying on unconverted custom models using the “per custom model” assignment method, you should update them to support the “per custom model version” method to avoid any gaps in functionality.
For a summary of the assignment method changes, you can view the Custom model training data assignment update documentation.
All product and company names are trademarks™ or registered® trademarks of their respective holders. Use of them does not imply any affiliation with or endorsement by them.