2024年3月¶
2024年3月27日
このページでは、新たにリリースされ、DataRobotのSaaS型シングル/マルチテナントAIプラットフォームで利用できる機能についてのお知らせと、追加情報へのリンクを掲載しています。 リリースセンターからは、次のものにもアクセスできます。
注目の新機能¶
多クラスモデリングと混同行列¶
多クラスエクスペリメントがワークベンチのプレビュー機能として可能になりました。
動画:多クラスモデリング
エクスペリメントを構築する際、DataRobotは、指定されたターゲット特徴量での値の数に基づいて型を決定します。 3つ以上であれば、エクスペリメントは多クラスまたは連続値 (数値ターゲットの場合) として処理されます。 DataRobotによる特別な処理により、以下のことが可能です。
- 連続値エクスペリメントを多クラスに変更する。
- 設定の変更が可能な集計を使用して、1000を超えるクラスをサポートする。
モデルが構築されると、多クラス混同行列によって、モデルがあるクラスを別のクラスと誤ってラベル付けしている箇所を目で確認することができます。
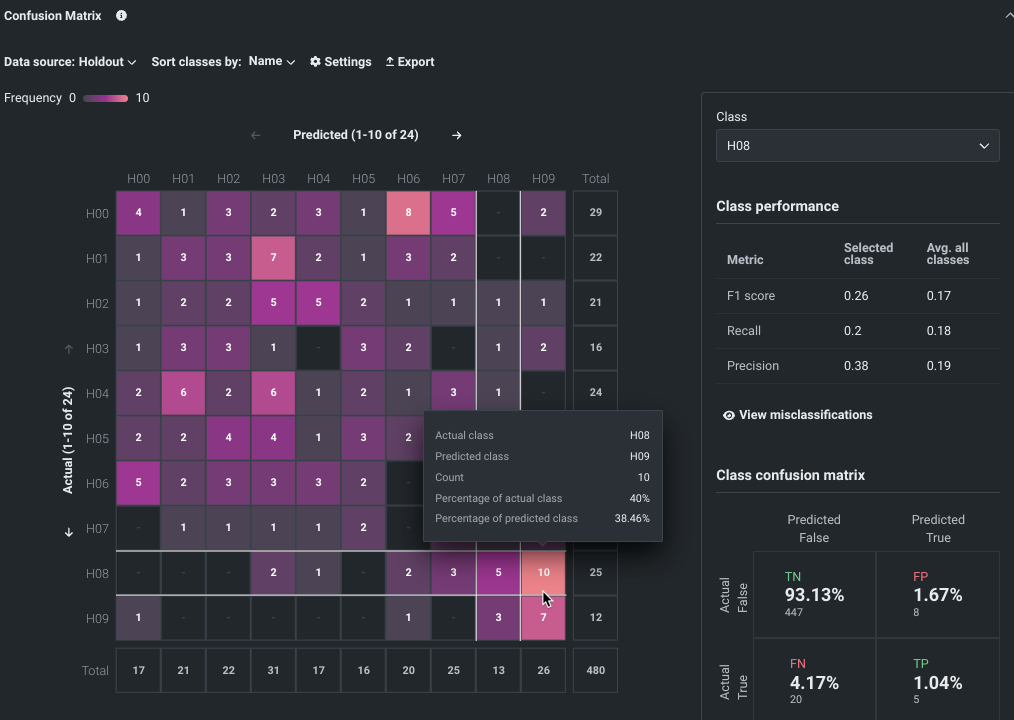
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ:無制限の多クラス
3月リリースの機能¶
次の表は、新機能の一覧です。
目的別にグループ化された機能
| 名前 | 一般提供 | プレビュー |
|---|---|---|
| データ | ||
| Parquetファイルの取込みをサポート | ✔ | |
| ラングリングレシピのパブリッシュ時にスマートダウンサンプリングを実行 | ✔ | |
| モデリング | ||
| 多クラスモデリングと混同行列 | ✔ | |
| OTVエクスペリメントにおける10GBまでのデータセットのアップロード、モデリング、インサイト生成 | ✔ | |
| 予測とMLOps | ||
| 日本語テキストの特徴量ドリフトでのトークン化を改善 | ✔ | |
| カスタムモデルのトレーニングデータ割り当てを変更 | ✔ | |
| NVIDIA GPUでNeMo Guardrailsを使用した生成AI | ✔* | |
| DataRobotのサーバーレス予測環境でのリアルタイム予測 | ✔ | |
| ホストされたカスタム指標をカスタムジョブから作成 | ✔ | |
| 予測リクエストでの列フィルターの無効化 | ✔ | |
| Notebooks | ||
| Codespacesでのノートブックファイルシステムの管理 | ✔ | |
| アプリ | ||
| カスタムアプリケーションの共有 | ✔ | |
| レジストリでのカスタムアプリケーションの管理 | ✔ | |
| API | ||
| datarobot-mlopsパッケージの新しいインポートパス | ✔ | |
一般提供¶
Parquetファイルの取込みをサポート¶
AIカタログ、トレーニングデータセット、予測データセットにおいて、Parquetファイルの取込みが一般提供機能になりました。 サポートされるParquetファイルタイプは以下のとおりです。
- 単一のParquetファイル
- zip圧縮された単一のParquetファイル
- 複数のParquetファイル(別々のデータセットとして登録)
- zip圧縮された複数のParquetファイル(DataRobotで単一のデータセットを作成するためにマージ)
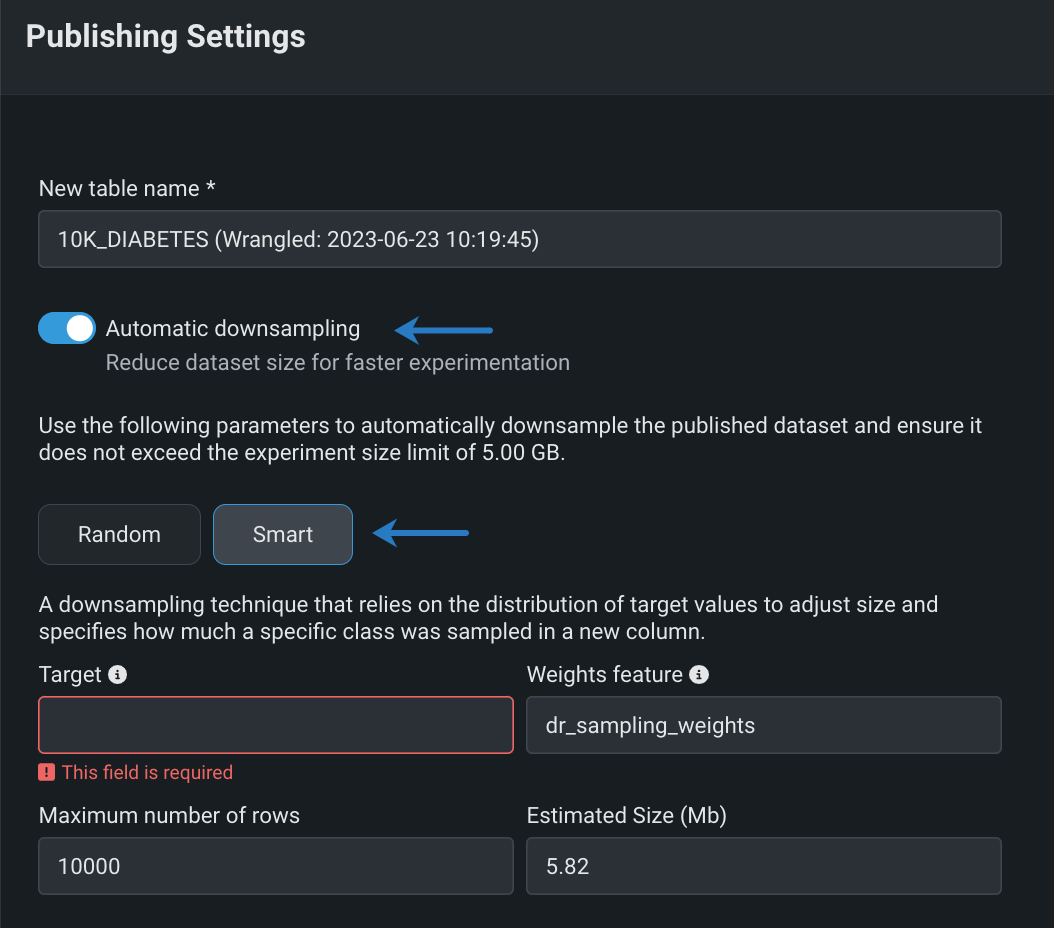
ラングリングレシピのパブリッシュ時にスマートダウンサンプリングを実行¶
ワークベンチでラングリングレシピを構築した後、パブリッシュ設定でスマートダウンサンプリングを有効にすると、出力データセットのサイズを縮小し、モデルトレーニングを最適化することができます。 スマートダウンサンプリングは、クラスごとにサンプルを層別化することでクラスの不均衡を考慮するだけでなく、精度を犠牲にせずにモデルの適合にかかる時間を短縮するデータサイエンスのテクニックです。
OTVエクスペリメントにおける10GBまでのデータセットのアップロード、モデリング、インサイト生成¶
OTV(時間外検定)エクスペリメントのスケーラビリティとユーザーエクスペリエンスを向上させるため、大規模データセットにスケーリングを導入しました。 分割手法として時間外検定を使用する場合、DataRobotは10GBほどのデータセットでもダウンサンプリングを行う必要がなくなりました。 代わりに、多段階のオートパイロットプロセスで、大幅に拡大された入力許容量に対応します。
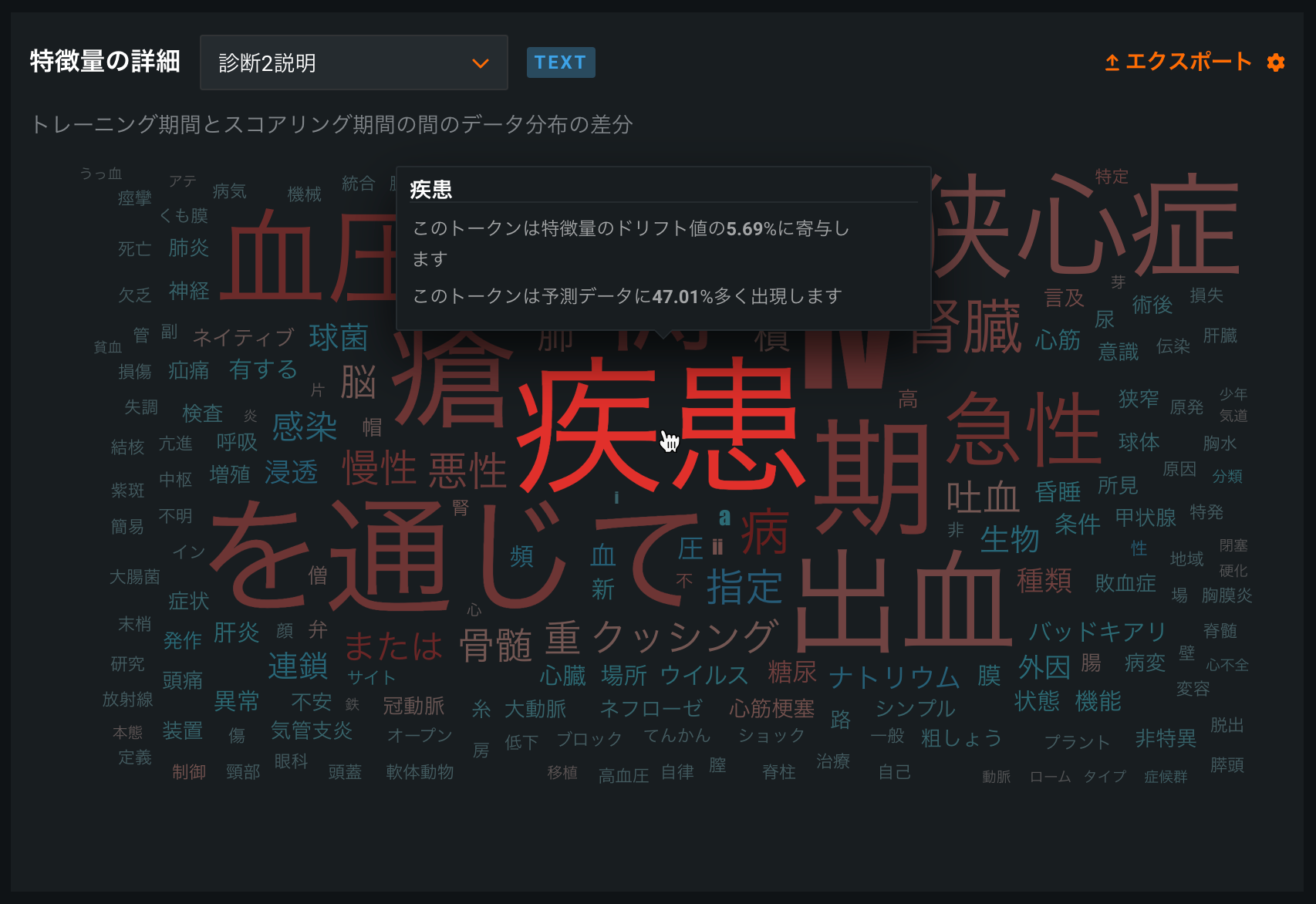
日本語テキストの特徴量ドリフトでのトークン化を改善¶
データドリフトタブの特徴量の詳細チャートのテキストトークン化が日本語のテキスト特徴量向けに改善され、MeCabでのトークン化による単語グラムベースのデータドリフト分析が実装されました。 さらに、日本語のテキスト特徴量で、デフォルトのストップワードフィルターが改善されました。
カスタムモデルのトレーニングデータ割り当てを変更¶
2024年4月から、カスタムモデルレベルでトレーニングデータを割り当てる使用非推奨の方法に代わって、(2023年3月リリースで発表されたとおり)カスタムモデルのバージョンにトレーニングデータが割り当てられるようになりました。 つまり、「カスタムモデルバージョンごと」の方法がデフォルトになり、「カスタムモデルごと」の方法は削除されました。 準備として、カスタムモデルへのトレーニングデータの追加に関するドキュメントで、手動変換の手順を確認できます。
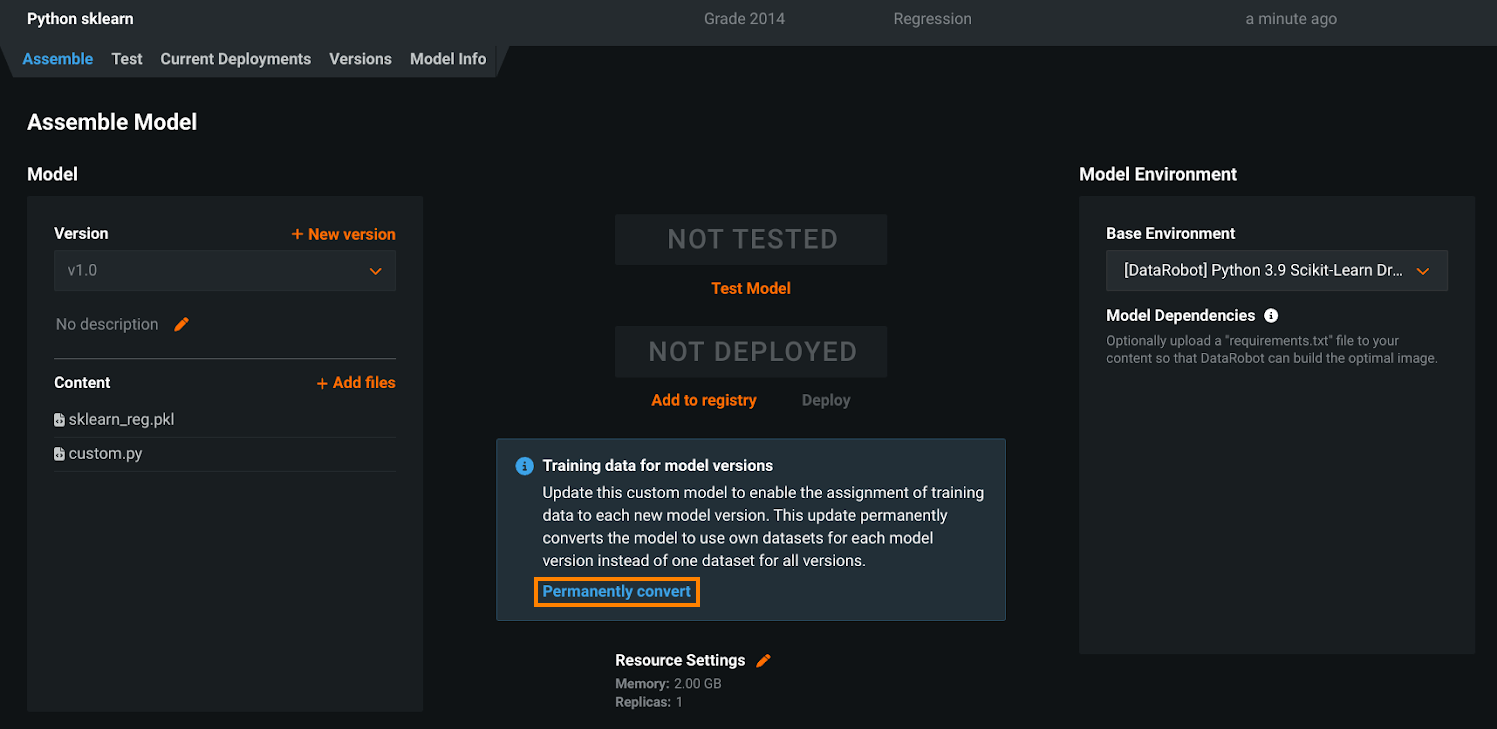
「カスタムモデルごと」の方法を使用した残りのカスタムモデルの自動変換は、使用非推奨期間が終了すると自動的に行われ、カスタムモデルのバージョンレベルでトレーニングデータが割り当てられます。 ほとんどの場合、何もする必要はありません。ただし、「カスタムモデルごと」の割り当て方法を使用していても変換されていないカスタムモデルに依存する自動化が残っている場合は、機能のギャップを避けるために、「カスタムモデルバージョンごと」の割り当て方法をサポートするように更新する必要があります。
割り当て方法の変更の概要については、カスタムモデルのトレーニングデータ割り当てを変更のドキュメントを参照してください。
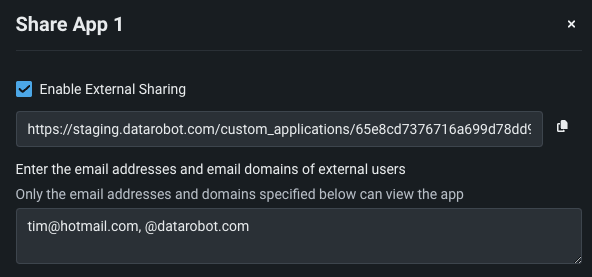
カスタムアプリケーションの共有¶
カスタムアプリケーションをDataRobotユーザーだけでなくDataRobot以外のユーザーとも共有できるため、作成したカスタムアプリケーションの利用範囲が広がります。 共有機能には、アプリワークショップのアクションメニューからアクセスできます。 カスタムアプリをDataRobot以外のユーザーと共有するには、外部共有を有効にするをオンに切り替えて、アプリへのアクセスを許可するメールドメインとアドレスを指定する必要があります。 共有設定を行うと、これらのユーザーと共有するためのリンクが提供されます。
Codespacesでのノートブックファイルシステムの管理¶
一般提供機能になりました。CodespacesがDataRobotのワークベンチに含まれ、特にDataRobot Notebooksで作業する際のコードファーストエクスペリエンスが向上しました。 Codespaceは、リポジトリまたはフォルダーファイルツリー構造に似ており、任意の数のファイルやネストされたフォルダーを含めることができます。 Codespace内では、複数のノートブックファイルやノートブック以外のファイルを同時に開いたり、表示したり、編集したりすることができます。 同じコンテナセッションで複数のノートブックを実行することもできます(各ノートブックは独自のカーネルで実行します)。
マネージドAIプラットフォームでは、codespacesのバックアップ機能と保持ポリシーを提供しています。 DataRobotは、セッションのシャットダウン時とcodespaceの削除時にcodespaceのボリュームのスナップショットを作成します。Codespaceのデータを復元したい場合に備えて、その内容を30日間保持します。
プレビュー¶
NVIDIA GPUでNeMo Guardrailsを使用した生成AI¶
DataRobotでNVIDIAを使用して、パフォーマンスの高速化を実現し、最高のオープンソースモデルとガードレールを活用することで、エンドツーエンドの生成AI (GenAI) 機能をすばやく構築できます。 DataRobotとNVIDIAの連携により、完全なエンドツーエンドの生成AI機能を提供する推論ソフトウェアスタックが構築されます。重要な機能がすぐに使えることで、パフォーマンス、ガバナンス、安全性が確保されます。
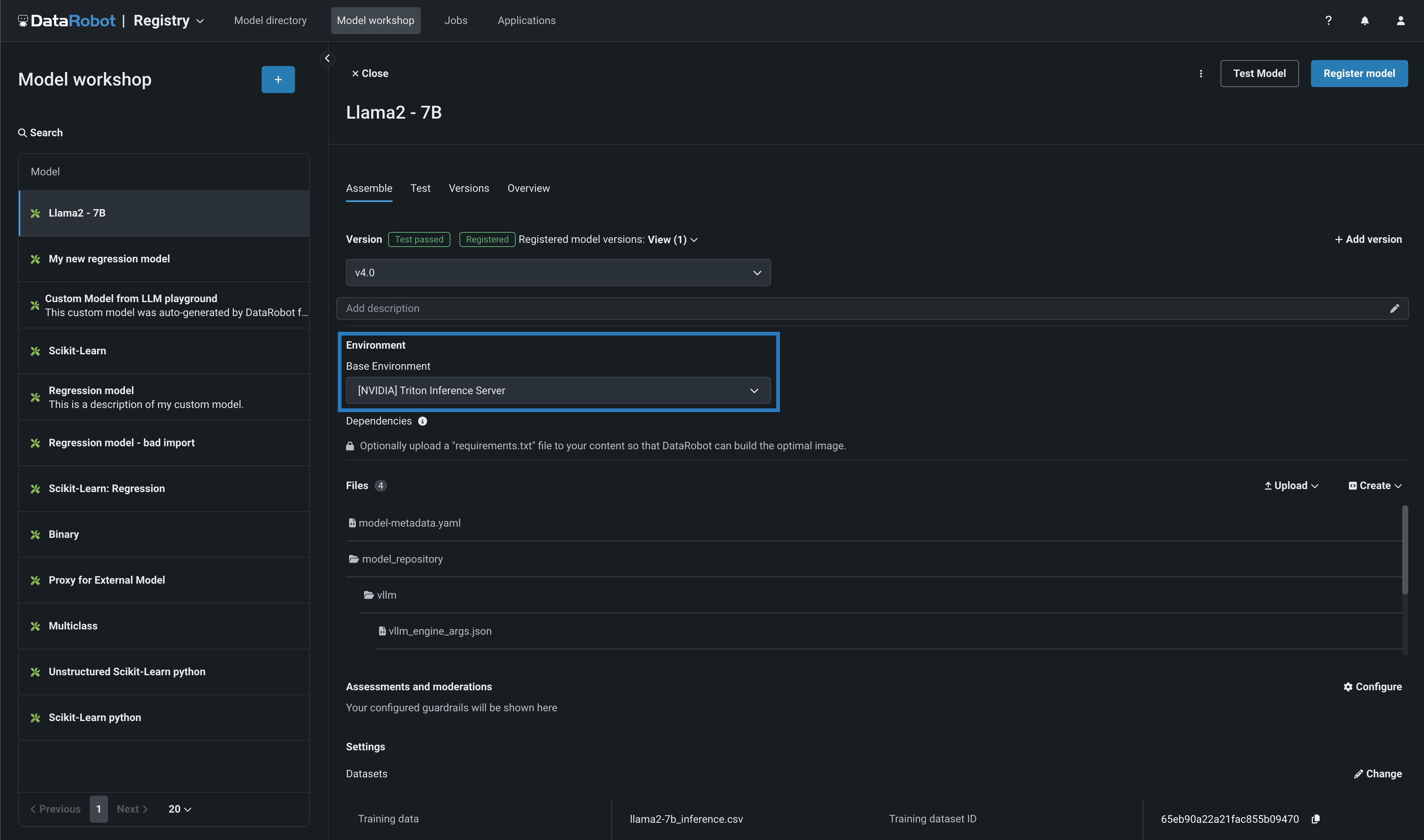
NextGen DataRobotのモデルワークショップでカスタム生成AIモデルを作成する際、基本環境として[NVIDIA] Triton Inference Server(vLLMバックエンド)を選択できます。 DataRobotにはNVIDIA Triton Inference Serverがネイティブに組み込まれており、GPUベースのモデルをNVIDIAデバイスに構築・デプロイする際に、特別なアクセラレーションを提供します。
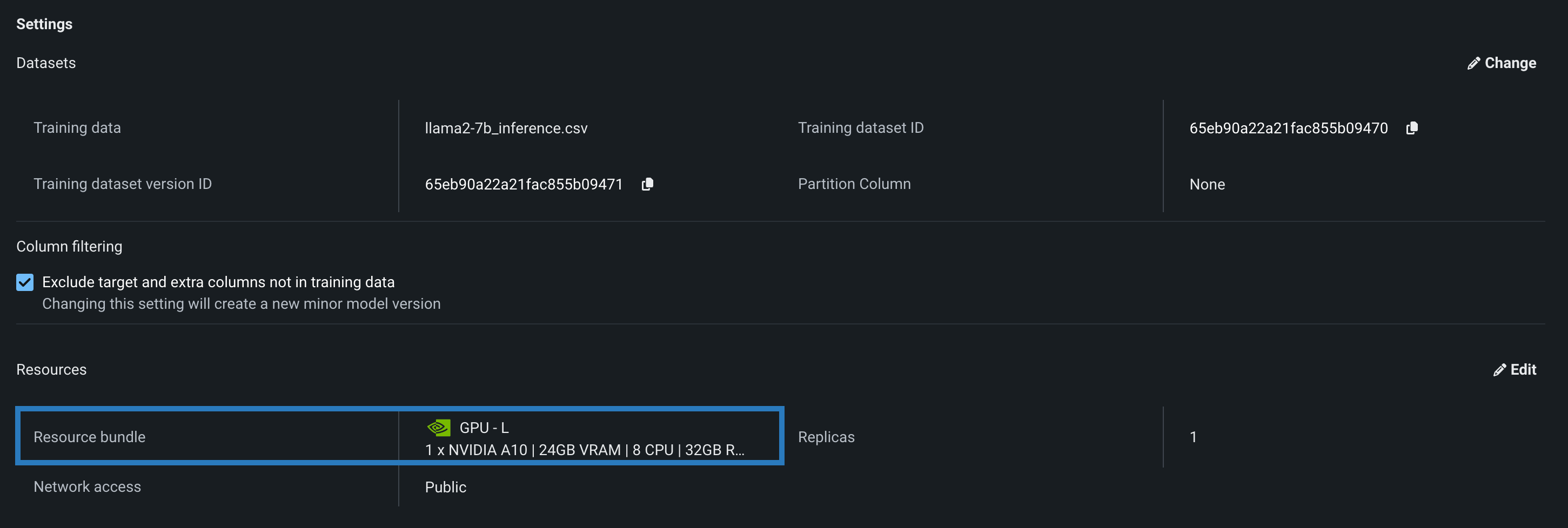
次に、カスタムモデルのリソース設定に移動して、DataRobotでの構築環境として利用可能なNVIDIAデバイスの範囲からリソースバンドルを選択できます。
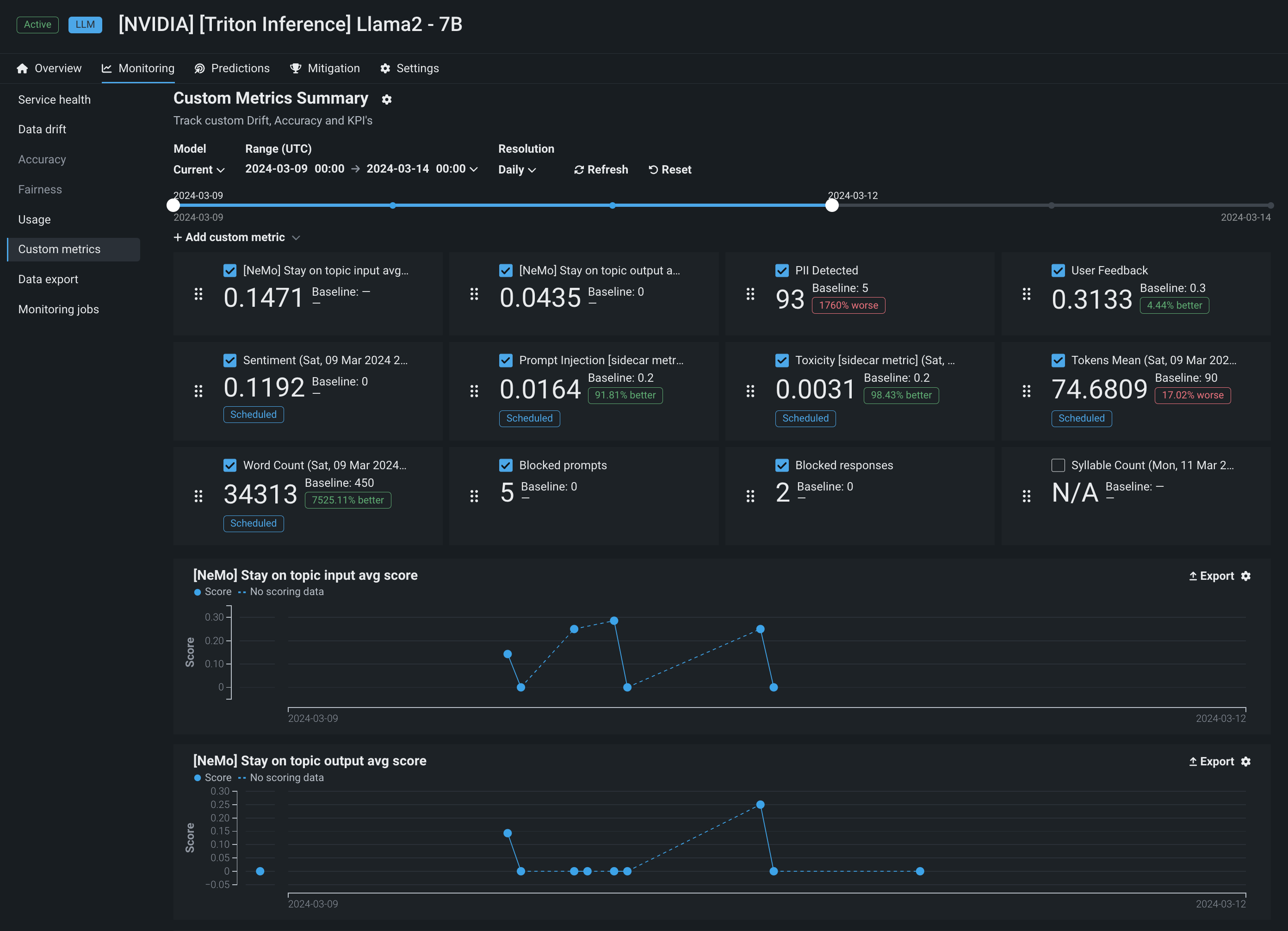
さらに、DataRobotには、NeMo Guardrailsとの連携により、カスタム指標を作成するための強力なインターフェイスも用意されています。 NeMoとの連携により、NeMoが提供する 「トピックに沿った」原則に違反した場合、プロンプトや補完をブロックする介入を用いて、モデルがトピックに沿った状態を維持できるようにする強力なレールが提供されます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:NVIDIAとNeMo Guardrailsの連携はプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
DataRobotのサーバーレス予測環境でのリアルタイム予測¶
DataRobotでサーバーレス予測環境を作成し、変更可能なコンピューティングインスタンス設定により、Kubernetesでスケーラブルなリアルタイム予測を行います。 Kubernetesでのリアルタイム予測のためにDataRobotのサーバーレス予測環境を作成するには、予測環境を追加する際に、プラットフォームをDataRobotサーバーレスに設定します。
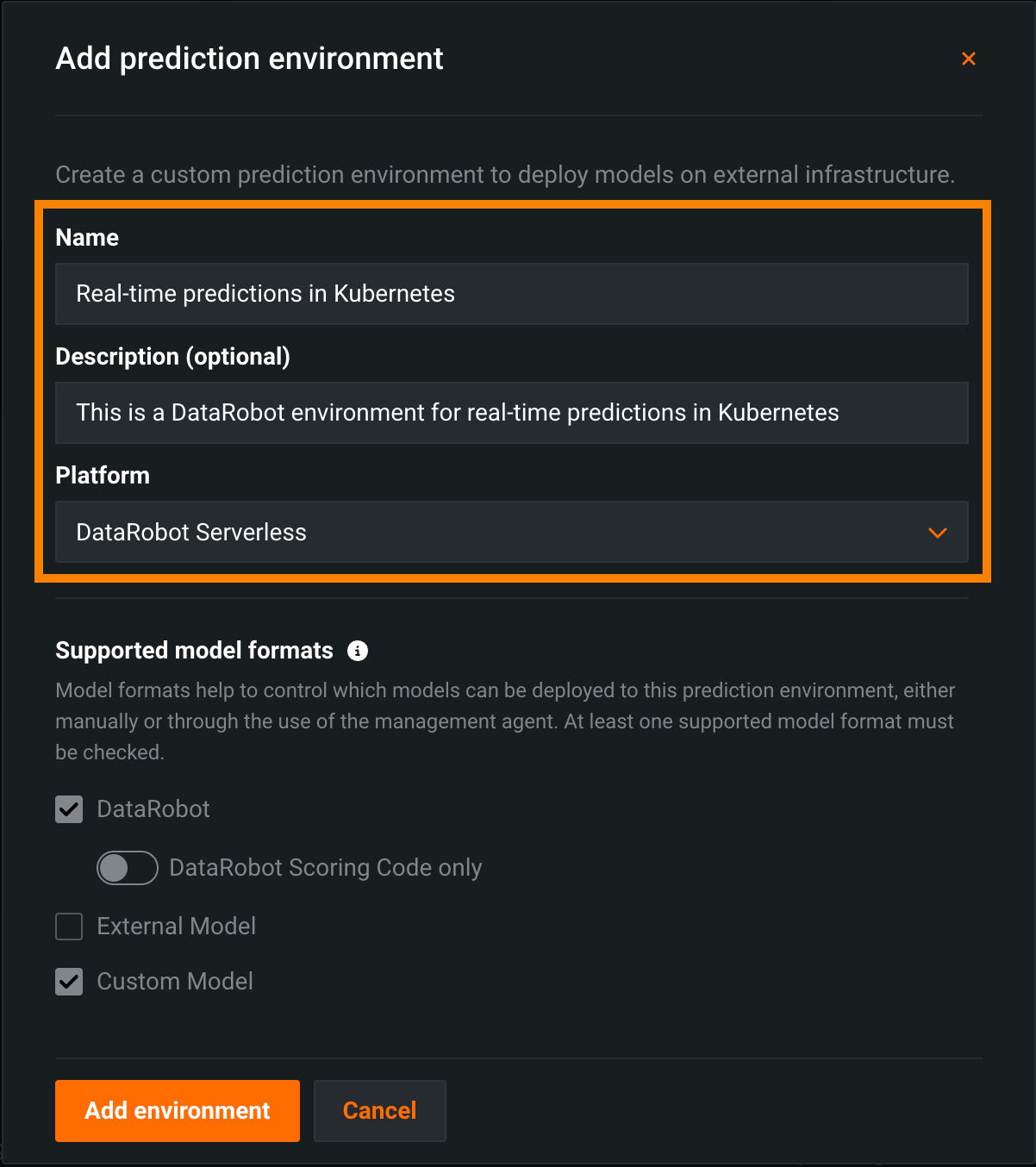
DataRobotのサーバーレス予測環境にモデルをデプロイすると、高度な予測設定でコンピューティングインスタンスの設定ができます。
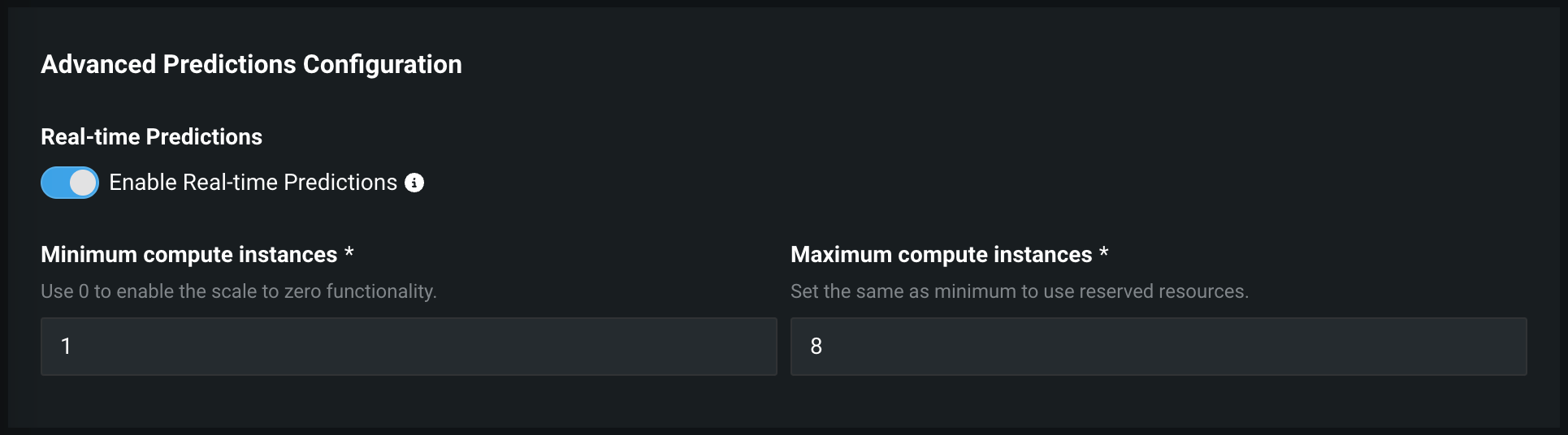
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ: K8s予測環境でリアルタイム(インタラクティブ)予測を有効にする、K8s予測環境でリアルタイムのGenAI予測を有効にする
ホストされたカスタム指標をカスタムジョブから作成¶
レジストリで新しいカスタムジョブを作成すると、ホストされた新しいカスタム指標を作成したり、ギャラリーから指標を追加したりできます。 NextGenインターフェイスで、レジストリ > ジョブをクリックし、+ 新規追加(またはカスタムジョブパネルが開いている場合は ボタン)をクリックして、次のカスタム指標タイプのいずれかを選択します。
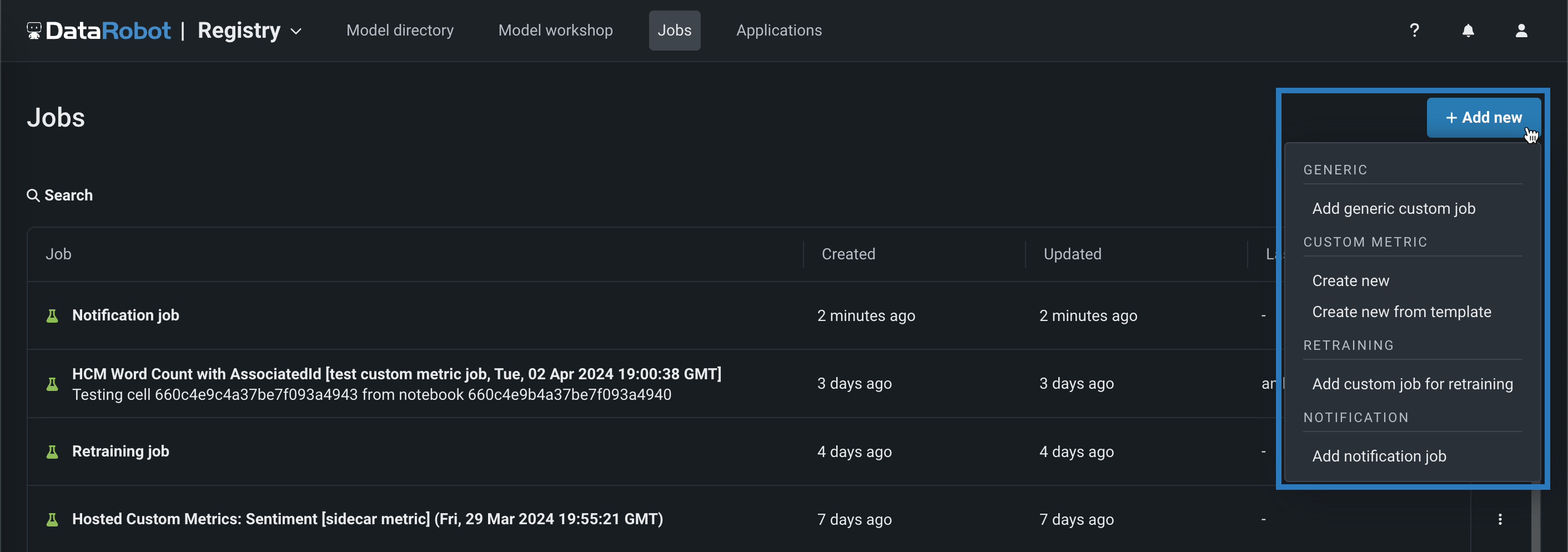
| カスタムジョブタイプ | 説明 |
|---|---|
| 汎用カスタムジョブを追加 | カスタムジョブを追加して、モデルとデプロイの自動化(たとえば、カスタムテスト)を実装します。 |
| 新しく作成 | 新しいホストされたカスタム指標のカスタムジョブを追加します。カスタム指標設定を定義し、指標をデプロイに関連付けます。 |
| テンプレートから新規作成 | DataRobotによって提供されるテンプレートからカスタム指標のカスタムジョブを追加して、指標をデプロイに関連付け、ベースラインを設定します。 |
レジストリ > ジョブタブでカスタム指標ジョブを作成したら、カスタム指標ジョブのアセンブルタブで、 接続されたデプロイパネルにアクセスできます。 + デプロイに接続をクリックし、カスタム指標名を定義してから、デプロイIDを選択して、指標をデプロイにリンクします。
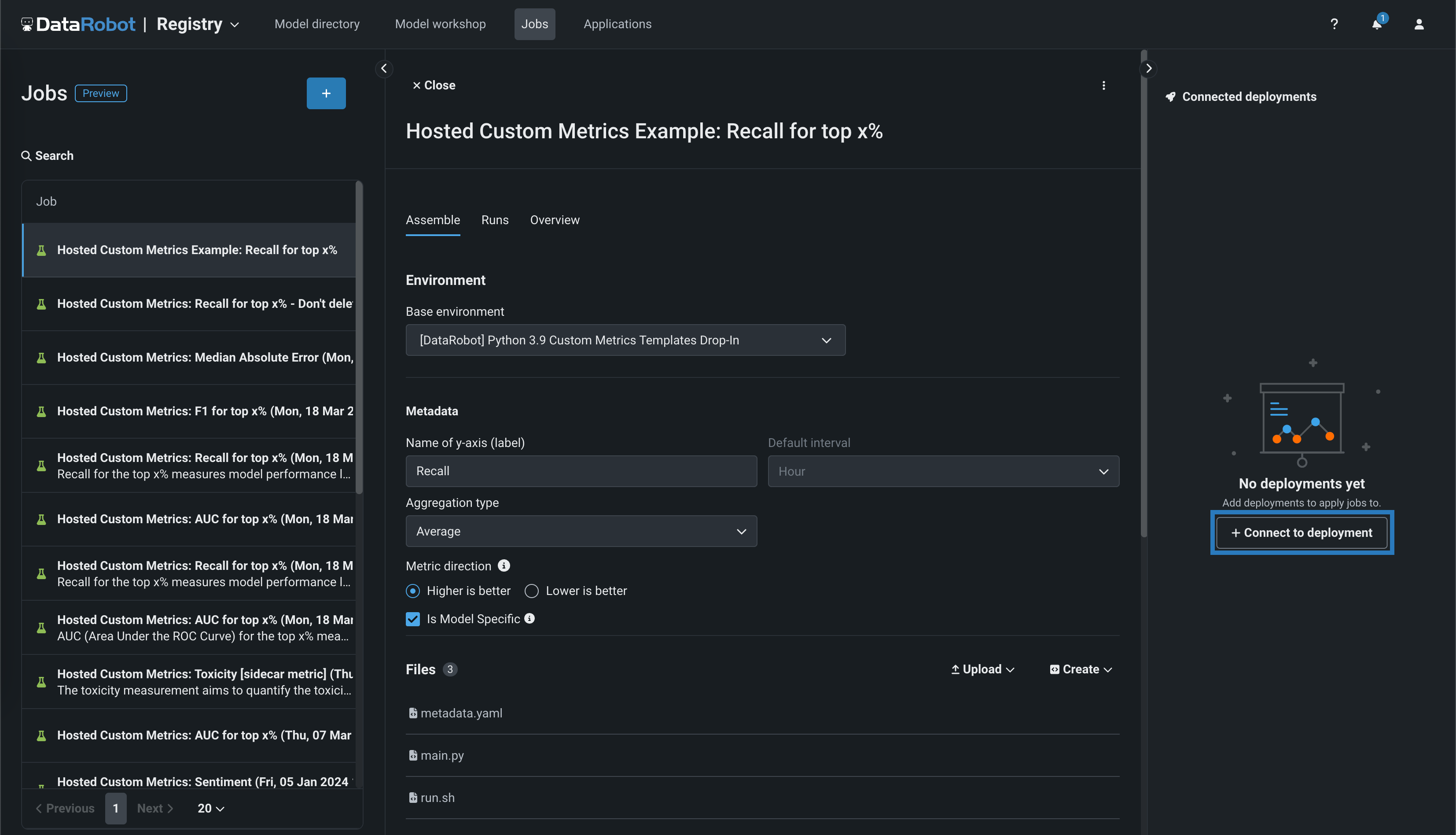
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:ホストされたカスタム指標を有効にする、Notebooksでカスタム環境を有効にする
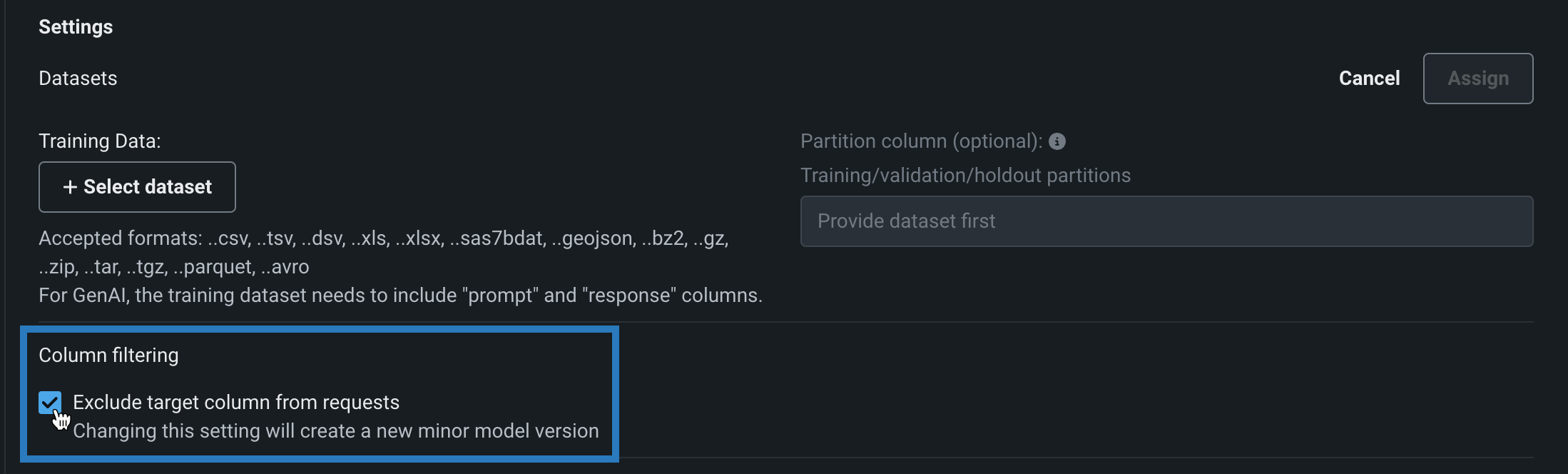
予測リクエストでの列フィルターの無効化¶
カスタムモデルを構築する際、カスタムモデルによる予測での列フィルターを有効および無効にすることができます。 選択したフィルター設定は、カスタムモデルの テストやデプロイの際に同様に適用されます。 デフォルトでは、ターゲット列は予測リクエストから除外されます。また、トレーニングデータが割り当てられている場合、トレーニングデータセットに存在しない追加の列は、モデルに送信されるスコアリングリクエストから除外されます。 あるいは、予測データセットに欠損列がある場合、欠損している特徴量を通知するエラーメッセージが表示されます。
カスタムモデルを構築する場合、この列フィルターを無効にすることができます。 モデルワークショップでカスタムモデルを開いて、アセンブルタブをクリックし、設定セクションの列フィルターで、リクエストからターゲット列を除外をオフにします(または、トレーニングデータが割り当てられている場合は、ターゲット列とトレーニングデータにない余分な列を除外をオフにします)。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ: カスタムモデルの予測で特徴量のフィルターを有効にする
レジストリでのカスタムアプリケーションの管理¶
プレビュー機能です。NextGenレジストリの「アプリケーション」ページには、ユーザーが利用できる構築済みのカスタムアプリケーションとアプリケーションソースがすべて表示されます。 アプリケーションのソースを作成できるようになりました。これには、構築したいカスタムアプリケーションのファイル、環境、ランタイムパラメーターが含まれます。 これらのソースから直接カスタムアプリケーションを構築できます。 アプリケーションページを使って、共有や削除を行うことで、アプリケーションを管理することもできます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:カスタムアプリケーションワークショップを有効にする
API¶
datarobot-mlopsパッケージの新しいインポートパス¶
Pythonパッケージmlops.datarobot-mlopsおよびdatarobot-mlops-connected-clientで、インポートパスがimport datarobot.mlops.mlopsからimport datarobot_mlops.mlopsに変更されています。 これにより、DataRobotパッケージとMLOpsパッケージが同じPython環境にインストールされたときに競合する問題が修正されました。 このインポートは手動で更新する必要があります。 以下の例は、両方のインポートパスを試して互換性のあるコードに更新する方法を示しています。
try:
from datarobot_mlops.mlops import MLOps
except ImportError:
from datarobot.mlops.mlops import MLOps
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。