2024年4月¶
2024年4月24日
このページでは、新たにリリースされ、DataRobotのSaaS型シングル/マルチテナントAIプラットフォームで利用できる機能についてのお知らせと、追加情報へのリンクを掲載しています。 リリースセンターからは、次のものにもアクセスできます。
注目の新機能¶
ベクターデータベースおよびLLMプレイグラウンド機能の一般提供を開始¶
2024年4月のデプロイより、DataRobotでは、生成AI(GenAI)のベクターデータベース(VDB)とLLMプレイグラウンドの機能が一般提供されました。 プレミアム機能であるGenAIは、2023年11月に初めて導入され、VDBの作成、プレイグラウンドでのモデルの比較、LLMブループリントのデプロイといった機能を備えていました。 一般提供版のVDBビルダーとLLMプレイグラウンドは、操作性が改善され、データをDataRobotのGenAIフローに取り込み、モデルを本番環境に投入することができます。 以下を含む多くの機能強化を行いました。
-
LLMとのチャットの柔軟性が向上(たとえば、LLMにプロンプトを送る際にチャットのコンテキストをどのように使用するかを制御できるようになりました)。
-
複数のLLMとの会話を整理および分けるために、プレイグラウンドに「チャット」を追加。
-
プレイグラウンドを簡単に共有し、フィードバックを収集する共有機能。そのフィードバックをAIアクセラレーターに渡して、GCPまたはAWSで微調整を行い、そのモデルをDataRobotに戻します。
-
評価とモデレーションの評価指標の設定および適用。
-
トレースログ。LLMの回答生成に使用されたすべてのコンポーネントとプロンプティングアクティビティを確認できます。
-
引用レポート。ベクターデータベースへのプロンプト送信時にLLMが検索したドキュメントを簡単に把握できます。
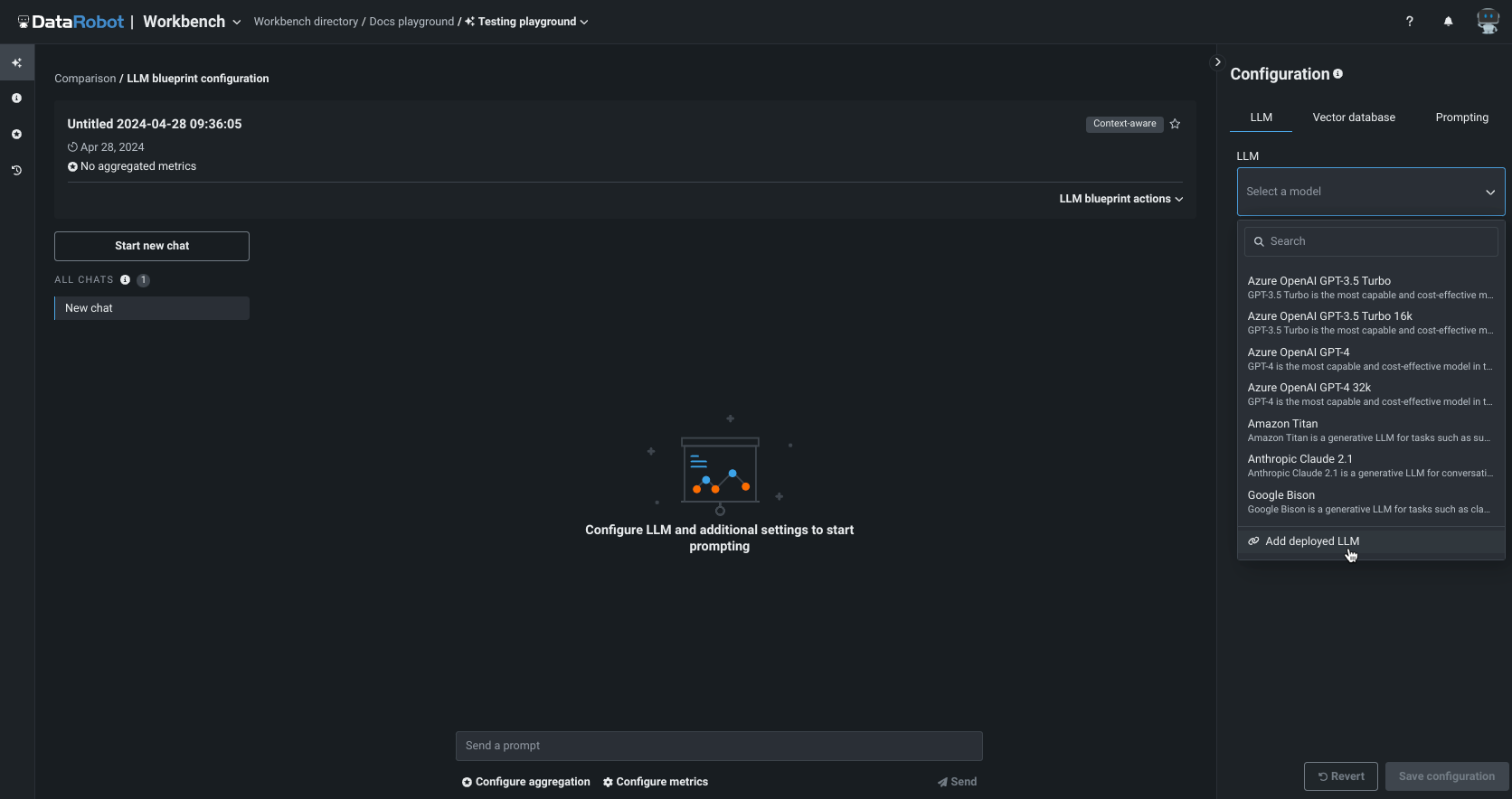
NextGenコンソールのレイアウトを一新¶
今回リニューアルされたNextGenコンソールでは、重要な監視、予測、バイアス軽減の各機能を、新しく直感的なレイアウトのモダンなユーザーインターフェイスで提供します。
Video: NextGen Console
この新しくなったレイアウトにより、ワークベンチでのモデルエクスペリメントやレジストリでのモデル登録から、コンソールでのモデルの監視と管理へシームレスに移行できます。また、DataRobot Classicの機能も引き続き利用できます。
詳しくはドキュメントをご覧ください。
4月リリースの機能¶
次の表は、新機能の一覧です。
目的別にグループ化された機能
_* プレミアム機能__
一般提供¶
NVIDIA RAPIDS GPUで高速化されたライブラリを提供開始¶
このデプロイでは、NVIDIA RAPIDSを使用したノートブックが導入されました。それにより、データ準備やモデリングのニーズに合わせて、GPUを使用したワークフローを作成できます。 RAPIDSは、GPUで高速化されたデータサイエンスおよびAIライブラリのスイートであり、一般的なオープンソースデータツールに対応するAPIを備えています。
シングルテナントSaaS¶
DataRobotは、公衆インターネット接続のネットワークオプションを備えた、シングルテナントSaaSソリューションをリリースしました。 この機能強化により、DataRobotのAI機能をシームレスに活用しながら、ウェブ上で安全に接続し、これまでにない柔軟性とスケーラビリティを実現できます。
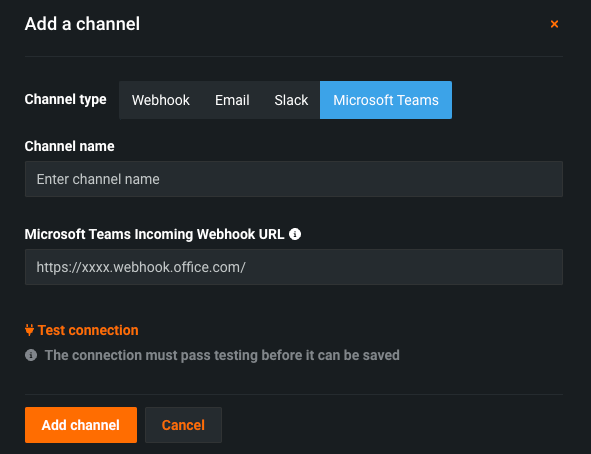
Microsoft Teams通知チャネルの追加¶
管理者はMicrosoft Teamsの通知チャネルを設定できるようになりました。 通知チャネルは、管理者が作成した通知配信メカニズムです。 各種類の通知には複数のチャネルを設定することができます(デプロイ関連イベントのURLを含むWebhook、すべてのプロジェクト関連イベントのWebhookなど)。
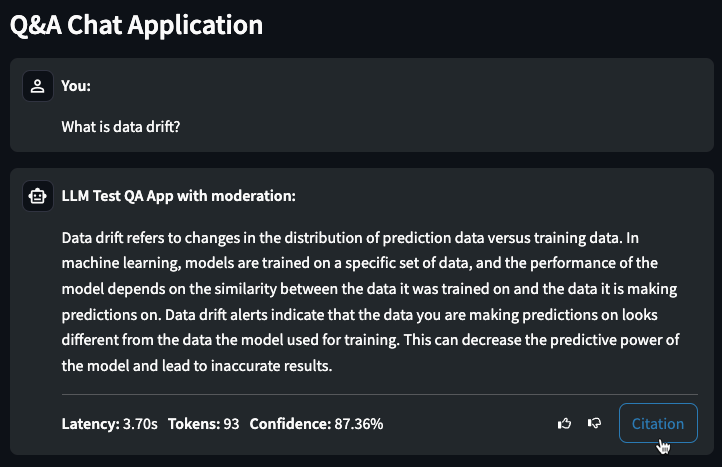
チャット生成Q&Aアプリケーションの構築と使用¶
プレミアム機能です。DataRobotでチャット生成の Q&Aアプリケーション を作成し、ナレッジベースのQ&Aユースケースを探索しながら、生成AIを活用してビジネス上の意思決定を繰り返し行い、ビジネス価値を示すことができます。 Q&Aアプリは、構築したLLMモデルの結果をプロトタイプ化、調査、および共有するための直感的で応答性に優れた方法を提供します。 Q&Aアプリにより、引用に裏打ちされた生成AIの会話が可能になります。 さらに、DataRobot以外のユーザーとアプリを共有して、使いやすさを広めることもできます。
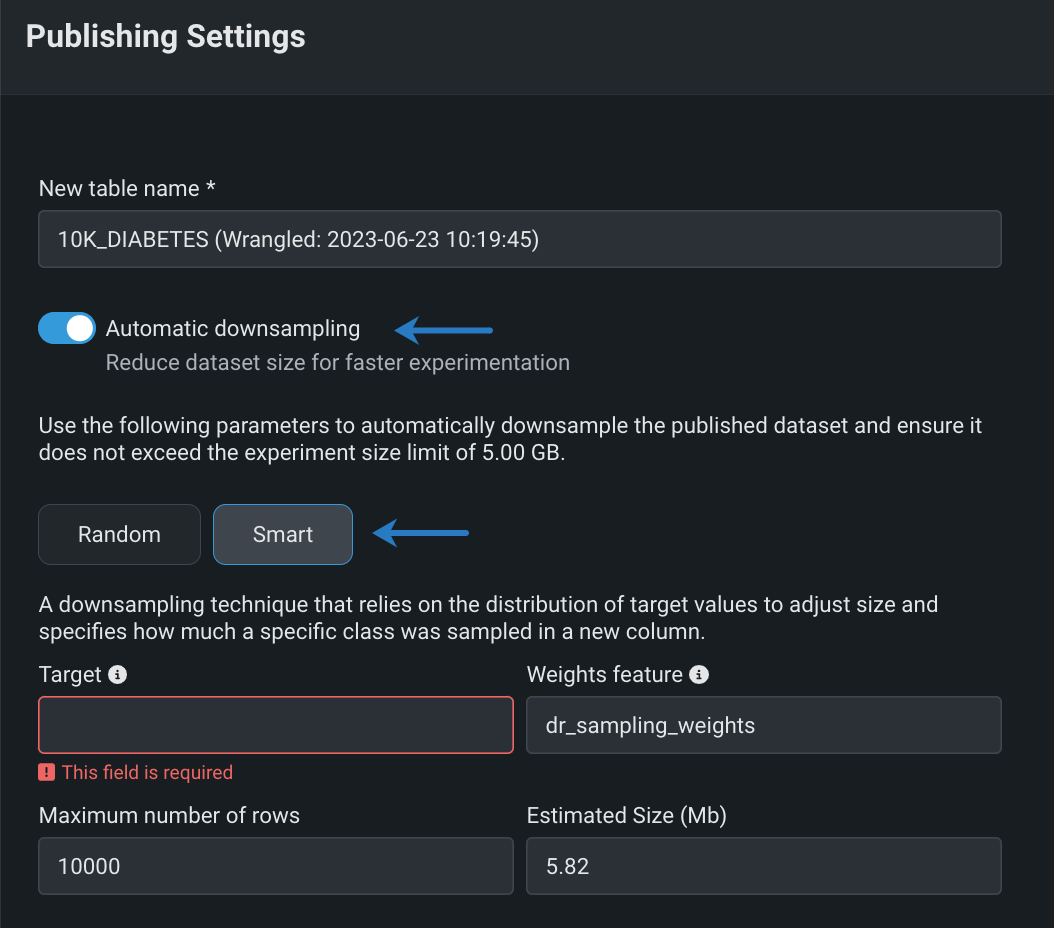
ラングリングレシピのパブリッシュ時にスマートダウンサンプリングを実行¶
ワークベンチでラングリングレシピを構築した後、パブリッシュ設定でスマートダウンサンプリングを有効にすると、出力データセットのサイズを縮小し、モデルトレーニングを最適化することができます。 スマートダウンサンプリングは、クラスごとにサンプルを層別化することでクラスの不均衡を考慮するだけでなく、精度を犠牲にせずにモデルの適合にかかる時間を短縮するデータサイエンスのテクニックです。
ネイティブDatabricksコネクターを追加¶
AzureやAWSでDatabricksのデータにアクセスできるネイティブDatabricksコネクターが、DataRobotで一般提供されました。 この新しいコネクターでは、パフォーマンスの向上に加えて、次のことが可能になります。
- データ接続を作成して設定する。
- サービスプリンシパルによる接続の認証と、セキュアな設定によるサービスプリンシパルの資格情報の共有。
- ユースケースにDatabricksデータセットを追加する。
- Databricksのデータセットをラングリングし、Databricksにレシピをパブリッシュして、データレジストリで出力をマテリアライズ。
- パブリックPython APIクライアントを使用して、Databricksコネクター経由でデータにアクセスする。
ネイティブAWS S3コネクターを追加¶
新しいAWS S3コネクターが、DataRobotで一般提供されました。 このコネクターでは、パフォーマンスの向上に加えて、ワークベンチでのAWS S3のサポートを有効にし、次のことが可能になります。
- データ接続を作成して設定する。
- ユースケースにAWS S3データセットを追加する。
ワークベンチでのレシピ管理を改善¶
このリリースでは、ワークベンチでのデータラングリングに対して以下の機能強化が行われています。
- ユースケースでデータセットをラングリングする際(同じデータセットを再度ラングリングする場合も含む)、操作を追加したかどうかに関係なく、データタブにレシピのコピーが作成されて保存されます。 その後、レシピを変更するたびに、変更内容が自動的に保存されます。 さらに、保存されたレシピを開いて変更を続けることができます。
- ユースケースにおいて、データセットタブはデータタブに置き換えられ、データセットとレシピの両方が表示されるようになりました。 また、データセットとレシピをすばやく区別できるように、データタブに新しいアイコンが追加されました。
- ラングリングセッション中に、将来レシピを再ラングリングする際に役立つ名前と説明をレシピに追加します。
NextGenのレジストリを一般提供¶
NextGenで一般提供を開始しました。レジストリは、DataRobotで使用されるさまざまなモデルのための組織的ハブです。 レジストリ > モデルディレクトリページには、_登録されたモデル_が一覧表示され、それぞれにデプロイ可能なモデルパッケージが_バージョン_として含まれています。 これらの登録モデルには、DataRobotのモデル、カスタムモデル、外部モデルをバージョンとして含めることが可能で、予測モデルや生成モデルの進化を追跡し、一元管理することができます。
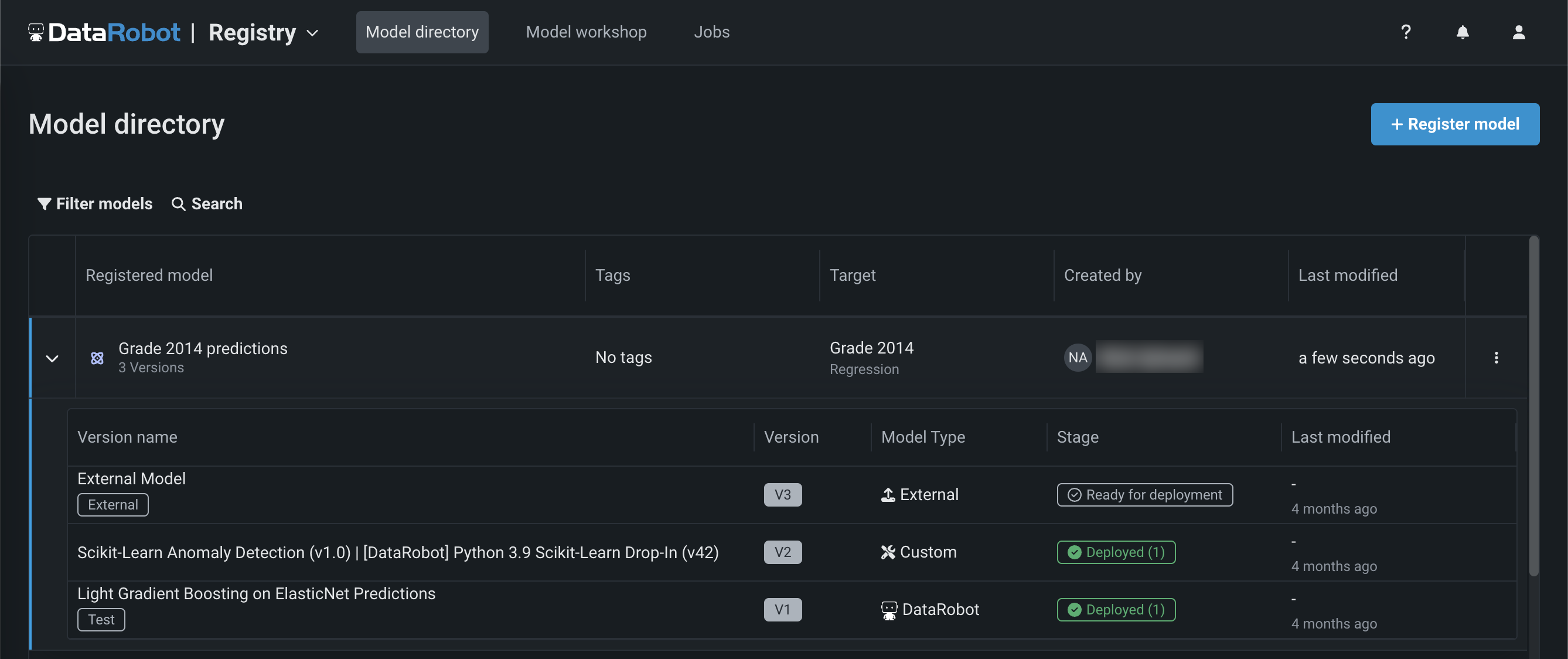
このリリースから、レジストリは登録されているモデルバージョンのシステムステージと変更可能なユーザーステージを追跡します。 登録モデルのバージョンのステージ に変更を加えると、システムイベントが生成されます。 これらのイベントは通知ポリシーで追跡できます。
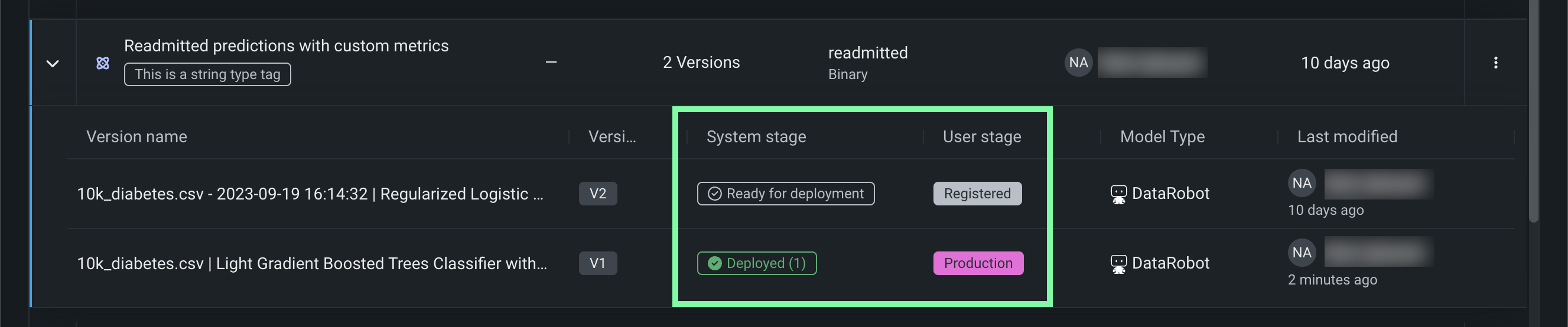
レジストリ > モデルワークショップのページでは、カスタムモデルを作成、テスト、登録、デプロイするためのモデルアーティファクトを、一元化されたモデル管理・デプロイハブにアップロードすることができます。 カスタムモデルは、DataRobotのMLOps機能のほとんどをサポートする事前トレーニング済みのユーザー定義モデルです。 DataRobotは、Python、R、Javaを始めとするさまざまなコーディング言語で構築されたカスタムモデルをサポートします。 DataRobot以外でモデルを作成し、DataRobotにアップロードする場合は、モデルワークショップでモデルの内容とモデル環境を定義します。
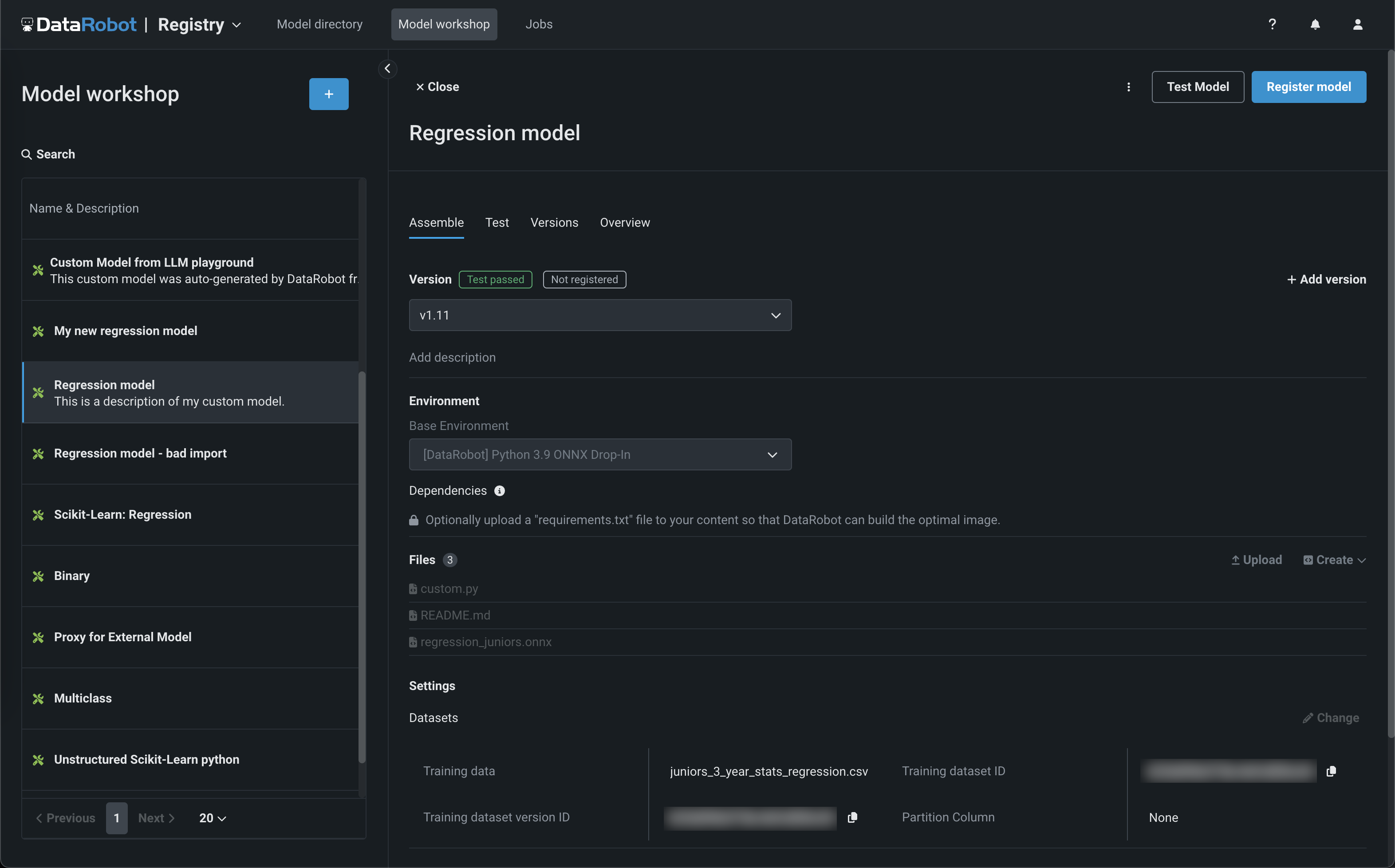
レジストリ > ジョブページでは、ジョブを使用して、モデルとデプロイのために自動化(カスタムテスト、指標、通知など)を実装します。 各ジョブは自動化されたワークロードとして機能し、終了コードによって正常終了か失敗かが判定されます。 作成したカスタムジョブは、1つ以上のモデルまたはデプロイで実行できます。 カスタムジョブによって定義された自動ワークロードは、DataRobotのパブリックAPIを使用して、予測リクエスト、入力の取得、出力の保存を行うことができます。
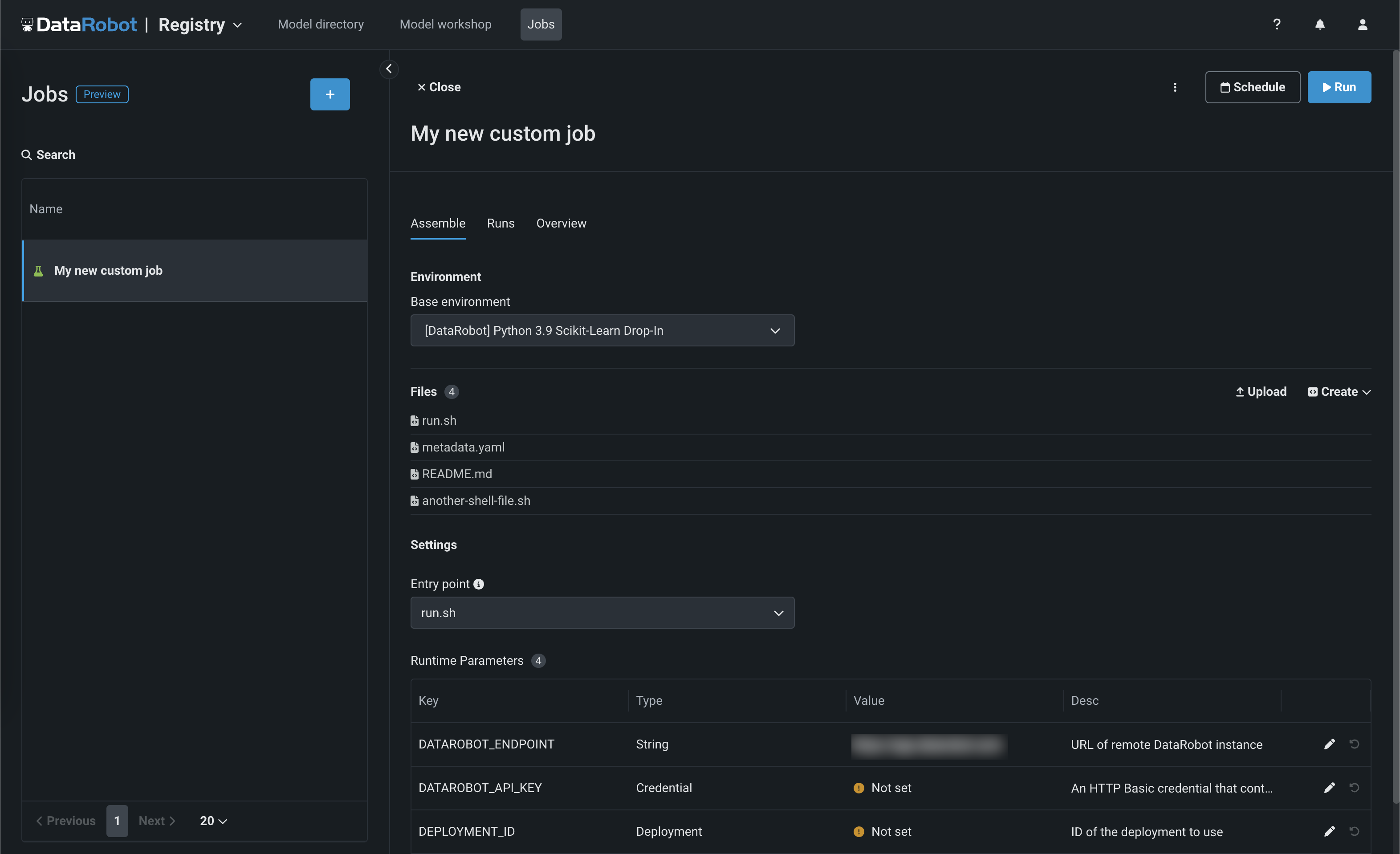
このリリースから、カスタムジョブにリソース設定セクションが含まれています。このセクションでは、カスタムジョブの実行に使用するリソースと、カスタムジョブのエグレストラフィックを設定できます。
詳しくはドキュメントをご覧ください。
レジストリのグローバルモデル¶
レジストリ(NextGen)とモデルレジストリ(Classic)から、予測ユースケースや生成ユースケースのために事前にトレーニングされたグローバルモデルをデプロイすることができます。 これらの高品質でオープンソースのモデルは、トレーニング済みですぐにデプロイできるため、DataRobotのインストール後すぐに予測を行うことができます。 GenAIのユースケースでは、個人を特定できる情報(PII)の識別、ゼロショット分類、感情分類のためのグローバルモデルが用意されています。
カスタムモデルのランタイムパラメーター¶
model-metadata.yamlファイル内のruntimeParameterDefinitionsでランタイムパラメーターを定義し、カスタムモデルのアセンブル タブ内のランタイムパラメーターセクションで管理します。
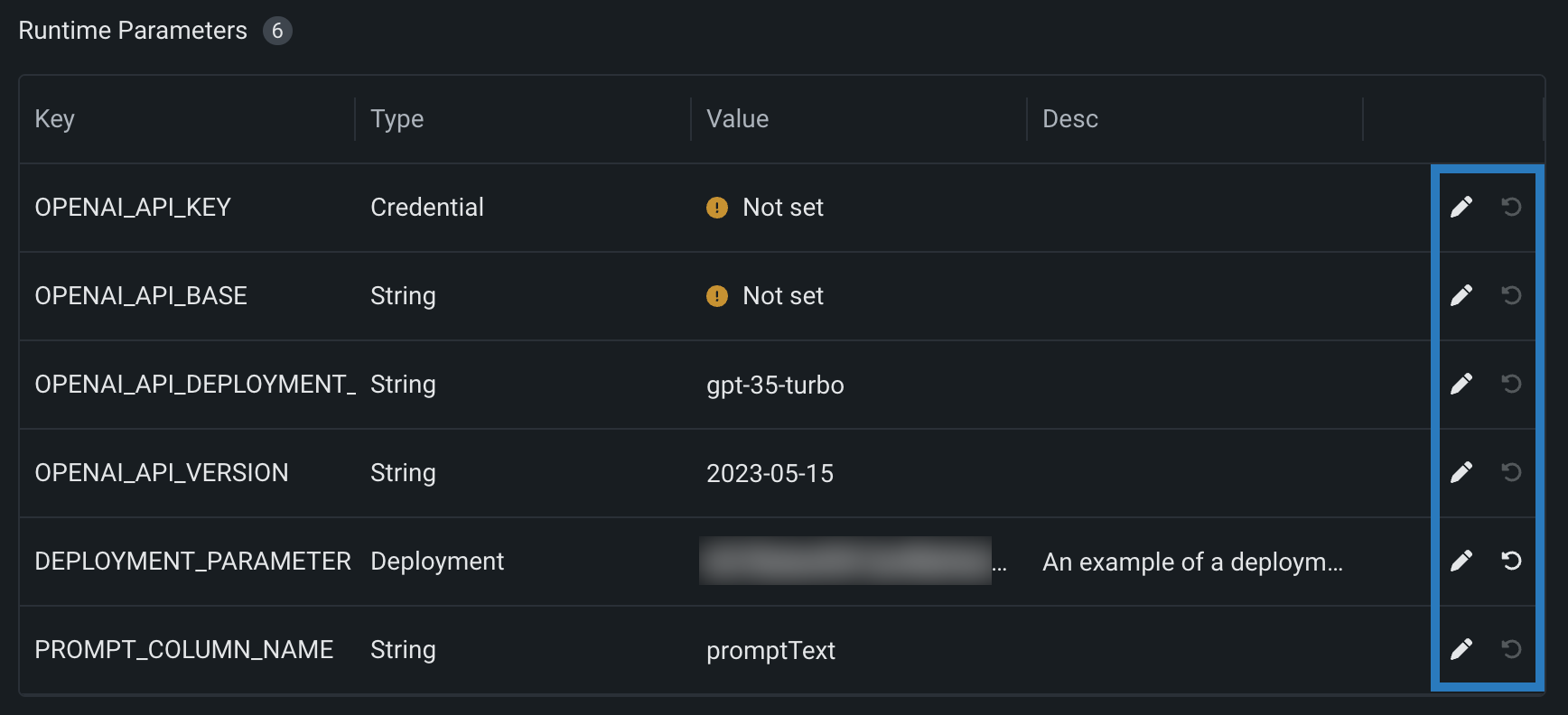
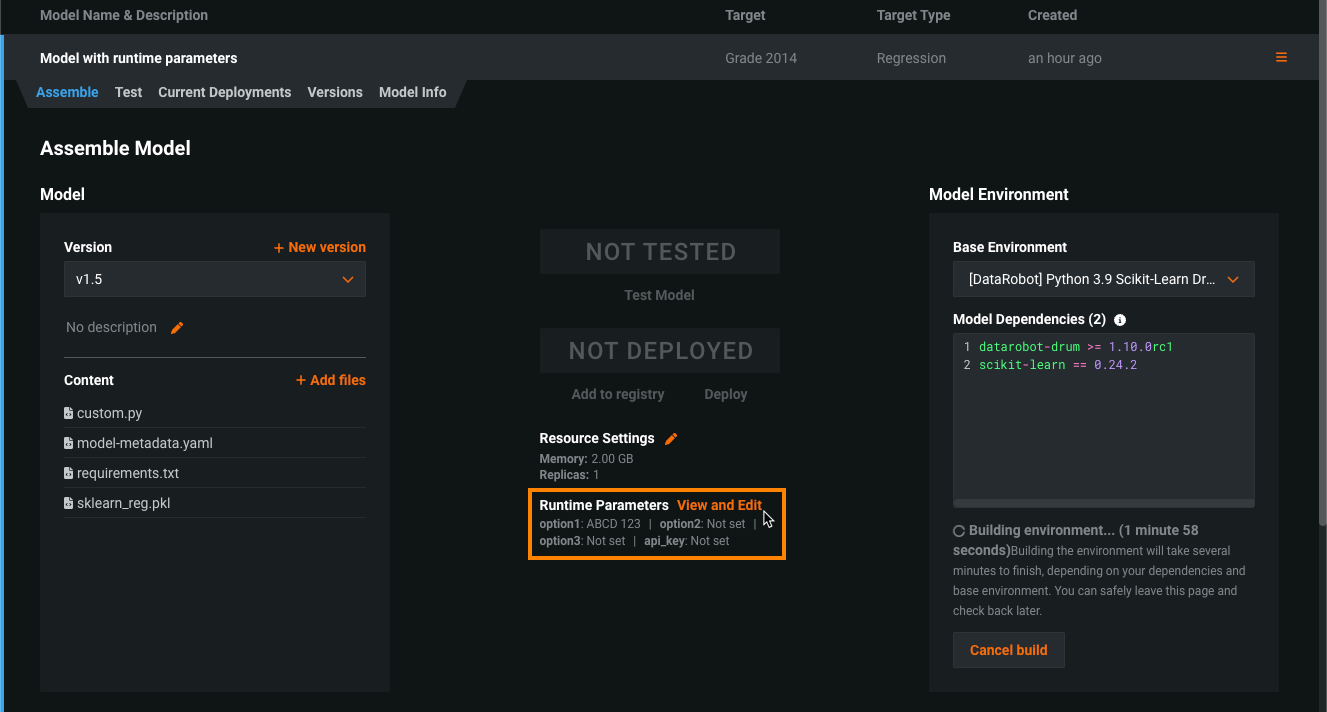
defaultValueのない定義で、ランタイムパラメーターにallowEmpty: falseがある場合は、カスタムモデルを登録する前に値を設定する必要があります。
詳細については、ClassicのドキュメントまたはNextGenのドキュメントをご覧ください。
デプロイの通知ポリシー¶
通知ポリシーの作成を通じてデプロイ通知を設定すると、通知チャネルやテンプレートを設定したり組み合わせたりできます。 通知テンプレートは通知をトリガーするイベントを決定し、チャネルは通知されるユーザーを決定します。 使用可能な通知チャネルのタイプは、Webhook、メール、Slack、Microsoft Teams、ユーザー、グループ、カスタムジョブです。 デプロイに通知ポリシーを作成する場合、ポリシーテンプレートを変更せずに使用することも、新しいポリシーのベースとして変更を加えることもできます。 また、完全に新規の通知ポリシーを作成することもできます。
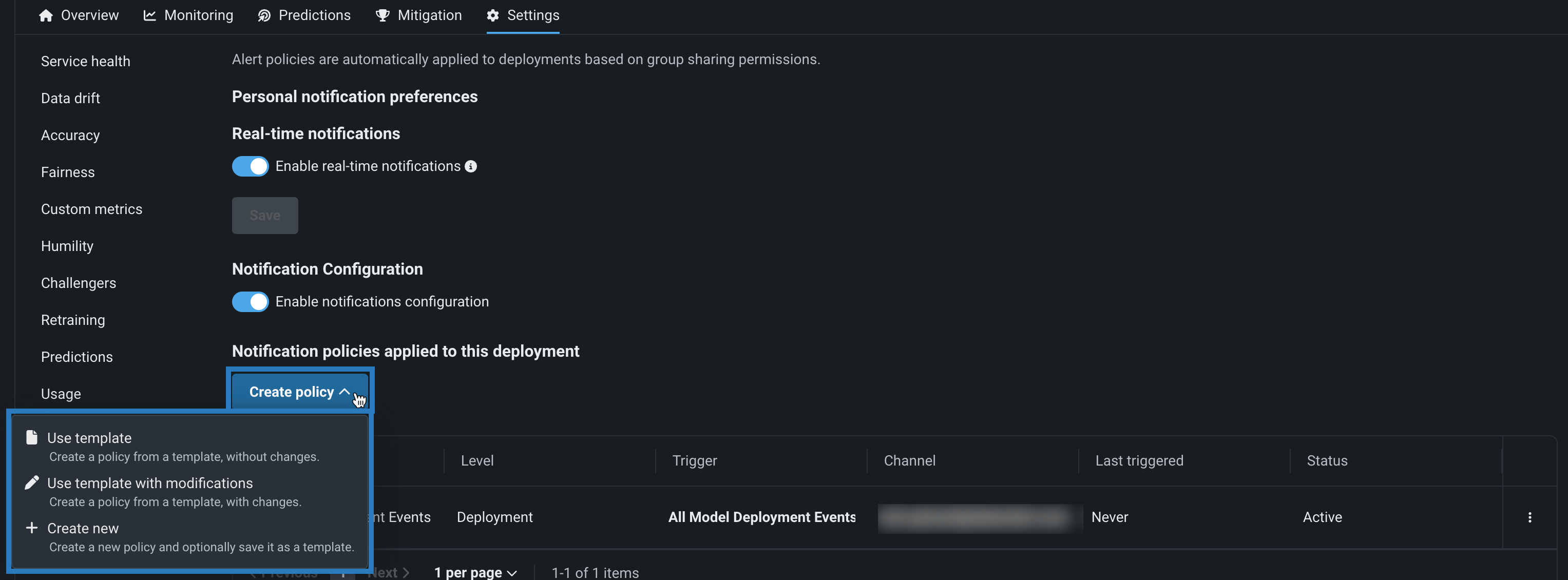
プレビュー¶
LLMのブループリントとデプロイでのLLMの評価およびモデレーション指標¶
LLM評価ツールを使用すると、LLMブループリントのパフォーマンスと、運用準備が整っているかどうかをより正確に把握できます。 たとえば、評価指標は、プロンプトインジェクションや、悪意のある、有害な、または不適切なプロンプトや回答について、組織が報告するのに役立ちます。 多くの評価指標は、プレイグラウンドで構築されたLLMと、デプロイされたガードモデルを結びつけます。 モデレーションは、プロンプトインジェクション、PIIの漏洩、トピックから外れたディスカッションが検出された場合に介入でき、組織が最も一般的なLLMのセキュリティ問題に対処できるようにします。
現在はプレビュー版で、プレイグラウンドから利用できるツールでは、以下のことができます。
-
評価指標を設定して、プレイグラウンドでのLLMのパフォーマンスを把握し、最終モデルをモデルワークショップ](deploy-llm){ target=_blank }に送信できます。
-
プロンプトインジェクション、PIIの漏えい、トピックの維持など、最も一般的なLLMのセキュリティ問題を防ぐためのガードレールを追加できます。
-
評価データセットを取り込むことができます。 または、ベクターデータベースに基づいて評価データセットを自動的に生成し、プレイグラウンドでの評価時に活用することもできます。
-
NVIDIAのNeMo Guardrailsのような一般的なガードレールフレームワークと連携できます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:GenAIの機能はプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。
SHAPベースの個々の予測説明をワークベンチに追加¶
SHAPベースの説明は、特定の予測が平均とは異なることに各特徴量がどの程度関与しているかを推定するため、何が予測の根拠となっているかを行単位で理解するのに役立ちます。 ワークベンチに導入されたことで、SHAPベースの説明は、すべてのモデルタイプで利用可能になりました。ただし、XEMPベースの説明は、ユースケースのエクスペリメントでは利用できません。 インサイトのコントロールを使用して、データパーティションを設定し、スライスを適用して、予測範囲を設定します。
備考
個々の行ごとにSHAP値を計算するローカルな説明方法として、この機能をよりわかりやすく伝えるため、SHAPベースの予測説明から個々の予測説明に名称を変更しました。
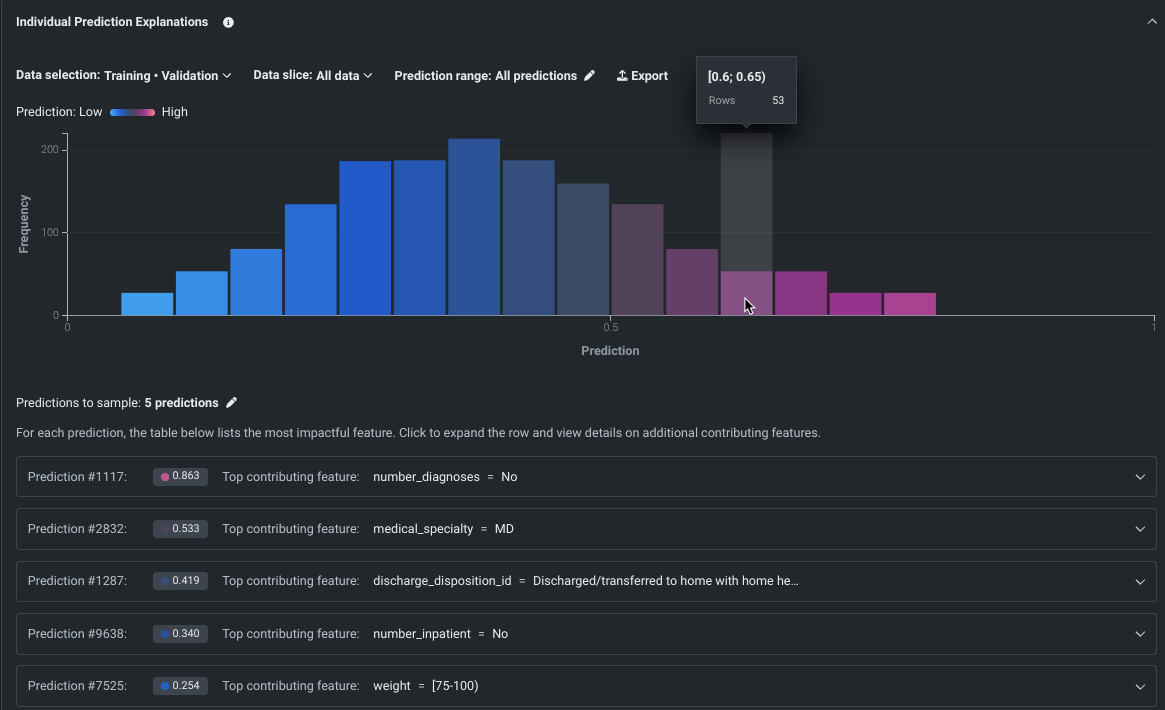
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ: NextGenでのユニバーサルSHAP
既存のエクスペリメントでカスタム特徴量セットを作成¶
ワークベンチでは、UIを使用して、既存の予測エクスペリメントに新しいカスタム特徴量セットを追加できるようになりました。 DataRobotでは、データの取込み時に、複数の特徴量セットが自動的に作成されます。これらは、モデルの構築と予測に使われる特徴量のサブセットを制御します。 リーダーボードからアクセスできるエクスペリメント情報ウィンドウの特徴量セットまたはデータタブから、独自の特徴量セットを作成できるようになりました。 一括選択を利用すると、ワンクリックで複数の特徴量を選択できます。
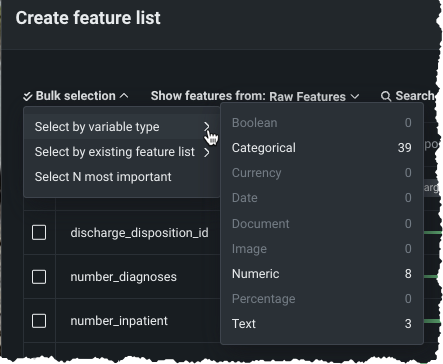
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ:ワークベンチでデータタブと特徴量セットタブを有効にする、ワークベンチのプレビューで特徴量セットを有効にする、ワークベンチで特徴量セットの作成を有効にする
増分学習で最大100GBのデータを使用可能¶
プレビュー版の機能です。二値および連続値タイプのプロジェクトで、増分学習(IL)を使って最大100GBのデータでモデルをトレーニングできるようになりました。 ILは大規模なデータセットに特化したモデルトレーニング方法であり、データをチャンク化してトレーニングのイテレーションを作成します。 設定オプションにより、上位モデルが1つのイテレーションでトレーニングを行うか、すべてのイテレーションでトレーニングを行うか、また精度の向上が頭打ちになった場合にトレーニングを停止するかどうかを制御できます。 モデルの構築が開始されたら、トレーニング済みのイテレーションを比較し、必要に応じて、別のアクティブバージョンを割り当てるか、トレーニングを継続することができます。 アクティブなイテレーションは、他のインサイトのベースとなり、予測に使用されます。

プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:増分学習を有効にする、データのチャンキングサービスを有効にする
実測値と予測値のアップロード制限を設定¶
プレビュー版の機能です。使用状況タブから、組織のデプロイに設定されている時間単位、日単位、週単位のアップロード上限値を監視できます。 処理された予測値と実測値の数を視覚化するチャートと、返された予測結果のテーブルサイズの上限値を示すタイルが表示されます。
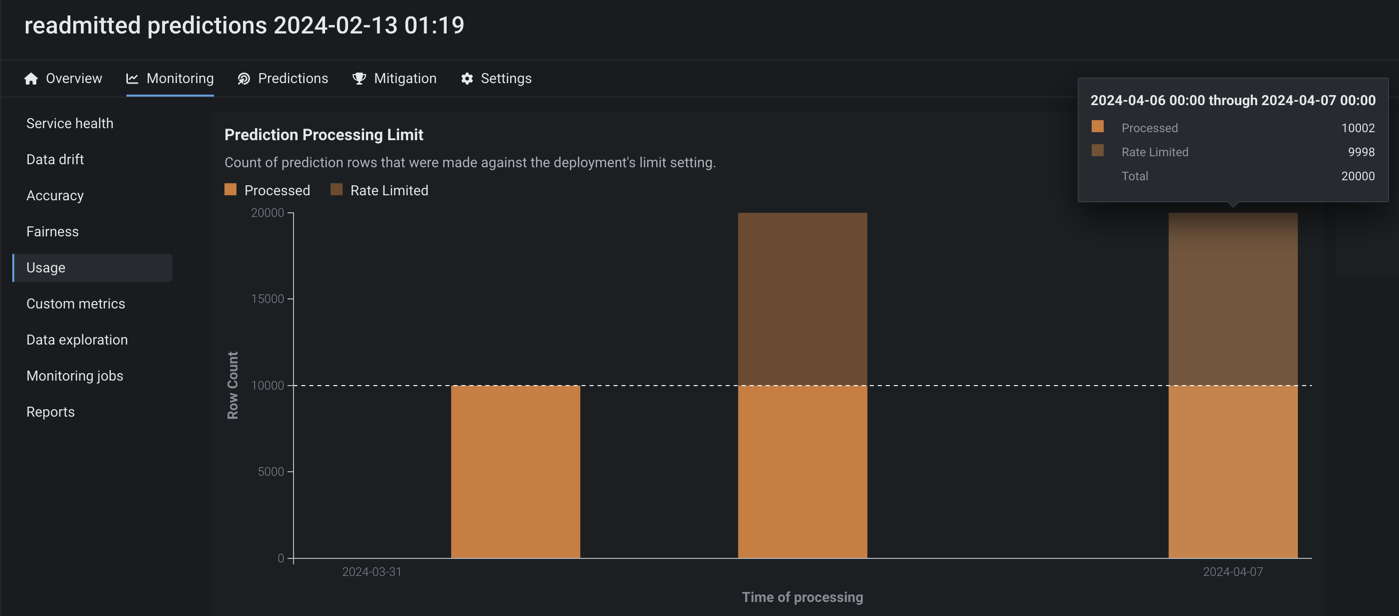
デフォルトではオフの機能フラグ:設定可能な予測値と実測値の制限を有効にする
プレビュー機能のドキュメントをご覧ください。
カスタムアプリケーションのランタイムパラメーターとリソースバンドルを設定¶
プレビュー版の機能です。NextGenのレジストリで、アプリケーションのソースにリソースとランタイムパラメーターを設定できます。 リソースバンドルは、本番環境での潜在的な環境エラーを最小限に抑えるために、アプリケーションが消費できるメモリーとCPUの最大量を決定します。 アプリケーションのソースから構築されたmetadata.yamlファイルに含めることで、カスタムアプリケーションで使用されるランタイムパラメーターを作成および定義できます。
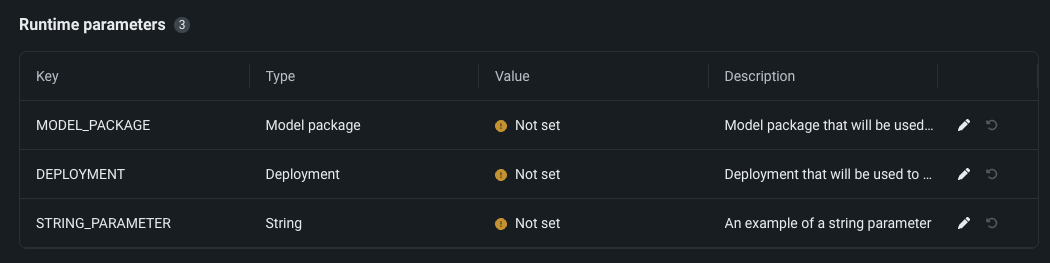
デフォルトではオフの機能フラグ: ランタイムパラメーターとリソースの上限を有効にする、リソースのバンドルを有効にする
プレビュー機能のドキュメントをご覧ください。
ワークベンチでの特徴量探索の実行¶
プレビュー版の機能です。ワークベンチで特徴量探索を実行し、複数のデータセットから新しい特徴量を発見および生成できるようになりました。 特徴量探索は、次の2つの場所で開始できます。
- データタブで、プライマリーデータセットとなるデータセットの右側にあるアクションメニュー > 特徴量探索をクリックします。
- 特定のデータセットのデータ探索ページで、データのアクション > 特徴量探索を開始をクリックします。
このページでは、セカンダリーデータセットを追加して、データセット間の関係性を設定できます。
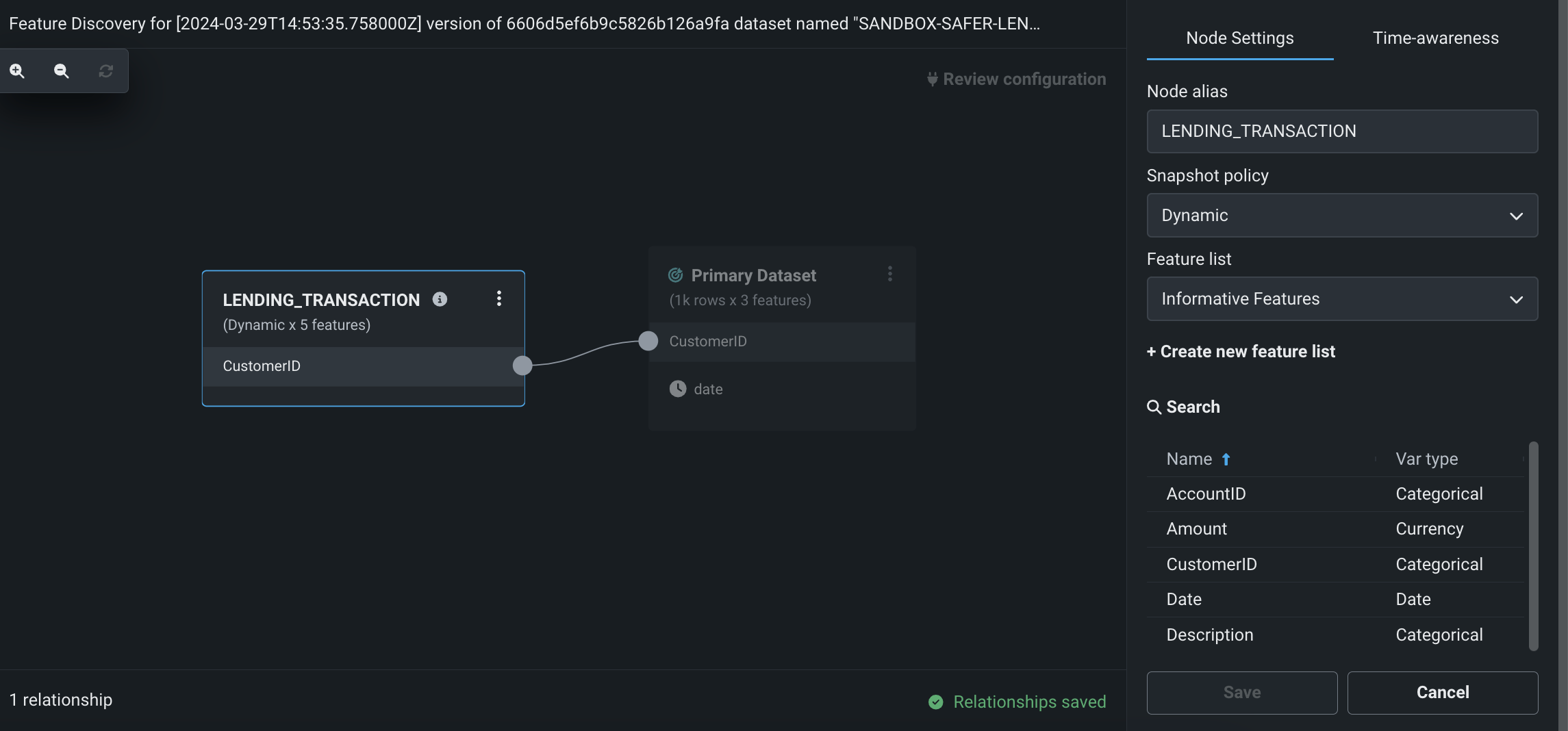
特徴量探索のレシピをパブリッシュすると、DataRobotは特定の結合と集計を実行し、新しい出力データセットを生成してデータレジストリに登録し、現在のユースケースに追加します。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオンの機能フラグ: ワークベンチで特徴量探索を有効にする
ワークベンチでのデータ操作を改善¶
このリリースでは、ワークベンチでのデータ操作に対して以下の機能強化が行われています(プレビュー版の機能です)。
- データ探索ページでは、データセットのバージョン管理、およびデータセットの名前変更とダウンロードができるようになりました。
- 特徴量セットのドロップダウンは、データ探索ページで独立したタブになりました。
- 新しい特徴量の計算で、オートコンプリート機能が改善されました。
- 動的データセットを使ってエクスペリメントを設定できるようになりました。
デフォルトではオフの機能フラグ:データ探索ビューの機能強化を有効にする
特徴量探索プロジェクトにおいて分散モードで予測を実行¶
プレビュー版の機能です。有効にすると、DataRobotは分散モードでバッチ予測を処理するため、スケーラビリティが向上します。 なお、データセットがAIカタログからのものである場合、DataRobotは自動的に分散モードで実行されます。
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:特徴量探索プロジェクトで予測を行う際に分散モードを有効にします、分散モードでの特徴量探索を有効にする
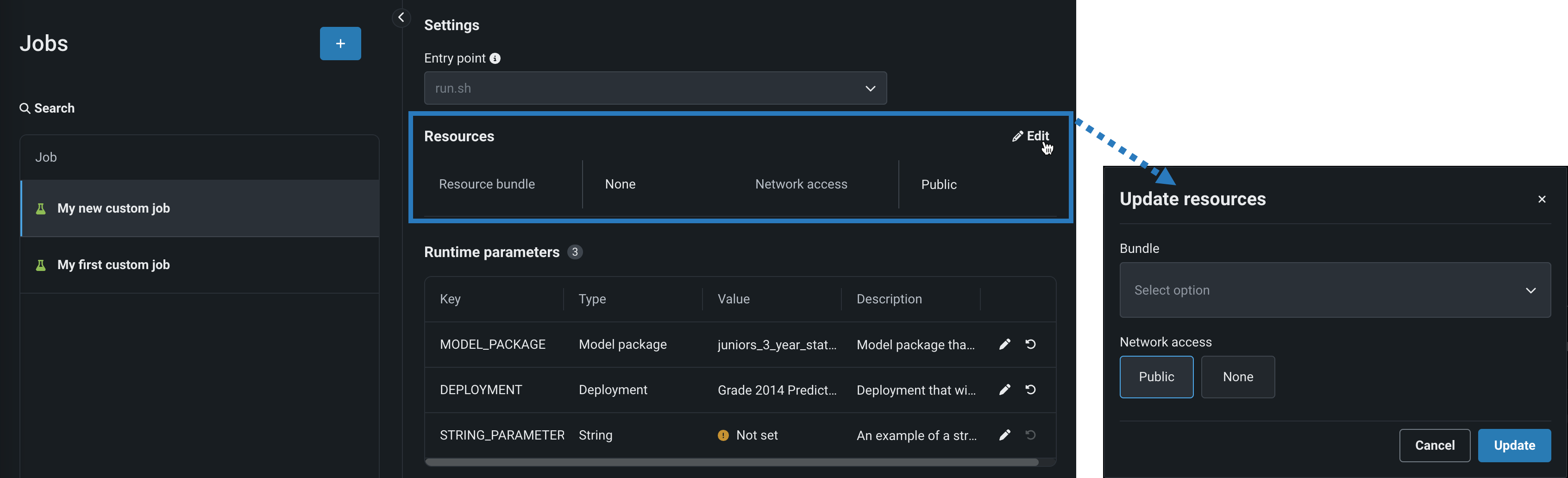
カスタムモデルのリソースバンドル¶
モデルを構築してリソース設定を行う際、メモリーではなくリソースバンドルを選択します。 リソースバンドルを使用すると、さまざまなCPUおよびGPUハードウェアプラットフォームから選択して、カスタムモデルを構築およびテストできます。 カスタムモデルの設定セクションで、リソース設定を開き、リソースバンドルを選択します。 この例では、モデルはNVIDIA A10デバイスでテストおよびデプロイされるように構築されています。
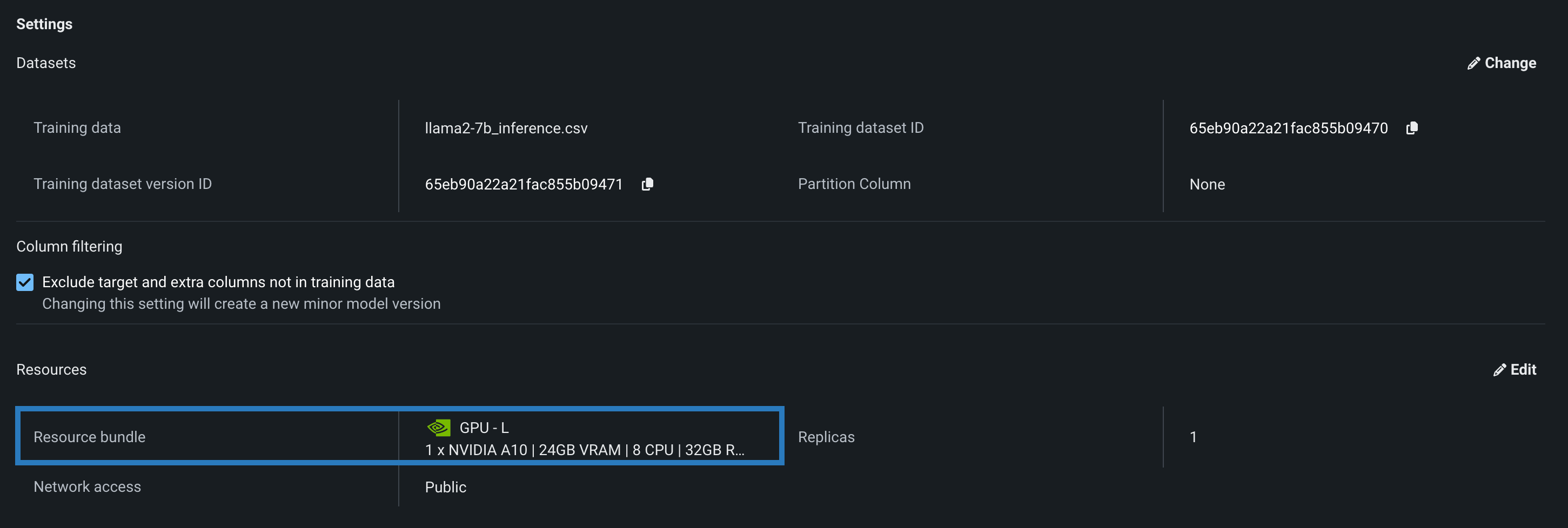
編集をクリックしてリソース設定の更新ダイアログボックスを開き、リソースのバンドルフィールドで、構築環境として使用可能な CPUおよび NVIDIA GPUデバイスを確認します。
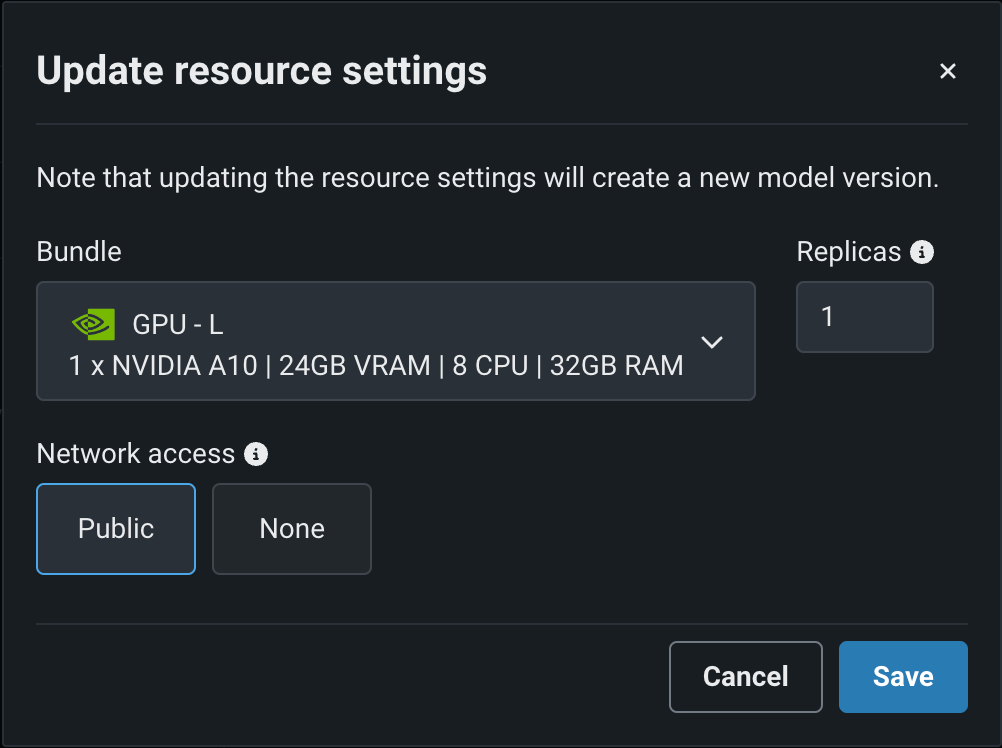
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ: リソースのバンドルを有効にする、カスタムモデルでGPUを使用した推論を有効にする
テキスト生成モデルの評価とモデレーション¶
評価とモデレーションのガードレールは、組織がプロンプトインジェクションや、悪意のある、有害な、または不適切なプロンプトや回答をブロックするのに役立ちます。 また、ハルシネーションや信頼性の低い回答を防ぎ、より一般的には、モデルをトピックに沿った状態に保つこともできます。 さらに、これらのガードレールは、個人を特定できる情報(PII)の共有を防ぐことができます。 多くの評価およびモデレーションガードレールは、デプロイされたテキスト生成モデル(LLM)をデプロイされたガードモデルに接続します。 これらのガードモデルはLLMのプロンプトと回答について予測し、これらの予測と統計を中心的なLLMデプロイに報告します。 評価とモデレーションのガードレールを使用するには、まず、LLMのプロンプトや回答について予測するガードモデルを作成してデプロイします。たとえば、ガードモデルは、プロンプトインジェクションや有害な回答を識別することができます。 次に、ターゲットタイプがテキスト生成のカスタムモデルを作成する場合、評価とモデレーションのガードレールを1つ以上定義します。
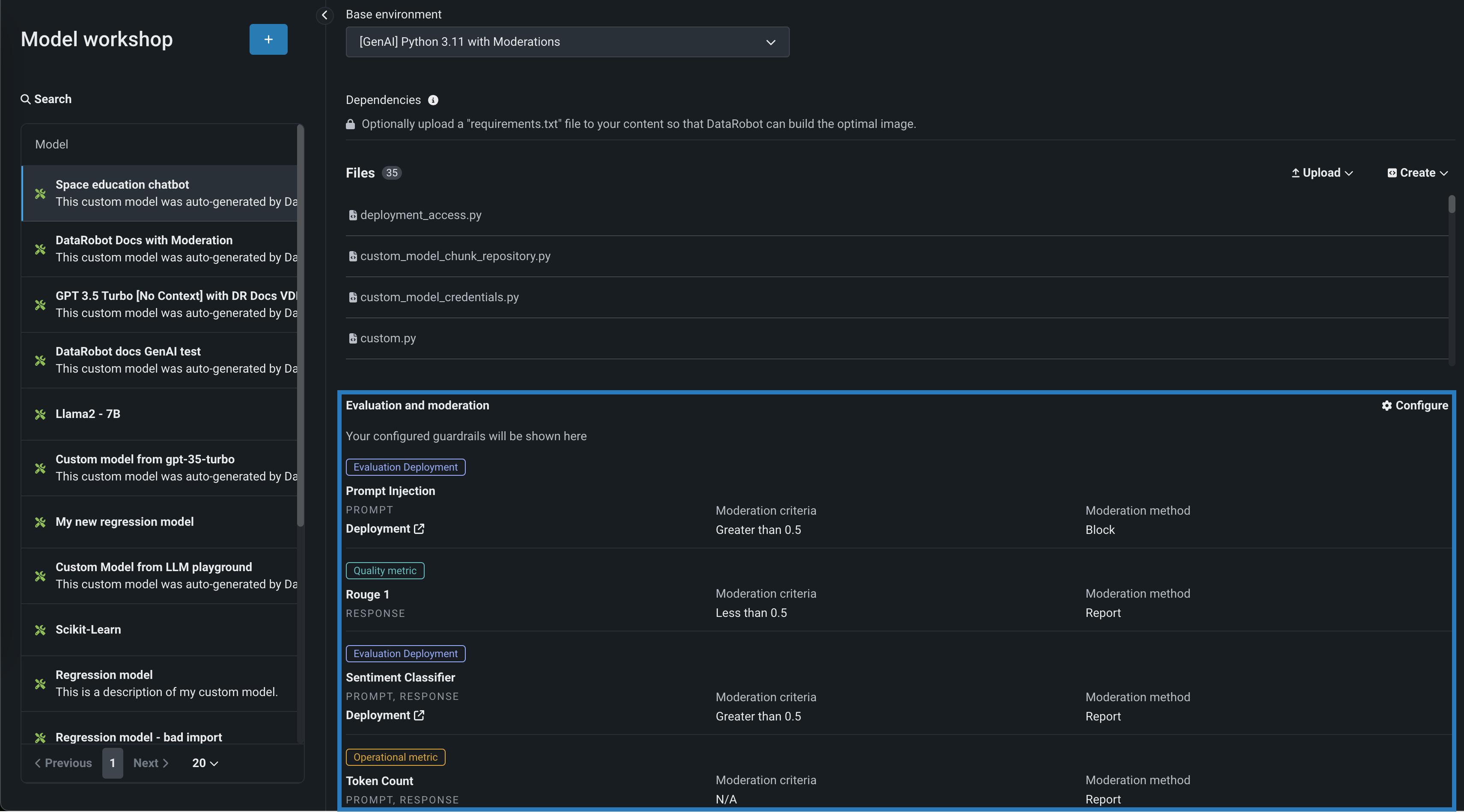
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ: モデレーションのガードレールを有効にする、モデルレジストリでグローバルモデルを有効にする(プレミアム)、予測応答で追加のカスタムモデル出力を有効にする
時系列カスタムモデル¶
時系列(二値)または時系列(連続値)をターゲットタイプとして選択し、二値分類および連続値モデルに必要なフィールドに加えて、時系列固有のフィールドを設定することによって、時系列カスタムモデルを作成します。
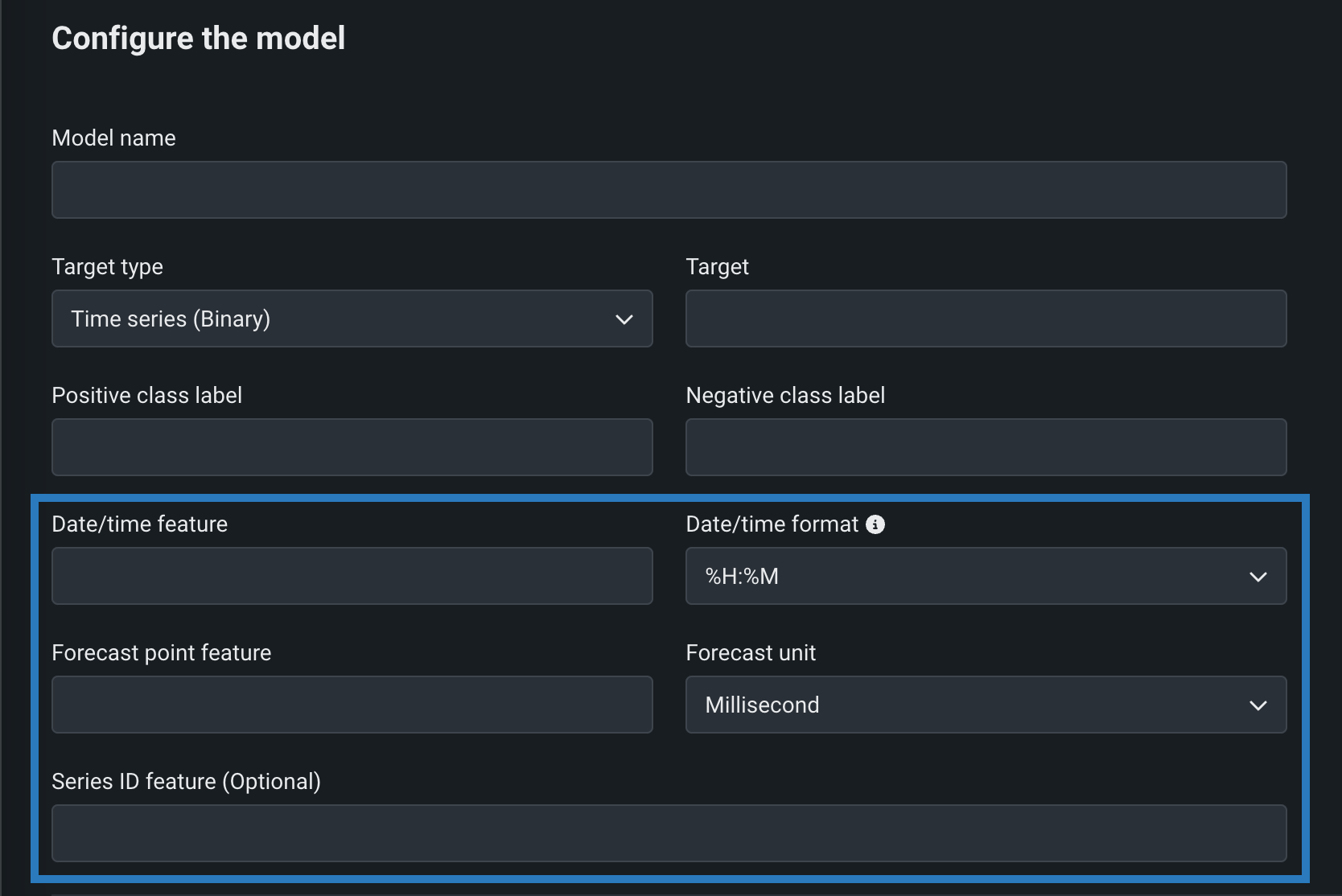
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ: 時系列のカスタムモデルを有効にする、カスタムモデルの予測で特徴量のフィルターを有効にする
デプロイのデータトレース¶
生成AIデプロイのデータ探索タブで、トレースをクリックして、関連付けIDで一致するプロンプト、回答、ユーザー評価、およびカスタム指標を探索します。 このビューでは、生成AIモデルの回答の品質に関するインサイトが、ユーザーによる評価と、実装した生成AIのカスタム指標に基づいて提供されます。
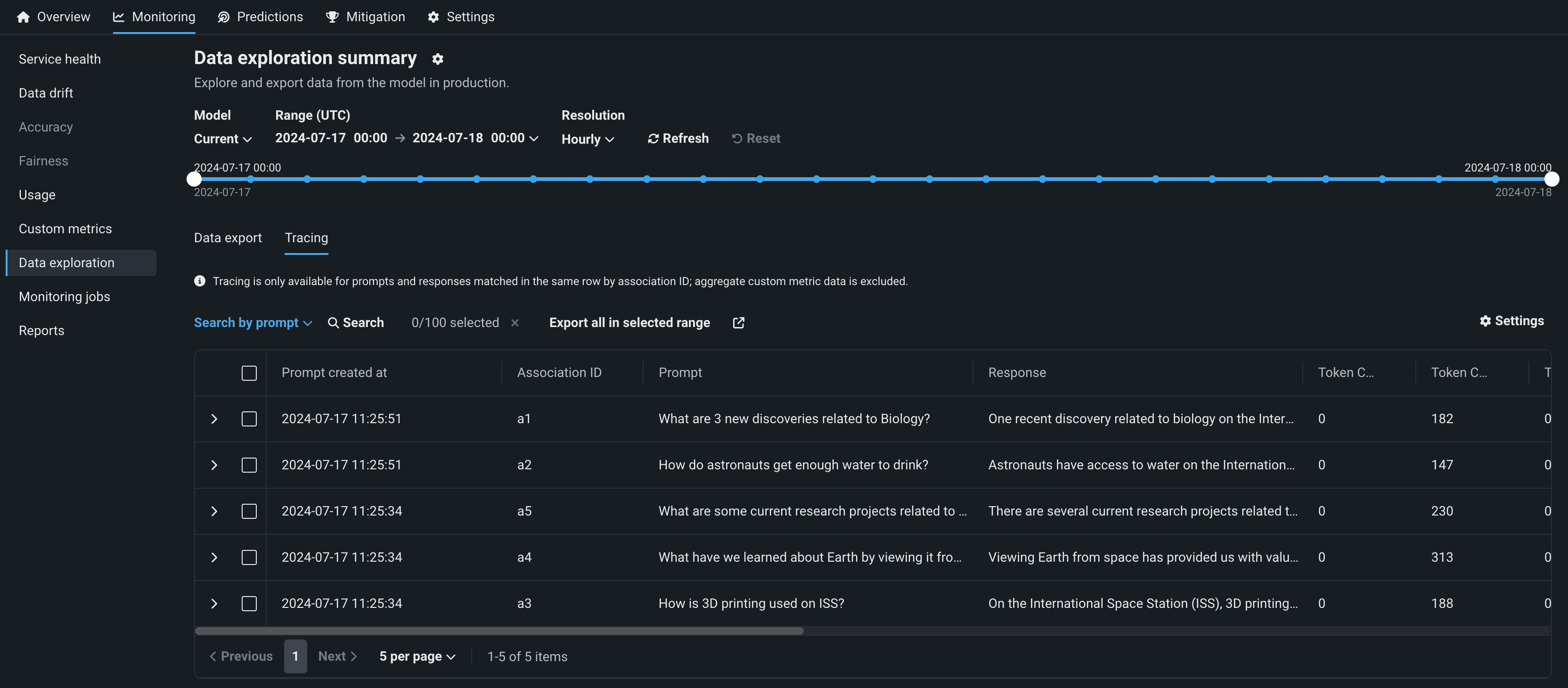

プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ: テキスト生成のターゲットタイプでデータ品質テーブルを有効にする(プレミアム機能)、生成モデルで実測値の保存を有効にする(プレミアム機能)
コードベースの再トレーニングジョブ¶
NextGenのレジストリ > ジョブページでカスタムジョブを作成する場合、コードベースの再トレーニングジョブを作成できるようになりました。 + 新規追加(またはカスタムジョブパネルが開いている場合は ボタン)をクリックして、再トレーニングのためにカスタムジョブを追加をクリックします。 再トレーニング用のカスタムジョブを作成したら、それを再トレーニングポリシーとしてデプロイに追加できます。
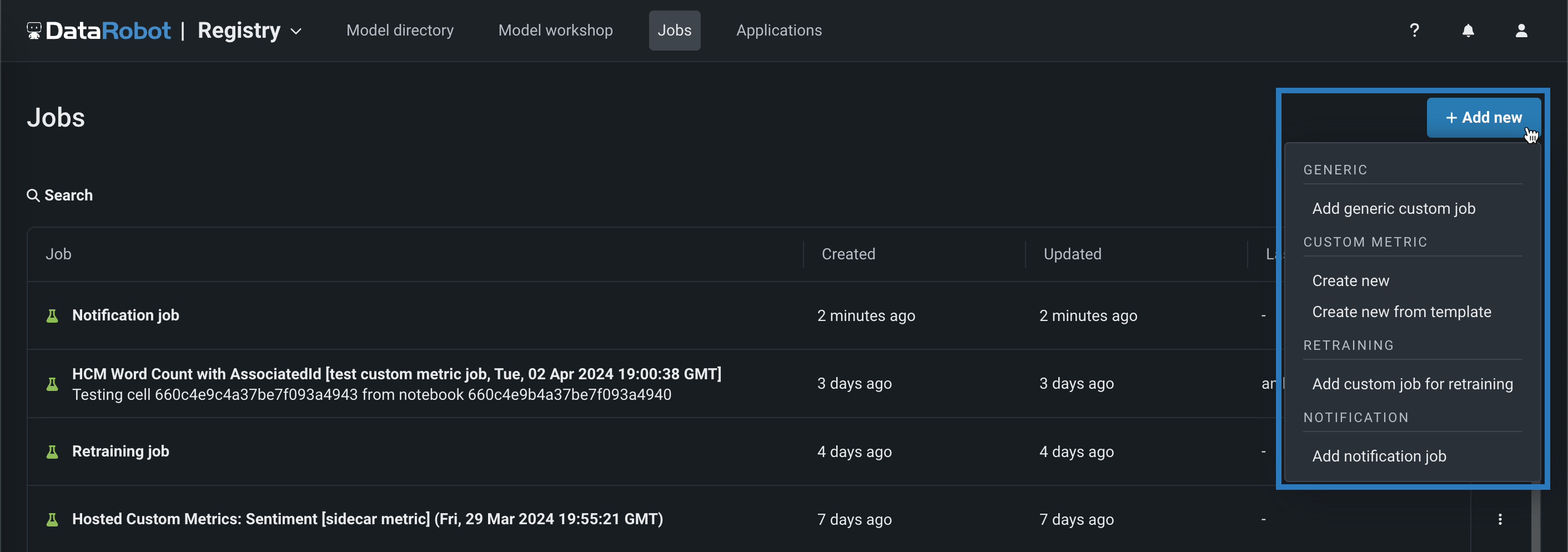
プレビュー機能のドキュメントをご覧ください。
再トレーニングジョブを対象とした、デフォルトではオフの機能フラグ:カスタムジョブベースの再トレーニングポリシーを有効にする、Notebooksでカスタム環境を有効にする
バッチ予測のラングラーレシピ¶
デプロイの予測 > 予測を作成タブを使用して、バッチ予測を行うことで、デプロイされたモデルでラングラーデータセットを効率的にスコアリングできます。 バッチ予測とは、大規模なデータセットで予測を行う方法で、入力データを渡すと各行の予測結果が得られます。 予測データセットボックスで、ファイルを選択 > ラングラーをクリックし、ラングラーデータセットで予測を行います。
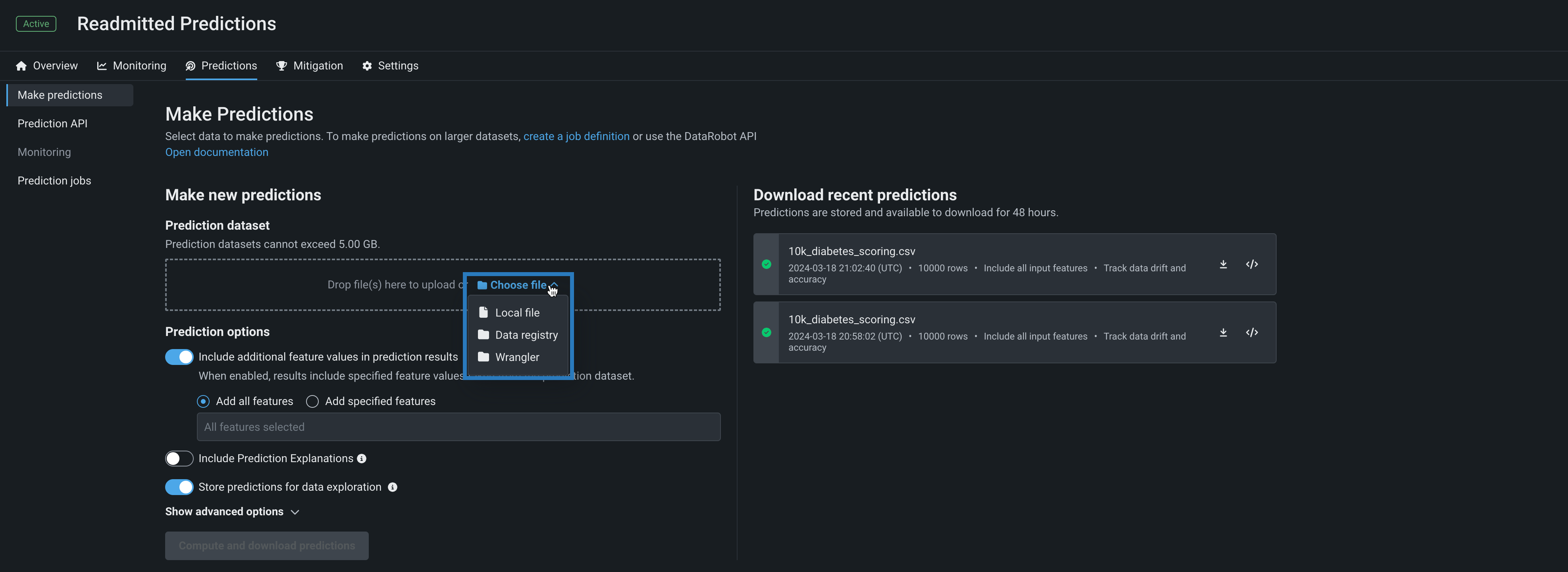
ワークベンチでの予測
ラングラーは、ワークベンチでは予測データセットソースとしても使用できます。 デプロイ前のモデルで予測を行うには、エクスペリメントのモデルリストからモデルを選択し、モデルアクション > 予測を作成をクリックします。
予測データの送信元と送信先を指定し、予測が実行されるタイミングを決定することで、バッチ予測ジョブをスケジュールすることもできます。
詳しくはドキュメントをご覧ください。
プロジェクトとノートブックをDataRobot ClassicからNextGenに移行¶
プレビュー版の機能です。DataRobot Classicで作成したプロジェクトやノートブックをDataRobot NextGenに移行することができます。 DataRobot Classicでプロジェクトをエクスポートし、エクスペリメントとしてワークベンチのユースケースに追加できます。 ノートブックも、Classicからエクスポートして、ワークベンチのユースケースに追加できます。
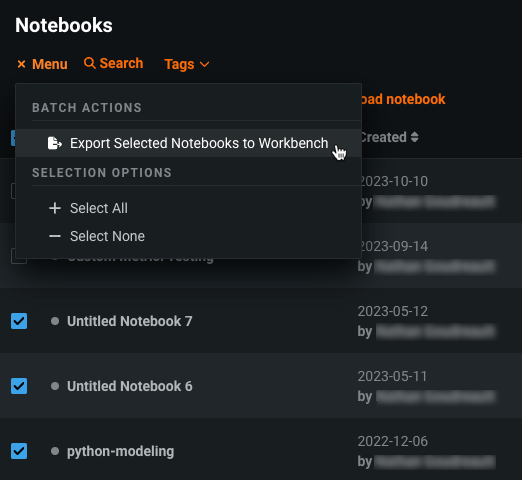
プレビュー機能のドキュメントをご覧ください。
デフォルトではオフの機能フラグ:アセットの移行を有効にする
API¶
Pythonクライアントv3.4¶
DataRobotのPythonクライアントのv3.4が一般提供されました。 v3.4で導入された変更の完全なリストについては、 Pythonクライアントの変更履歴を参照してください。
DataRobot REST API v2.33¶
DataRobotのREST API v2.33が一般提供されました。 v2.33で導入された変更の完全なリストについては、 REST APIの変更履歴を参照してください。
サポート終了/移行ガイド¶
Tableau拡張機能の削除¶
DataRobotは以前、2つのTableau拡張機能、InsightsとWhat-Ifを提供していましたが、現在は使用非推奨となり、アプリケーションから削除されました。 これらの拡張機能は、Tableauストアからも削除されました。
カスタムモデルのトレーニングデータ割り当てを変更¶
2024年4月から、カスタムモデルレベルでトレーニングデータを割り当てる使用非推奨の方法に代わって、(2023年3月リリースで発表されたとおり)カスタムモデルのバージョンにトレーニングデータが割り当てられるようになりました。 つまり、「カスタムモデルバージョンごと」の方法がデフォルトになり、「カスタムモデルごと」の方法は削除されました。
「カスタムモデルごと」の方法を使用した残りのカスタムモデルの自動変換は、使用非推奨期間が終了すると自動的に行われ、カスタムモデルのバージョンレベルでトレーニングデータが割り当てられました。 ほとんどの場合、何もする必要はありません。ただし、「カスタムモデルごと」の割り当て方法を使用していても変換されていないカスタムモデルに依存する自動化が残っている場合は、機能のギャップを避けるために、「カスタムモデルバージョンごと」の割り当て方法をサポートするように更新する必要があります。
割り当て方法の変更の概要については、カスタムモデルのトレーニングデータ割り当てを変更のドキュメントを参照してください。
記載されている製品名および会社名は、各社の商標または登録商標です。 製品名または会社名の使用は、それらとの提携やそれらによる推奨を意味するものではありません。