Sliced insights¶
Sliced insights provide the option to view a subpopulation of a model's data based on feature values—either raw or derived. Slices are, in effect, a filter for categorical, numeric, or both types of features. Slices are applied to the Training, Validation, Cross-validation, or Holdout (if unlocked) partitions, depending on the insight.
Viewing and comparing insights based on segments of a project’s data helps to understand how models perform on different subpopulations. Use the segment-based accuracy information gleaned from sliced insights, or compare the segments to the "global" slice (all data), to improve training data, create individual models per segment, or augment predictions post-deployment.
Some common uses of sliced insights:
A bank is building a model to predict loan default risk and wants to understand if there are segments of their data— demographic information, location, etc.—that their model performs either more or less accurately on. If they find that "slicing" the data shows some segments perform to their expectations, they may choose to create individual projects per segment.
An advertising company wants to predict whether someone will click an ad. Their data contains multiple websites and they want to understand if the drivers are different between websites in their portfolio. They are interested in creating comparison groups, with each group consisting of some number of different values, to ultimately impact user behaviors in different ways for each site.
To view insights for a segment of your data once models are trained, choose the preconfigured slice from the Slice dropdown. If the slice has been calculated for the chosen insight, DataRobot will load the insight. Otherwise, a button will be available to start further calculations.
Supported insights¶
Sliced insights are available for the following insights (where applicable) for binary classification and regression projects:
In DataRobot Classic:
- Feature Effects
- Feature Impact
- Lift Chart
- Residuals (not available for time-aware)
- ROC Curve
In NextGen:
See also the sliced insight considerations.
Create a slice¶
You can create a slice to apply to insights from a supported Leaderboard insight. Each slice is made up of up to three filters (connected, as needed, by the AND operator).
Note
Features that can be used to create filters are based on all features, regardless of what is currently displayed on the Data tab or if you built a model using a list that doesn't include that feature. This is because while feature lists are based on columns, slices are based on rows. That is, the value of the selected feature appears in the row that is identified by the individual feature in the list feature.
To create a slice from the Leaderboard:
-
Select a model and open a supported insight. The insight loads using all data for the selected partition.
-
From the Slice dropdown, which defaults to
All Data, configure a new slice by selecting Manage slices.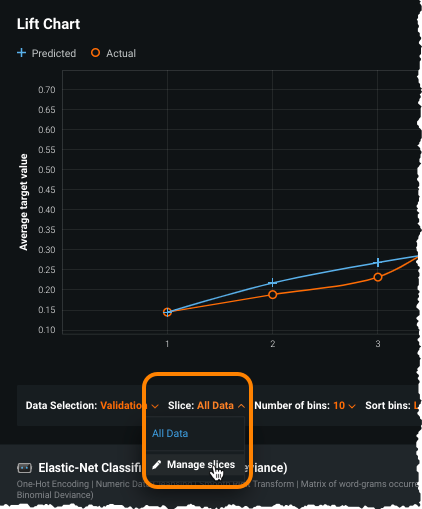
-
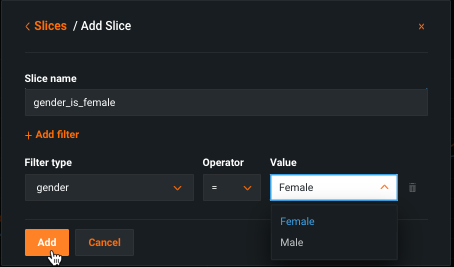
Click Add slice to open the filter configuration window. Fields are described in the filter reference.
-
Click Add to finish and view the Slices window. The Slices window lists all configured slices as well as summary text of the filters that define the slice.
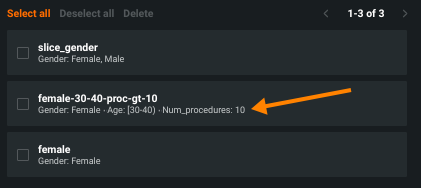
From here you can add a new slice or delete one or more configured slices. Click Done to close the configuration window.
Filter configuration reference¶
The following table describes the fields in the filter configuration:
| Filter field | Description |
|---|---|
| Slice name | Enter a name for the filter. This is the name that will appear in the Slices dropdown of supported insights. |
| Filter type | Select the categorical or numeric feature to base the filter on. They are grouped in the dropdown by variable type. You cannot set the target as the filter type. |
| Operator | Set the filter operator to define what comprises the subpopulation. That is, those rows in which the feature value: in: Falls within the range of the defined Value (categorical and boolean). =*: Is equivalent to the defined Value (see below). >: Is greater than the defined Value (numeric only).<: Is less than the defined Value (numeric only). between: Falls between the two values specified, inclusive (numeric only). not between: Is not within the two values specified, inclusive (numeric only). |
| Values | Set the matching criteria for Filter type. For categorical features, all available values will be listed in the dropdown. For numerics, enter a value manually. |
* If you select = as the operator, the Value must match exactly and you can choose only one value. If you set in, you can select multiple values.
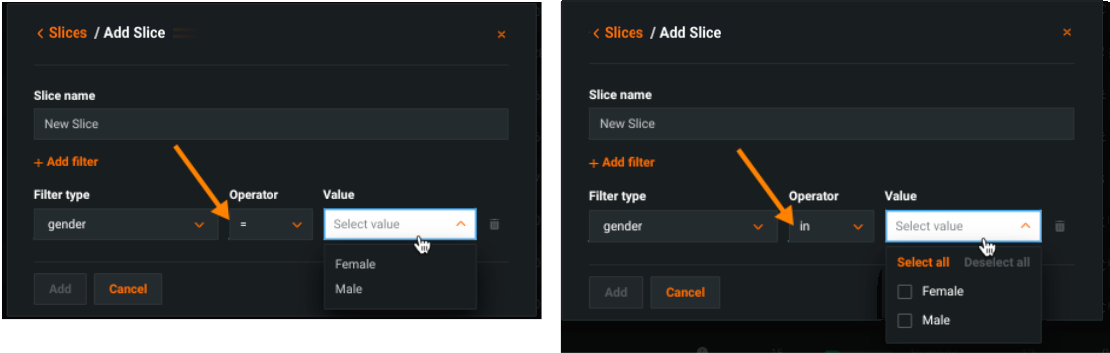
Adding multiple conditions¶
Use Add filter to build a slice with multiple conditions. Note that:
- You can mix categorical and numeric features in a single slice.
-
All conditions are processed with the
ANDoperator.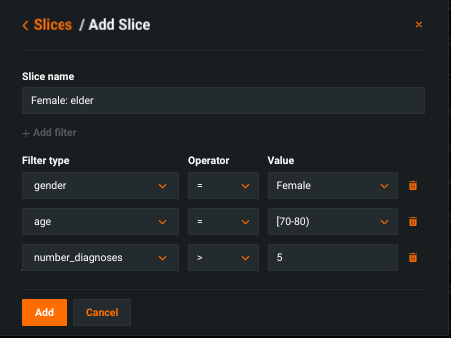
Generate sliced insights¶
When you first load an insight, DataRobot displays results for all data in the appropriate partition (unless further calculations are required). This is the equivalent of the global slice, or as referenced in the dropdown, All Data. For the Lift Chart, ROC Curve, and Residuals, once prediction calculations are run for the first slice, DataRobot stores them for re-use (assuming the same data partition). Feature Impact and Feature Effects, because they use a special calculation process, do not benefit from caching and so recompute predictions for each slice.
When viewing sliced data for a given model, you only have to generate predictions once for a selected partition—Validation, Cross-validation, or if calculated, Holdout. Note that this calculation is in addition to the original calculation DataRobot ran when fitting models for the project.
Note
Feature Impact provides a quick-compute option to control the sample size used in the calculation.
Recompute sliced insights¶
When using slices with either Feature Effects or Feature Impact, you must manually launch the calculation to compute a sliced version of the insight. The reason for this is to save compute resources—it allows you to determine whether a sliced insight has been created without automatically launching the associated jobs. The order of operations is:
-
When requested, DataRobot calculates Feature Impact on all data. Then, you can initiate the calculation for any configured slice.
-
If you request Feature Effects before Feature Impact, DataRobot calculates Feature Impact on all data and then returns Feature Effects results. You are not provided with the option to select a slice until after the initial Feature Impact job is complete.
-
If off, the row count uses 100,000 rows or the number of rows available after a slice is applied, whichever is smaller.
For unsliced Feature Impact, the quick-compute toggle replaces the Adjust sample size option. In that case, possible outcomes are:
-
If on, DataRobot uses 2500 rows or the number of rows in the model training sample size, whichever is smaller.
-
If off, the row count uses 100,000 rows or the number of rows in the model training sample size.
You may want to use this option, for example, to train Feature Impact at a sample size higher than the default 2500 rows (or less, if downsampled) in order to get more accurate and stable results.
View a sliced insight¶
To view a sliced insight, choose the appropriate slice from the Slice dropdown. If you see a slice but are unsure of the filter conditions, click Manage Slices to view summary text of the filters that define the slice.
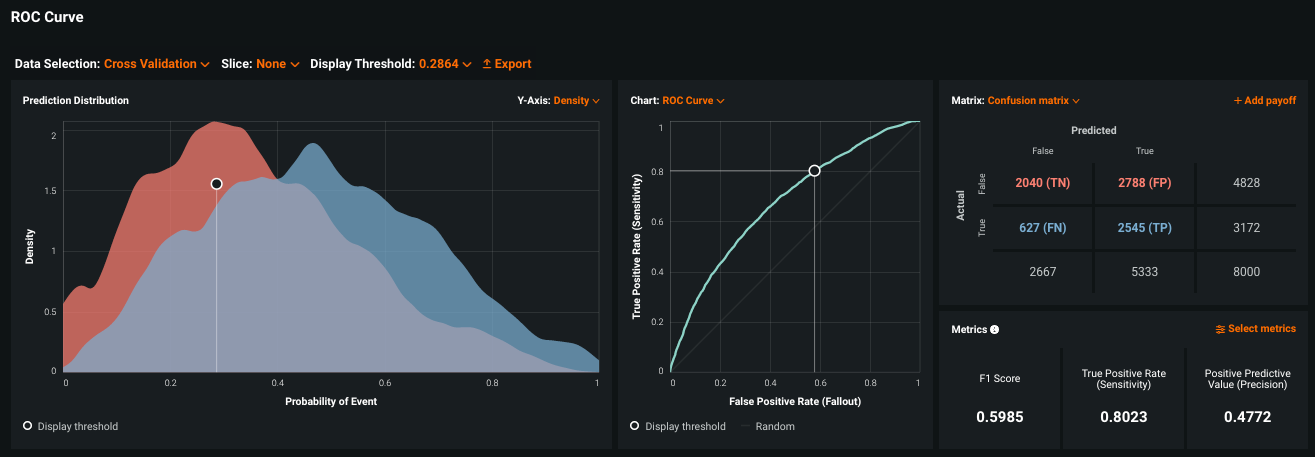
The following example shows the ROC Curve tab without slices applied:
Consider the same model with a slice applied that segments the data for females aged 70-80 who have had more than five diagnoses:
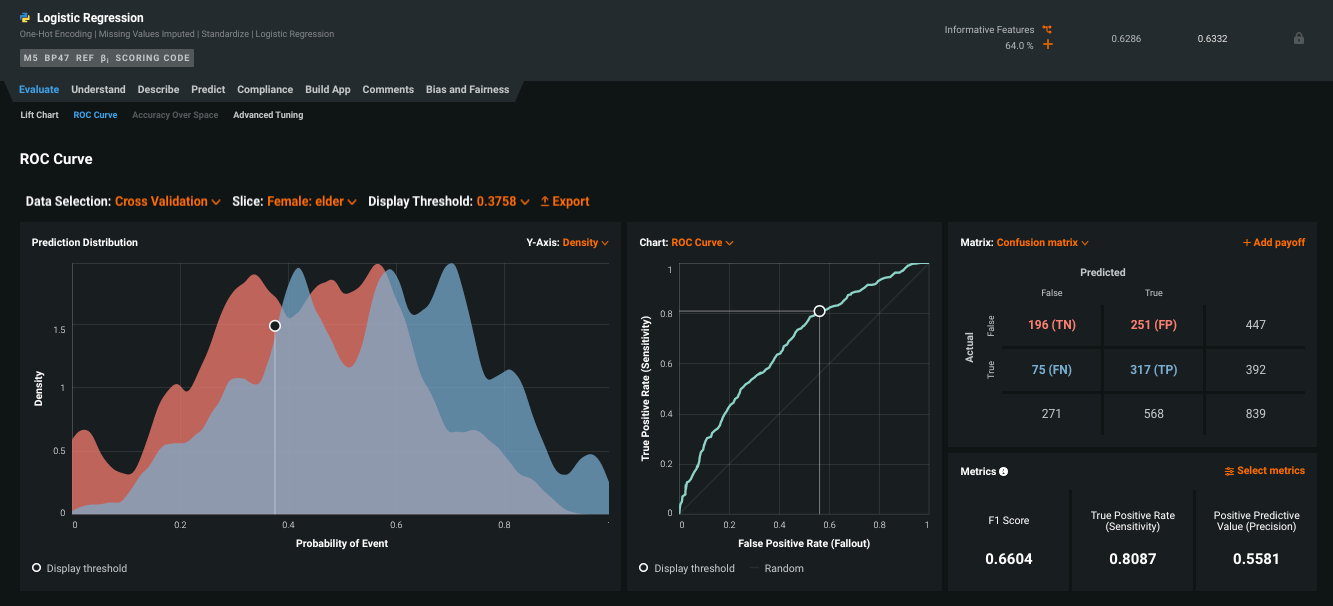
Note
If the slice results in predictions that are either all positive or all negative, the ROC curve will be a straight line. The Confusion Matrix reports the same results in table form.
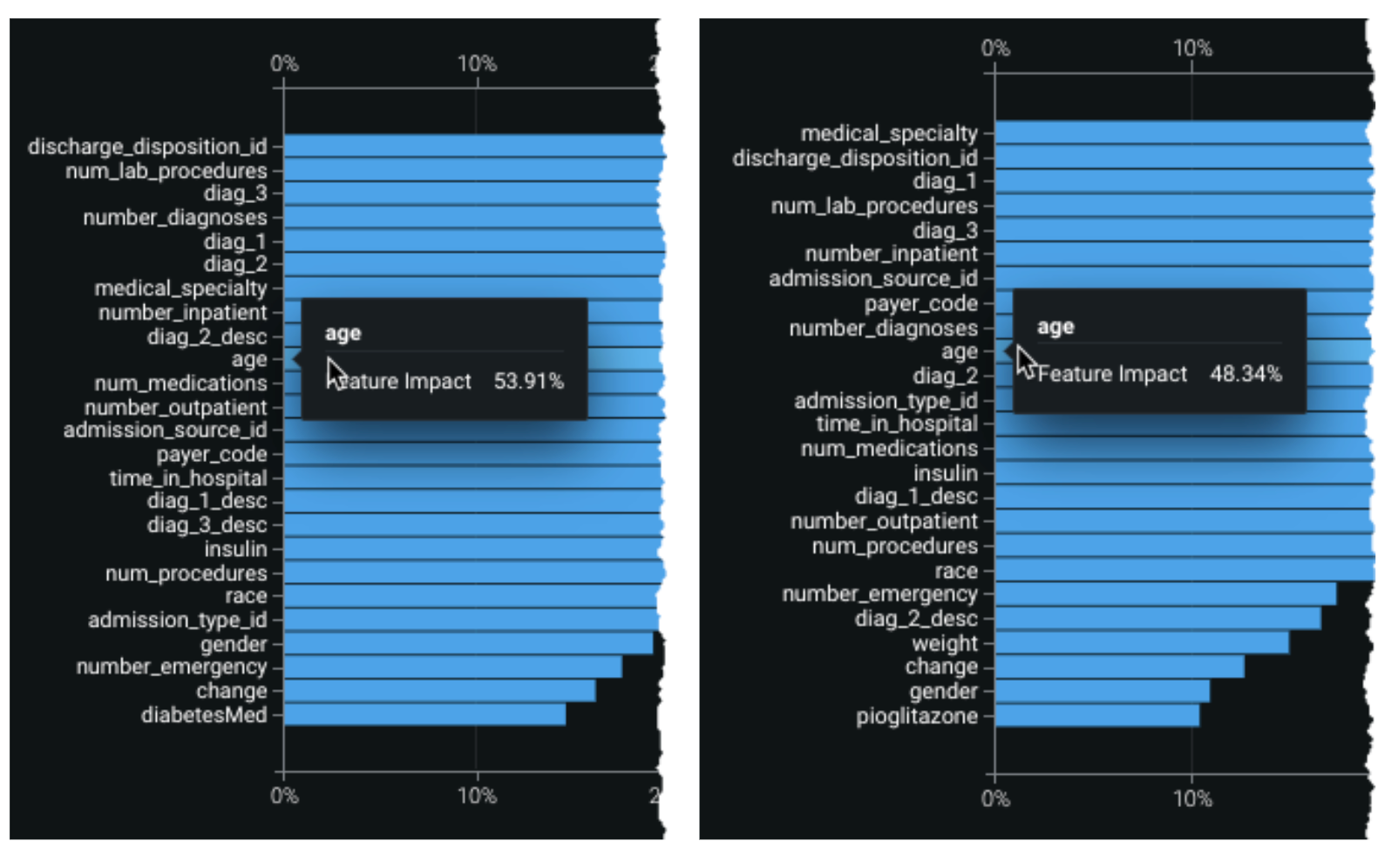
The images below show Feature Impact with first the global slice:
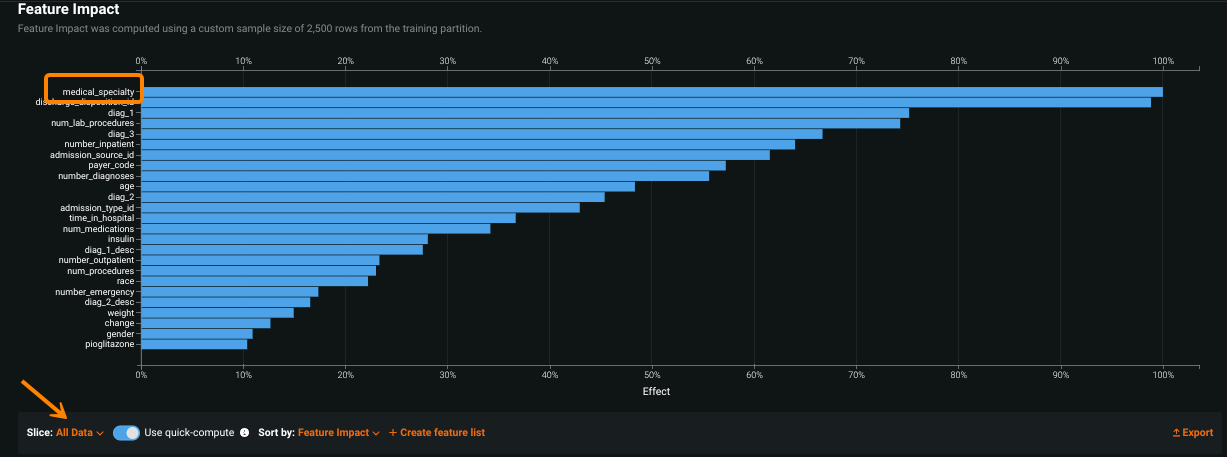
And then a configured slice:
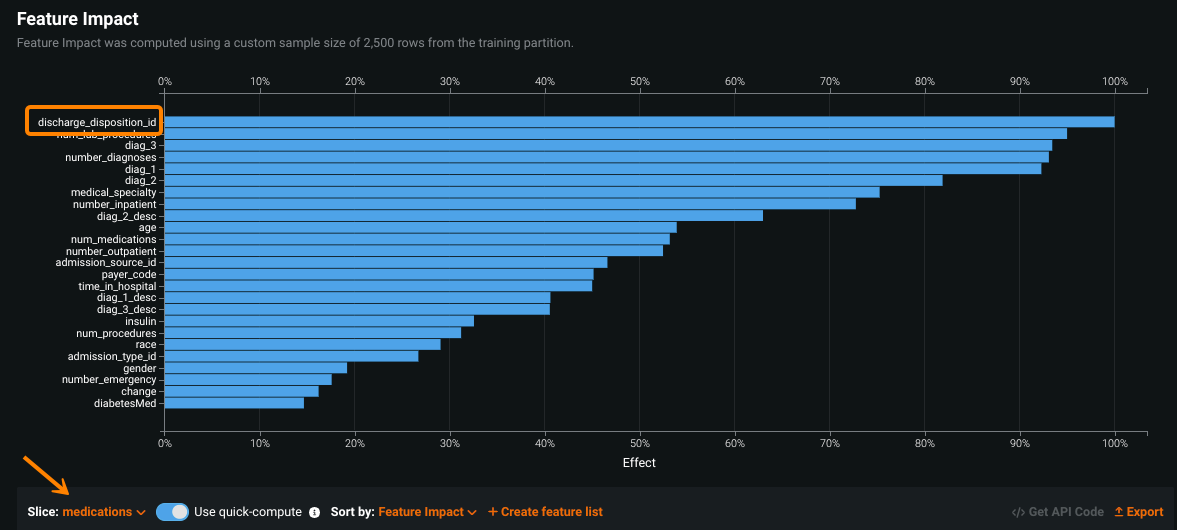
Hover on a feature to compare the calculated impact between sliced views:
Deep dive: Slice calculations¶
For the Lift Chart, ROC Curve, and Residuals, once prediction calculations are run for the first slice, DataRobot stores them so that they can be re-used, assuming the same data partition. Specifically:
-
When you select a new slice for the first time, within the same insight, DataRobot will generate the insight but will not need to rerun predictions (because predictions for the partition have already been computed).
-
When you change to another supported insight (other than Feature Impact), the predictions are available and only the insight itself must be generated (because the partition's predictions were already computed by another supported insight).
For Feature Impact and Feature Effects, DataRobot first runs predictions on the training sample chosen to fit the model. Then, DataRobot creates sliced-based synthetic prediction datasets and generates predictions for use in the respective insights. Each insight generates its own unique synthetic datasets.
Feature considerations¶
-
Sliced insights are available for binary classification and regression projects for predictive and time-aware experiments.
-
Slices are not available for projects that use Feature Discovery.
-
Slices are not available in projects created with SHAP Feature Importance and SHAP-based Prediction Explanations.
-
You cannot edit slices. Instead, delete (if desired) the existing slice and create a new slice with the desired criteria.
-
You can add a maximum of three filter conditions to a single slice.
-
If you create an invalid slice, the slice is created, but when you apply it on supported insights, it will error. This could happen, for example, if there are not enough rows on the sliced data to compute the insight or the filter is invalid. For example, if set
num_procedures > 10and the maximum number for any row is6, DataRobot creates the slice but errors during the insight calculation if the slice is selected. -
Row requirements:
- Feature Impact with Quick-compute: A minimum of 2500 rows or the number of rows available after a slice is applied, whichever is smaller. Minimum 10 rows, maximum 100,000 rows.
- Other insights: Minimum 1 row (must fall within the slice), maximum set only by file size limits.
-
For Feature Impact:
-
The number of rows used in a sliced calculation of Feature Impact is equal to the number of training rows that fit the slice filter criteria. Previously, Feature Impact was calculated on the exact number of rows requested in row count.
-
DataRobot recommends you calculate Feature Impact for all data before calculating an individual slice.
-