エクスペリメントを作成¶
ワークベンチで実行可能なAIエクスペリメントの「タイプ」は2つあります。
- 予測モデリング。このページで説明しています。データに基づいて行単位の予測を行います。
- 時間認識モデリング。 こちらで説明しています。 時間に関連するデータを使用してモデルを作成し、行単位の予測、時系列予測、または現在値の予測である 「ナウキャスト」を行います。
エクスペリメントは、 ユースケース内の個々の"プロジェクト"です。 データ、ターゲット、モデリング設定を変更しながら、ビジネス問題を解決するための最適なモデルを見つけることができます。 Within each experiment, you have access to its Leaderboard and model insights, as well as experiment summary information.
その他の重要情報については、関連する FAQを参照してください。
基本を作成¶
ユースケース内から新しいエクスペリメントを作成するには、次の手順に従います。
備考
モデリングを開始ボタンをクリックして、データセットから直接モデリングを開始することもできます。 新しいエクスペリメントの設定ページが開きます。 ここから、以下の手順に従ってください。
特徴量セットを作成¶
プレビュー
ワークベンチでの特徴量セットのサポートは、デフォルトではオンになっています。
機能フラグ:ワークベンチのプレビューで特徴量セットを有効にする
モデリングの前に、データタブからカスタム特徴量セットを作成できます。 モデリングの設定中にそのセットを選択すると、DataRobotはそのセットの特徴量のみを使用して、モデリングデータを作成します。
新しいセットを作成するには:
- ユースケースから、モデリングするデータセットを選択し、データプレビューを開きます。
-
ページの上部にあるドロップダウンをクリックし、+ 新しい特徴量セットを選択して特徴量ビューを開きます。
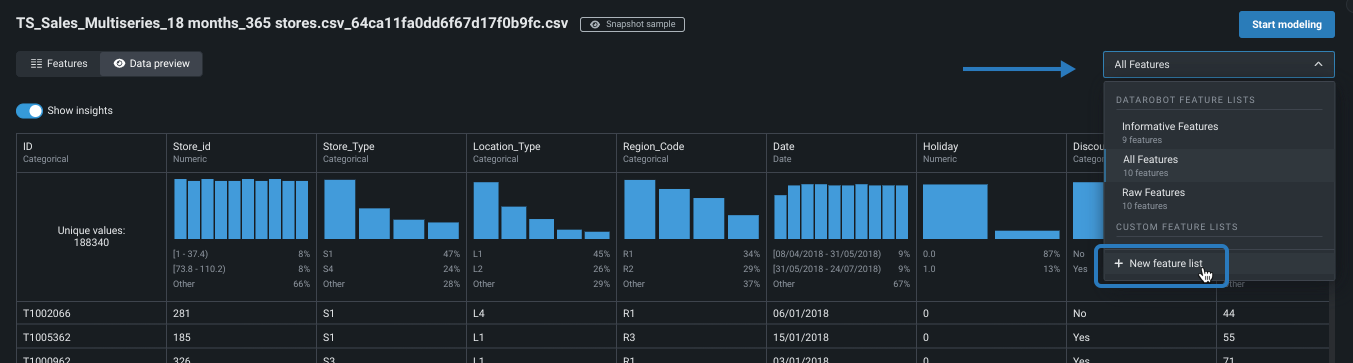
-
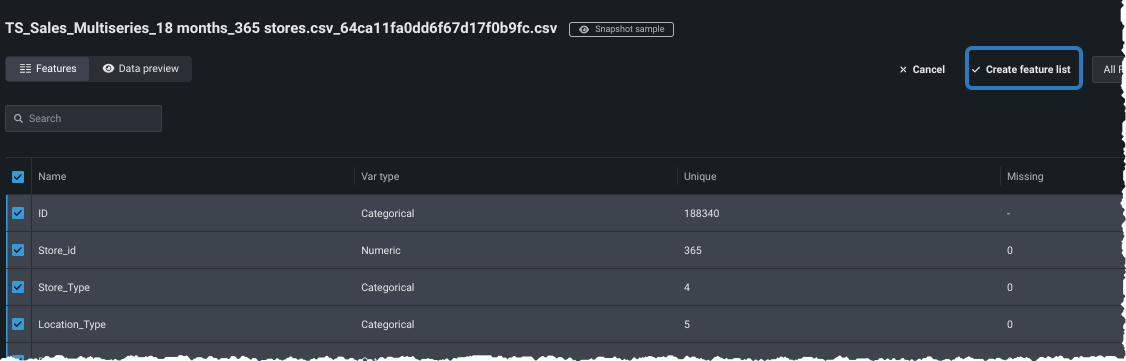
各特徴量の横にあるカスタムセットに含めたいチェックボックスを選択します。 次に、特徴量セットを作成をクリックし、名前と説明(オプション)を入力し、変更を保存をクリックします。
エクスペリメントを追加¶
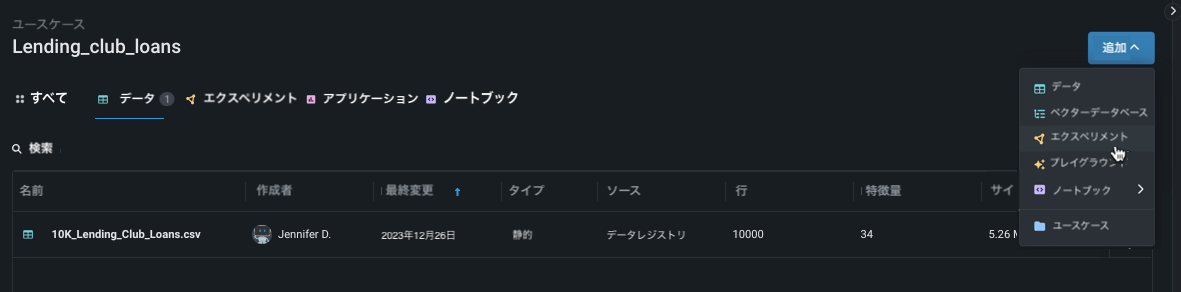
ユースケース内から追加をクリックし、エクスペリメントを選択します。 新しいエクスペリメントの設定ページが開き、ユースケースにロード済みのすべてのデータが一覧表示されます。
データを追加¶
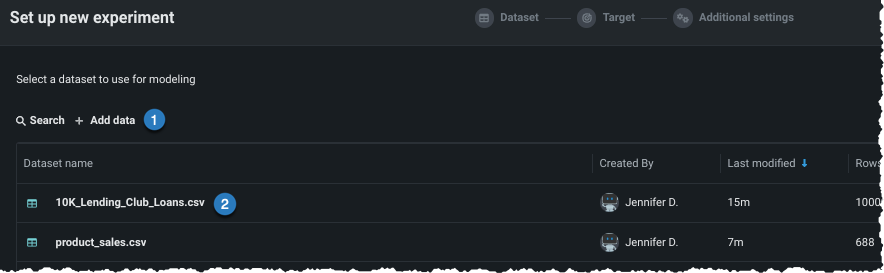
新しいデータを追加 する(1)か、ユースケースに既にロードされているデータセットを選択する(2)ことにより、エクスペリメントにデータを追加します。
データがユースケースにロードされたら(上記のオプション2と同様)、エクスペリメントで使用するデータセットをクリックして選択します。 ワークベンチは、データのプレビューを開きます。
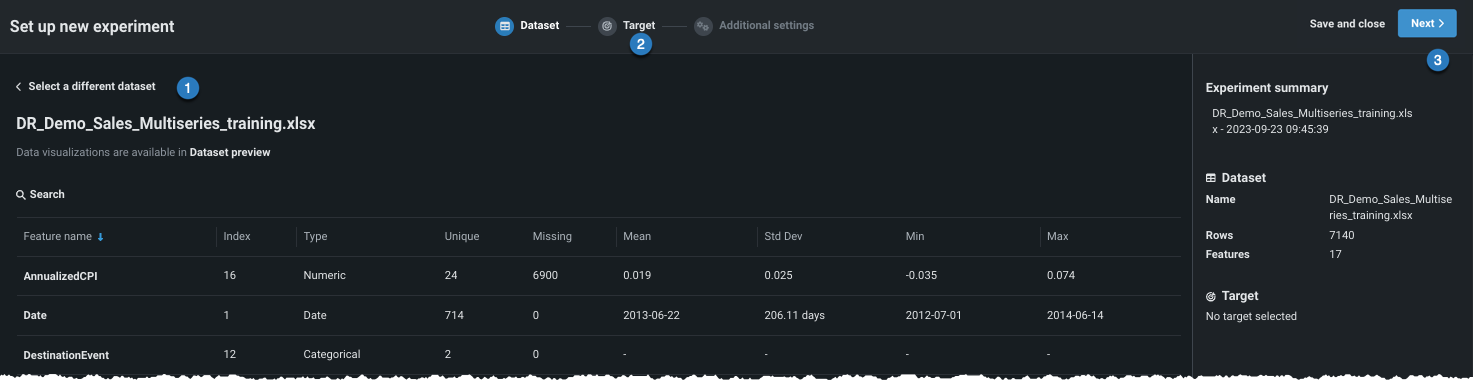
ここから、次のことができます。
| オプション | |
|---|---|
| 1 | クリックして、データリストに戻り、別のデータセットを選択します。 |
| 2 | アイコンをクリックして続行し、ターゲットを設定します。 |
| 3 | 次へをクリックして続行し、ターゲットを設定します。 |
ターゲットの設定¶
ターゲットの選択に進むと、ワークベンチでは、モデリング用のデータセットが準備されます(EDA 1)。
備考
これ以降のエクスペリメントの作成では、エクスペリメントの設定を続行するか、または保存して閉じるをクリックして、作成中のユースケースをドラフトとして保存できます。

ワークベンチで作成したドラフトをDataRobot Classicで開き、ワークベンチでサポートされていない機能を導入する変更を加えた場合、そのドラフトはユースケースにリストされますが、Classicインターフェイス以外からはアクセスできません。
EDA1が終了したとき、ターゲットを設定するには次のどちらかを実行します。
特徴量のリストをスクロールして、ターゲットを見つけます。 見つからない場合は、表示の下部からリストを展開します。
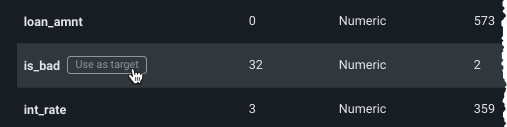
配置されたら、テーブル内のエントリーをクリックして、特徴量をターゲットとして使用します。
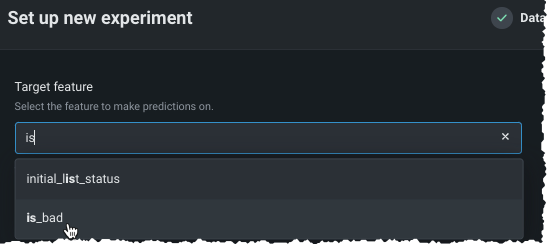
- 予測したいターゲット特徴量の名前を入力ボックスに入力します。 特徴量名の文字を入力するに従って、一致する特徴量がリスト表示されます。
Depending on the number of values for a given target feature, DataRobot automatically determines the experiment type—either regression or classification. Classification experiments can be either binary (binary classification) or more than two classes (multiclass). 次の表は、DataRobotが数値および非数値のターゲットデータ型にデフォルトの問題タイプを割り当てる方法を示しています。
| ターゲットデータ型 | 一意のターゲット値の数 | デフォルトの問題タイプ | Use multiclass classification? |
|---|---|---|---|
| 数値 | 2 | 分類 | いいえ |
| 数値 | 3+ | 連続値 | はい、オプション |
| 数値以外 | 2 | 二値分類 | いいえ |
| 数値以外 | 3-100 | 分類 | はい。自動 |
| 数値以外、数値 | 100+ | Aggregated classification | はい。自動 |
With a target selected, Workbench displays a histogram providing information about the target feature's distribution and, in the right pane, a summary of the experiment settings.
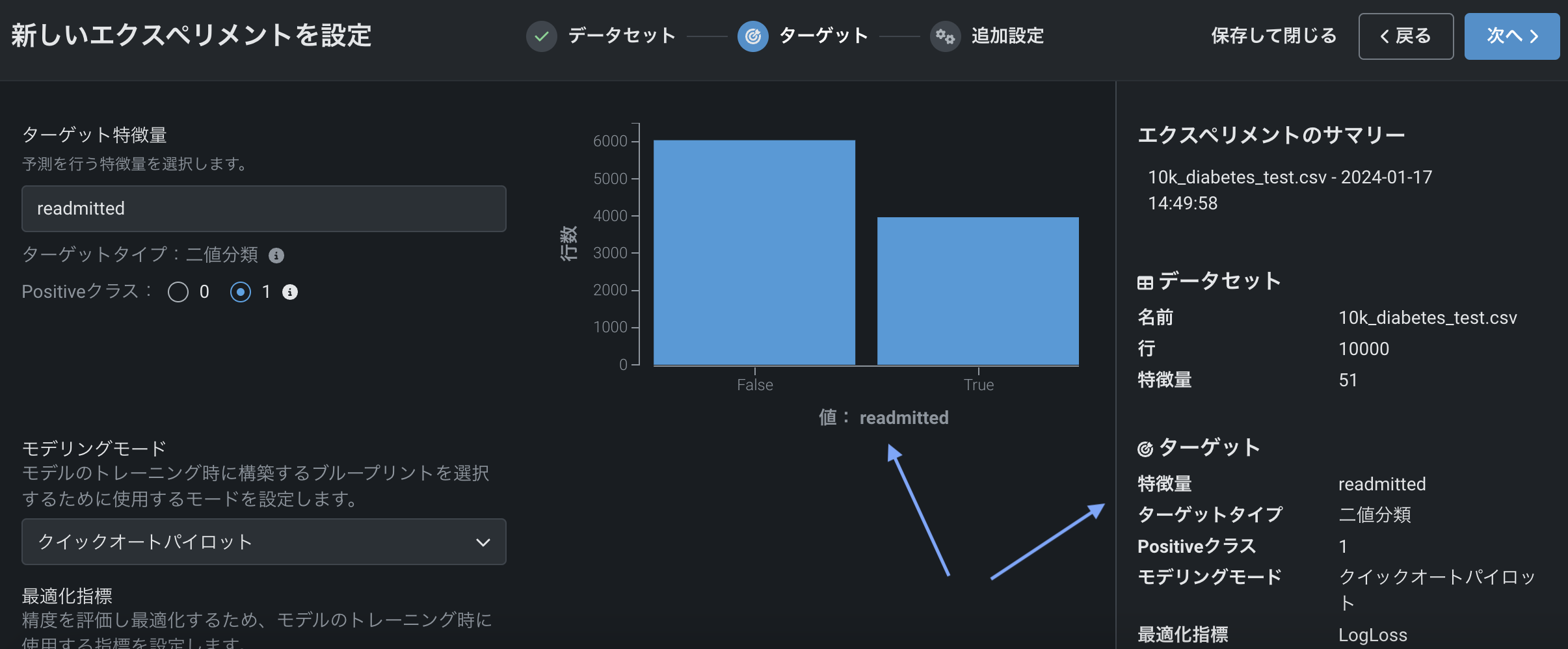
ここでは以下の操作を行うことができます。
-
Change a regression experiment to a multiclass experiment.
-
Click Next to view Additional settings, where you can build models with the default settings or modify those settings.
-
For multiclass classification experiments, click Show more classification settings to further configure aggregation settings.
デフォルト設定を使用する場合は、モデリングを開始をクリックして、 クイックモードのオートパイロットモデリングプロセスを開始します。
Regression targets¶
Regression experiments are those where the target is a numeric value. The regression prediction problem predicts continuous values (e.g., 1.7, 6, 9.8...) given a list of input variables (features). 連続値問題の例には、財務予測、時系列予測、メンテナンスのスケジューリング、および気象分析などがあります。
Regression experiments can also be handled as classification by changing the target type from Numeric to Classification.
| Unique numeric values | Default experiment type | Can change? |
|---|---|---|
| 2 | 二値分類 | いいえ |
| 3+ | 連続値 | はい |
To change regression problem (numeric target) to classification, change the radio button identifying the target type:
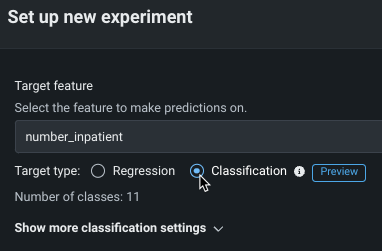
Changing the target type enables the multiclass configuration options. If there are more than 1000 numeric values (classes) for the target, the Aggregate low-frequency classes option, described bleow, is enabled by default.
Classification targets¶
In a classification experiment, the model groups observations into categories by identifying shared characteristics of certain classes. これらの特性を分類しているデータと比較し、観測値が特定のクラスに属する可能性を推定します。 分類プロジェクトは二値(2つのクラス)または多クラス(3つ以上のクラス)に分けることができます。
可用性:プレビュー
Multiclass classification is a preview feature, on by default, for non-time-aware experiments.
機能フラグ: 無制限の多クラス
Configuration of a classification experiment depends on the type (number of classes), which is reported under the target feature entry as either Target type: Binary classification or Target type: Classification, in which case the number of classes is also reported:
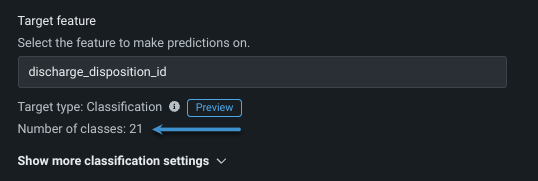
A multiclass confusion matrix helps to visualize where a model is, perhaps, mislabeling one class as another.
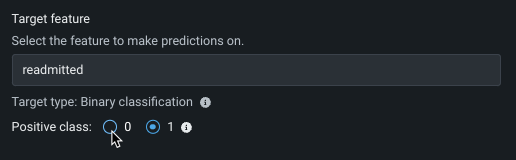
DataRobot creates a binary classification experiment when a target variable has two unique values, whether they are boolean, categorical, or numeric. この例には、顧客が期日までに決済するかどうか(YesまたはNo)、患者が再入院するかどうか(TrueまたはFalse)などがあります。 モデルは、特定の観測値が「ポジティブ」クラス(最後の例ではreadmitted=yes)に分類される予測確率を生成します。 By default, if the predicted probability is 50% or greater, then the predicted class is "positive." You can change the positive class—the class to label as positive in model insights—by selecting the alternate radio button:
一方、多クラス分類問題では、2つ以上の結果(クラス)が提供されます。 For example, which of five competitors will a customer turn to (instead of simply whether or not they are likely to make a purchase), which department should a call be routed to (instead of simply whether or not someone is likely to make a call). In this case, the model generates a predicted probability that a given observation falls into each class; the predicted class is the one with the highest predicted probability. (これは argmaxとも呼ばれます。) 多クラス分類問題でクラスオプションを追加すると、選択式の質問を増やすことができ、より詳細なモデルと解が得られます。
1000クラスをサポートするため、DataRobotは頻度に基づいて、クラスを自動集計して、1000個の一意のラベルにします。 You can configure aggregation settings or, by default, DataRobot will keep the top 999 most frequent classes and aggregate the remainder into a single "other" bucket.
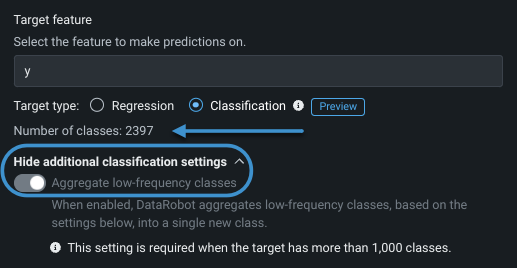
しかし、集計パラメーターを設定して、プロジェクトに必要なすべてのクラスが表示されるように設定することもできます。 To configure, first expand Show more classification settings and then toggle Aggregate low-frequency classes on.
The following table describes aggregation-related settings:
| 設定 | 説明 | デフォルト |
|---|---|---|
| 低頻度のクラスを集計 | Enables the aggregation functionality, with the default setting based on the number of classes detected. | OFF for targets with fewer than 1000 values. ON for targets with 1000+ values and cannot be disabled. |
| 集計されたクラス名 | "Other" bin(この集計プランの設定に該当しないすべてのクラスを含むビン)の名前を設定します。 これはデータセットで除外された値のすべての行を表します。 列内の既存のターゲット値とは異なる名前を指定する必要があります。 | 集計済み |
| 集計方法 | Frequency threshold: Sets the minimum occurrence of rows belonging to a class that is required to avoid being bucketed in the "other" bin. つまり、インスタンスの数が少ないクラスは、1つのクラスに折りたたまれます。 総クラス数:集計後のクラスの最終的な数を設定します。 最後のクラスは"Other" binです。 たとえば、900と入力した場合、データからの899クラスのbinと、集約されたクラスの"Other" bin 1つが存在することになります。 Enter a value between 3-1000 (the maximum allowed number of classes). |
頻度のしきい値, 1行 |
| 集計から除外されるクラス | 集計から保護されるクラスのコンマ区切りリストを指定し、対象となる頻度の低いクラスについて予測できるようにします。 | なし。オプション |
基本設定のカスタマイズ¶
エクスペリメントパラメーターを変更することは、ユースケースで同じ手順を繰り返すよい方法です。 モデリングを開始する前に、さまざまな設定を変更できます。
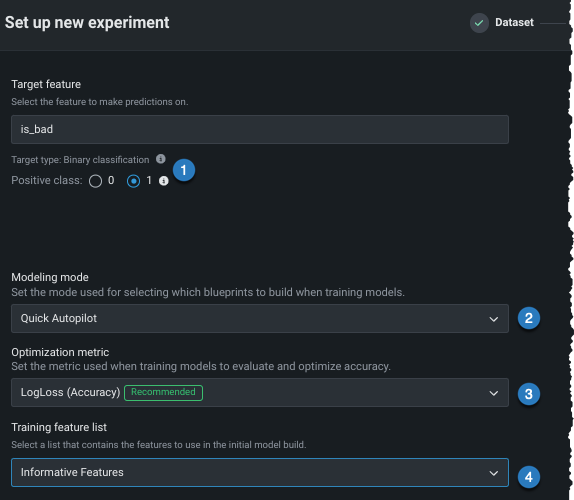
| 設定 | 変更対象 | |
|---|---|---|
| Positiveクラス | 二値分類プロジェクトの場合のみ。 予測スコアが分類しきい値よりも高い場合に使用するクラス。 | |
| モデリングモード | モデリングモード。DataRobotがトレーニングするブループリントに影響します。 | |
| 最適化指標 | DataRobotで推奨されているものとは異なる最適化指標に変更します。 | |
| トレーニング特徴量セット | DataRobotでモデルの構築に使用する特徴量のサブセット。 |
説明された設定の一部またはすべてを変更した後、次へをクリックして、以下のいずれかを実行します。
モデリングモードの変更¶
デフォルトでは、DataRobotはクイックオートパイロットを使用してエクスペリメントを構築します。 ただし、モデリングモードを変更することで、特定のブループリントまたは該当するすべてのリポジトリブループリントをトレーニングすることもできます。
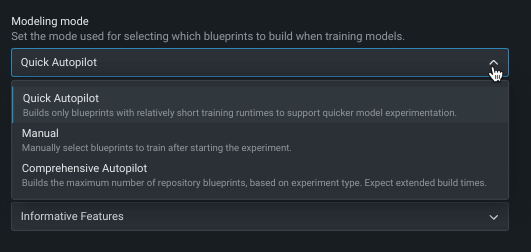
以下の表では、各モデリングモードについて説明しています。
| モデリングモード | 説明 |
|---|---|
| クイック(デフォルト) | クイックオートパイロットでは、最初に32%のサンプルサイズを使用し、その後に64%のサンプルサイズを使用して、指定されたターゲット特徴量とパフォーマンス指標に基づいてモデルのサブセットを実行し、モデルのベースセットとインサイトをすばやく提供します。 |
| 手動 | 手動モードでは、実行するブループリントを完全に管理できます。 After EDA2 completes, DataRobot redirects you to the blueprint repository where you can select one or more blueprints for training. |
| 包括的 | モデルの精度を高めるために、最大のオートパイロットサンプルサイズですべてのリポジトリブループリントを実行する包括的なオートパイロットモード。 このモードでは構築時間が大幅に長くなります。 |
最適化指標の変更¶
最適化指標は、DataRobotによるモデルのスコアリング方法を定義します。 ターゲット特徴量を選択した後、モデリングタスクに基づいて最適化メトリックが選択されます。 通常、モデルのスコアリングのために DataRobotが選択する指標が、エクスペリメントに最適な選択です。 推奨された指標を上書きし、別の指標を使用してモデルを構築するには、最適化指標ドロップダウンを使用します。
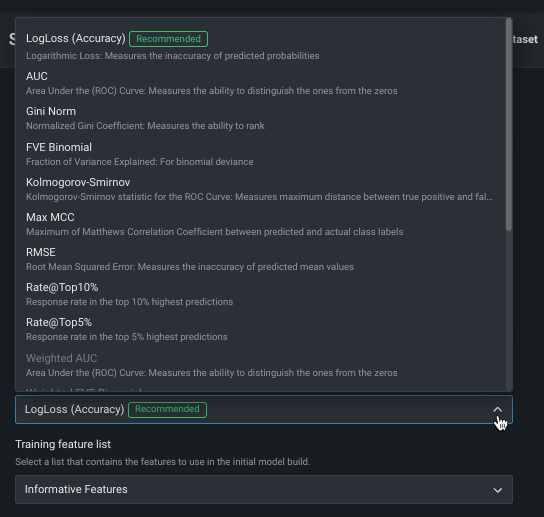
利用可能な指標の完全なリストと説明については、リファレンス資料を参照してください。
特徴量セットの変更(モデリング前)¶
特徴量セットは、DataRobotでモデルの構築に使用する特徴量のサブセットを制御します。 デフォルトでは 有用な特徴量セットですが、モデル構築の前に変更できます。 変更するには、特徴量セットドロップダウンをクリックし、別のセットを選択します。
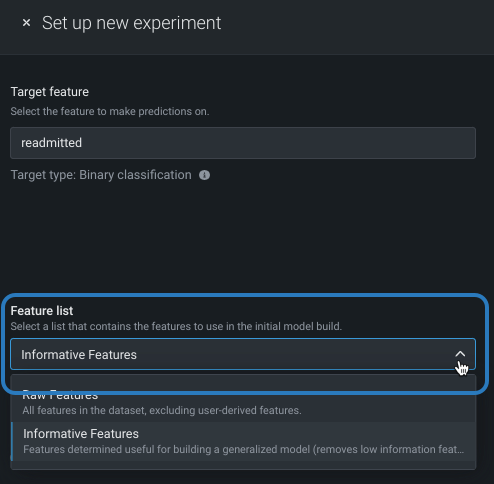
エクスペリメントの構築が終了したら、モデルごとに 選択済みリストを変更することもできます。
追加の自動化を設定¶
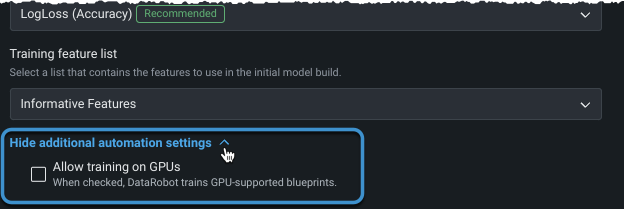
高度な設定に移動する前に、またはモデリングを開始する前に、他の自動化を設定できます。
ターゲットを設定し、基本設定を表示した後、追加の自動化設定を表示を展開して、追加のオプションを表示します。
GPUでのトレーニング¶
本機能の提供について
GPUワーカーはプレミアム機能です。 この機能を有効にする方法については、DataRobotの担当者にお問い合わせください。
テキストや画像を含み、ディープラーニングモデルを必要とするデータセットの場合、 GPUでのトレーニングを選択すると、トレーニング時間を短縮できます。 一部のモデルはCPU上で実行できますが、他のモデルでは、適切なレスポンス時間を実現するためにGPUが必要です。 GPUでのトレーニングを許可するを選択すると、DataRobotは特定のタスクを含むブループリントを検出し、オートパイロットの実行にGPU対応のブループリントを含めます。 GPUバリアントとCPUバリアントの両方がリポジトリに用意されており、トレーニングに使用するワーカーのタイプを選択できます。GPUバリアントのブループリントは、GPUワーカーでより速くトレーニングできるように最適化されています。 GPUの使用については、以下の点を考慮してください。
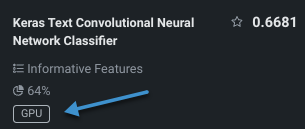
- Once the Leaderboard populates, you can easily identify GPU-based models using filtering.
- モデルを 再トレーニングすると、結果として得られるモデルもGPUを使用してトレーニングされます。
- 手動モードを使用すると、 ブループリントリポジトリでフィルターすることでGPU対応のブループリントを識別できます。
- 最初にGPUでトレーニングするように選択しなかった場合、リポジトリを介して、またはモデリングを再実行することで、GPU対応のブループリントを追加できます。
-
GPUでトレーニングされたモデルは、リーダーボードでバッジが付けられます。
高度な設定をカスタマイズ¶
トレーニングの前に、より高度なモデリング条件を適用するには、オプションで以下の操作を行うことができます。
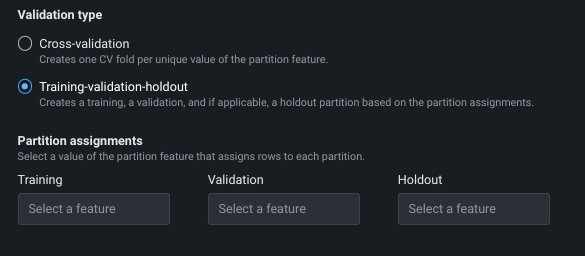
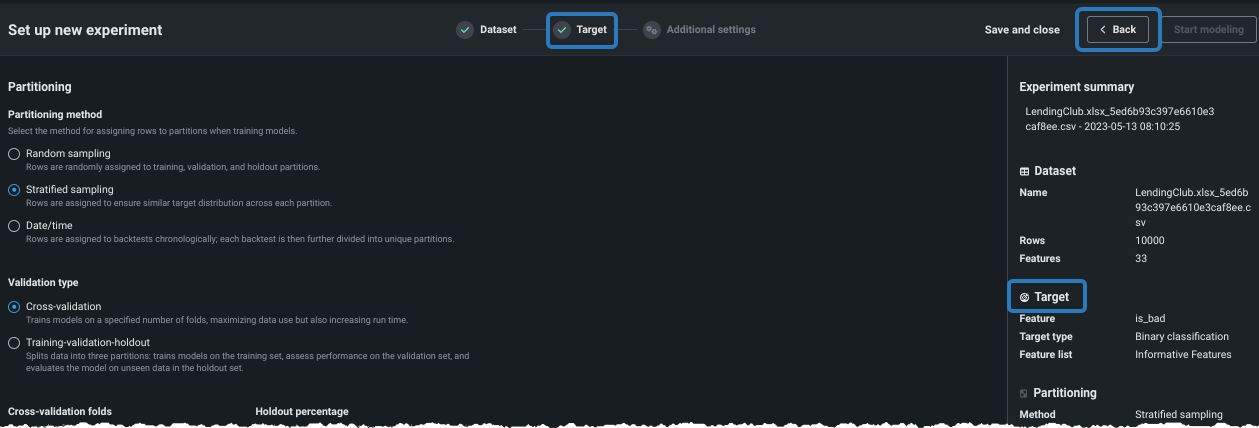
データパーティショニングタブ¶
パーティショニングは、評価とモデル構築のためにDataRobotが観測値(または行)をまとめて「集中させる」方法を示します。 ワークベンチのデフォルトは、 層化サンプリング(二値分類エクスペリメントの場合)またはランダム(連続値エクスペリメントの場合)による 5分割交差検定、および20%のホールドアウト分割です。
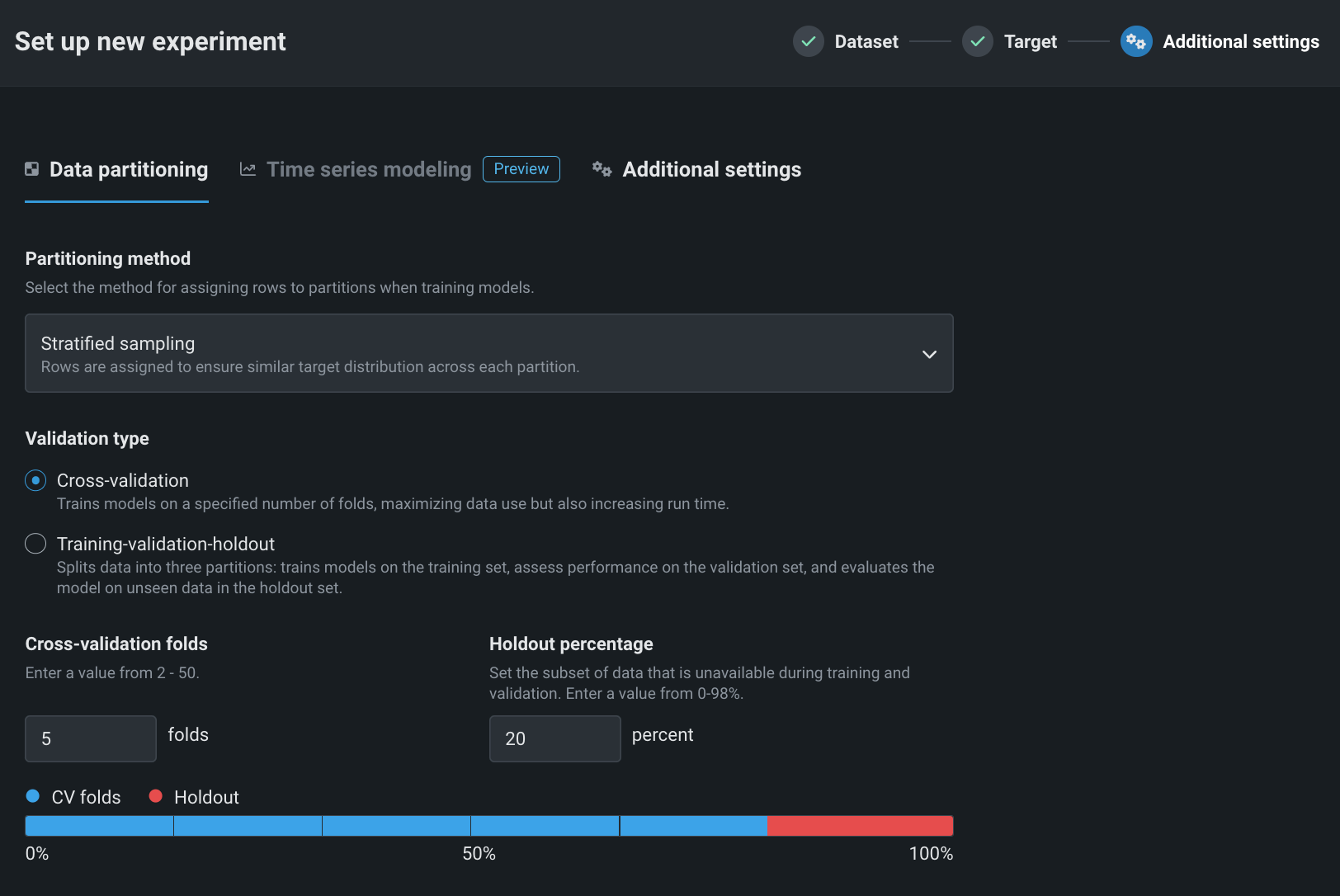
備考
日付特徴量が使用可能な場合、エクスペリメントは日付/時刻パーティションに適格です。日付/時刻パーティションでは、行がランダムではなく時系列でバックテストに割り当てられます。 時間認識プロジェクトで唯一有効な分割手法。 詳細については、時間認識モデリングのドキュメントを参照してください。
分割手法または検定タイプを追加設定から変更するか、サマリーのパーティショニングフィールドをクリックして変更します。
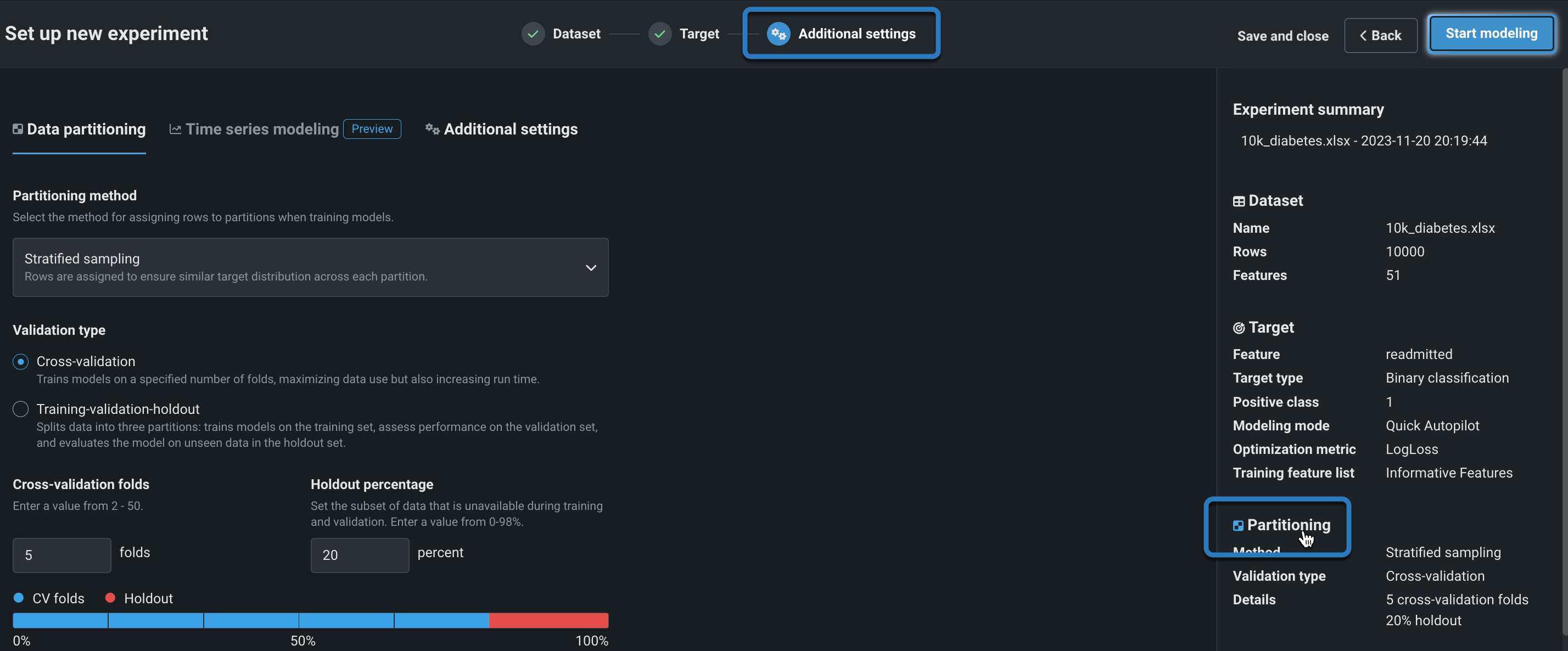
分割手法の設定¶
分割手法では、モデルのトレーニング時に行を割り当てる方法をDataRobotに指示します。 分割手法と検定タイプの選択は、ターゲット特徴量およびパーティション列に依存します。 つまり、すべての選択が常に使用可能として表示されるわけではないということです。 次の表は、各手法を簡単に説明しています。パーティショニングの詳細については、 このセクションも参照してください。
| 方法 | 説明 |
|---|---|
| 層化抽出 | 行は、トレーニングデータ、検定、ホールドアウトセットにランダムに割り当てられ、元のデータと同じ(可能な限り近い)予測ターゲット値の比率が保持されます。 これは、二値分類問題のデフォルトの手法です。 |
| ランダム | DataRobotでは、行がトレーニング、検定、ホールドアウトセットにランダムに割り当てられます。 これは、連続値問題のデフォルトの手法です。 |
| ユーザー定義のグループ化 | この特徴量の値と検定パーティションの間で1対1のマッピングが作成されます。 それぞれの一意の値には独自のパーティションが割り当てられ、その値を含むすべての行がそのパーティションに配置されます。 この方法は、カーディナリティが低いパーティション特徴量に推奨されます。 以下の、 グループ化によるパーティションを参照してください。 |
| 自動グループ化 | 選択した特徴量に対して同じ単一の値を含むすべての行は同じトレーニングまたはテストセットに含まれることが保証されます。 各パーティションには特徴量の1つ以上の値を含めることができますが、個々の値はDataRobotによって自動的に一緒にグループ化されます。 この方法は、カーディナリティが高いパーティション特徴量に推奨されます。 以下の、 グループ化によるパーティションを参照してください。 |
| 日付/時刻 | 時間認識エクスペリメントを参照してください。 |
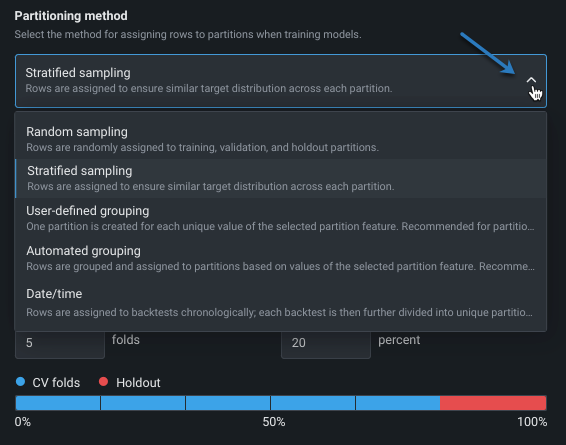
検定タイプの設定¶
検定タイプは、モデルを検証するためにデータで使用される方法を設定します。 方法を選択し、関連するフィールドを設定します。 設定フィールドの下のグラフィックは、設定を示します。 ユーザー定義または自動化されたグループパーティショニングを使用する場合は、検定タイプの説明を参照してください。
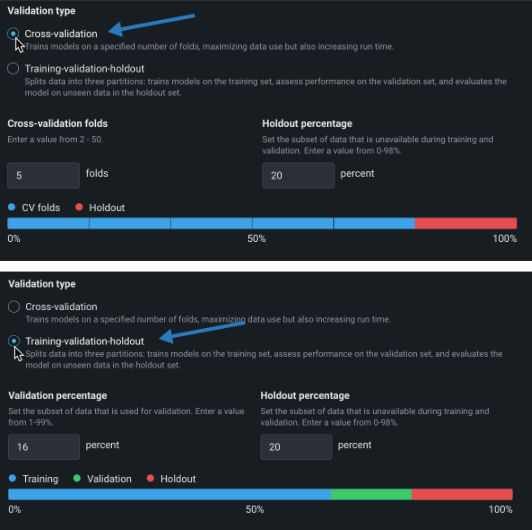
| フィールド | 説明 |
|---|---|
| 交差検定:2つ以上の“分割”にデータを分離し、分割ごとに1つのモデルを作成します。その分割に割り当てられたデータは検定に使用され、それ以外のデータはトレーニングに使用されます。 | |
| 交差検定の分割数 | 交差検定手法で使用する分割数を設定します。 数値を大きくすると、各分割で使用可能なトレーニングデータサイズが増加し、合計トレーニング時間が長くなります。 |
| ホールドアウトの割合(%) | トレーニング時にワークベンチが「非表示」にするデータの割合を設定します。 リーダーボードは、ホールドアウト値を表示します。これは、ホールドアウトパーティションに対してトレーニング済みモデルの予測を使用して計算されます。 |
| トレーニング-検定-ホールドアウト:データセットが大きい場合、データをトレーニング、検定、ホールドアウトの3つのセクションに分割し、データの1回のパスに基づいて予測します。 | |
| 検定の割合 | トレーニング時にワークベンチが「非表示」にするデータの割合を設定します。 |
| ホールドアウトの割合(%) | トレーニング時にワークベンチが「非表示」にするデータの割合を設定します。 リーダーボードは、ホールドアウト値を表示します。これは、ホールドアウトパーティションに対してトレーニング済みモデルの予測を使用して計算されます。 |
備考
データセットが800 MBを超える場合、すべての分割手法で使用可能な検定タイプはトレーニング-検定-ホールドアウトだけです。
グループ化によるパーティション¶
あまり一般的ではありませんが、ユーザー定義および自動化されたグループ分割では、グループ化の基礎となるデータセットの特徴量を _パーティション特徴量_で分割する方法が行われます。
-
_ユーザー定義のグループ化_では、選択したパーティション特徴量の一意の値ごとにパーティションが作成されます。 つまり、行は、選択したパーティション特徴量の値を使用してパーティションに割り当てられ、一意の値ごとに1つのパーティションになります。 この方法を選択すると、パーティション特徴量の一意の値が10未満である特徴量を指定することが推奨されます。
-
_自動化されたグループ化_では、パーティション特徴量の同じ単一(指定)値を持つすべての行が同じパーティションに割り当てられます。 各パーティションには、その特徴値が複数含まれることがあります。 この方法を選択すると、DataRobotにより一意の値が6以上である特徴量を指定することが推奨されます。
これらの方法のいずれかを選択すると、パーティション特徴量を入力するように求められます。 ヘルプテキストからは、パーティション特徴量に含める必要のある値の数に関する情報が得られます。ドロップダウンをクリックして、一意の値の数を含む特徴量を表示します。
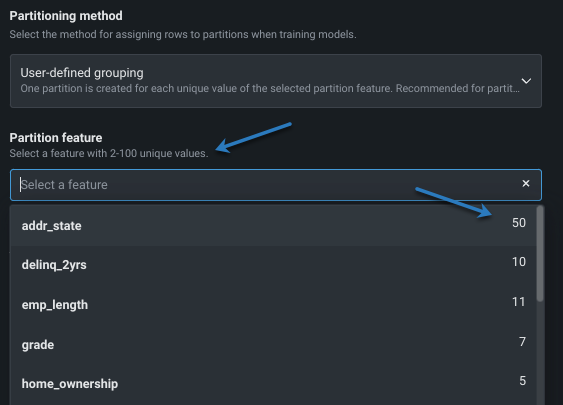
パーティション特徴量の選択後、検定タイプを設定します。 検定タイプの適用性は、次のチャートに示すように、パーティション特徴量の一意の値に依存します。

自動化されたグループ化では、上記と同じ 検定設定が使用されます。 しかし、ユーザー定義のグループ化では、パーティション特徴量に固有の値の入力が求められます。 _交差検定_の場合、ホールドアウトの設定はオプションです。 設定する場合は、パーセンテージではなくパーティション特徴量の値を選択します。 _トレーニング-検定-ホールドアウト_の場合、ここでもパーセンテージではなく、各セクションのパーティション特徴量の値を選択します。
追加設定を行う¶
より高度なモデリング機能を設定するには、追加設定タブを選択します。 時系列モデリングタブについては、データセットで日付/時刻特徴量が見つかったかどうかに応じて、使用可能になるかグレーアウトされます。
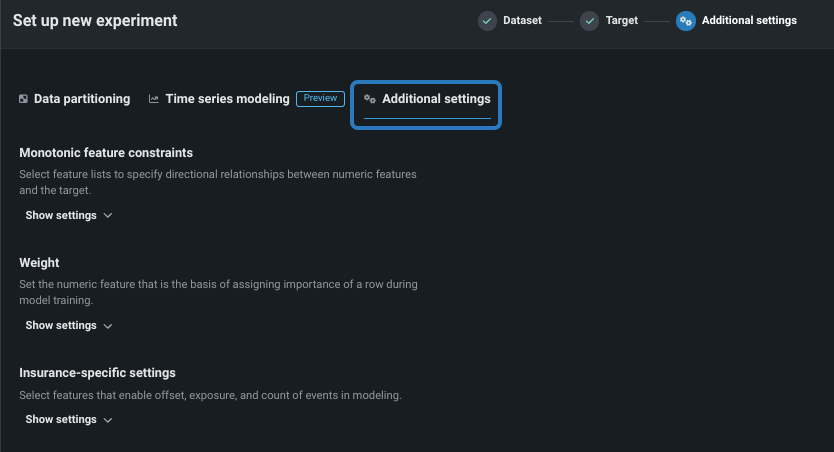
ビジネスユースケースに応じて、以下を設定します。
単調特徴量制約¶
単調制約は、特徴量とターゲットの間の上下方向の影響を制御します。 一部のプロジェクト(保険業や銀行業など)では、特徴量とターゲットの間の方向関係性を強制することが望ましい場合があります(評価価値の高い家屋の火災保険料が常に高くなるなど)。 単調制約でのトレーニングを行うことによって、特定のXGBoostモデルに特定の特徴量とターゲットの間の単調(常に増加または常に減少)関係性を学習させます。
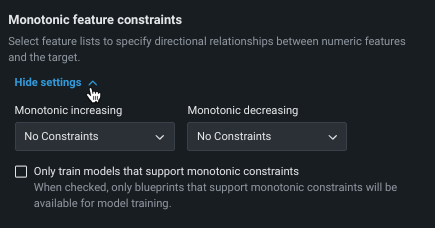
単調制約特徴量を使用するには、 特殊な特徴量セットを作成する必要があります。この特徴量セットは、ここで選択されます。 また、手動モードを使用する場合、使用可能なブループリントにはMONOバッジが付けられ、サポートされるモデルを識別できます。
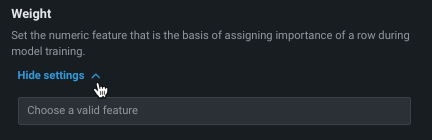
ウェイト¶
ウェイト違いを表す重みとして使用し、各行の相対的な有用性を示す単一の特徴量を設定します。 これは、モデルの構築やスコアリングの際に、リーダーボードで指標を計算する目的で使用されます。新しいデータで予測を行う目的では使用されません。 選択した特徴量のすべての値が0より大きい値である必要があります。DataRobotでは検定が行われ、選択した特徴量にはサポートされている値のみが含まれているかどうかが確認されます。
保険特有の設定¶
保険業界の頻繁な加重ニーズに対処するいくつかの機能を利用できます。 次の表では各モデルについて簡単に説明しますが、詳細については、 ここを参照してください。
| 設定 | 説明 |
|---|---|
| エクスポージャー | 連続値問題のターゲット予測において厳密な比例関係で処理される特徴量を設定し、保険料率をモデリングする際にエクスポージャーの指標を追加します。 DataRobotでは、エクスポージャーで選択された特徴量は特殊な列として扱われ、モデルの構築やスコアリングの際に元の予測に追加されます。選択した列は、予測のために後でアップロードするすべてのデータセットに存在する必要があります。 |
| イベント数 | ゼロ以外のイベントの頻度に関する情報を追加することで、ゼロ過剰ターゲットのモデリングを改善します。 |
| オフセット | 各サンプルでモデルの切片(線形モデル)またはマージン(ツリーベースモデル)を調整するもので、複数の特徴量を受け付けます。 |
設定を変更します。¶
ターゲットページに戻ることで、モデリングを開始する前に、プロジェクトのターゲットまたは特徴量セットを変更できます。 戻るには、サマリーのターゲットアイコン、戻るボタン、またはターゲットフィールドをクリックします。
次のアクション¶
モデリングを開始すると、DataRobotでリーダーボードにモデルが入力されます。 以下を実行することが可能です。
- Use the View experiment info option to view a variety of information about the experiment.
- 使用可能なモデルで モデル評価を開始します。