エクスペリメントの評価¶
リーダーボードから、モデルをクリックしてインサイトにアクセスして、さらに詳しく調べることができます。 これらのツールは、次のエクスペリメントで何をする必要があるかを判断するのに役立ちます。
モデルのインサイト¶
モデルのインサイトは、モデルによる予測の根拠を解釈、説明、検定するのに役立ちます。 使用可能なインサイトはエクスペリメントタイプによって異なりますが、以下の表にリストされているインサイトが含まれる場合があります。 スライスされたインサイトが利用できるかどうかもモデルに依存します。
本機能の提供について
- ワークベンチでのスライスされたインサイトは、デフォルトではオフになっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。 機能フラグ: ワークベンチのスライス
- 特徴量ごとの作用は、デフォルトでは オフ になっています。 この機能を有効にする方法については、DataRobotの担当者または管理者にお問い合わせください。 機能フラグ: ワークベンチのスライス
| インサイト | 説明 | 問題のタイプ | スライスされたインサイト? |
|---|---|---|---|
| 時系列の精度 | 時間経過に伴う予測がどのように変化するかを視覚化します。 | 時間認識 | |
| ブループリント | データの前処理とパラメーター設定を表すグラフを提供します。 | すべて | |
| 特徴量ごとの作用 | 各特徴量の値の変化によってモデル予測がどのように変化するかを示します | すべて | ✔ |
| 特徴量のインパクト | モデルの決定を推進している特徴量を表示します。 | すべて | ✔ |
| 予測距離ごとの精度 | エクスペリメントの予測ウィンドウの各予測距離でのモデルの予測精度を描写します。 | 時系列 | |
| 予測値と実測値の比較 | 各時点の複数の値(予測距離)が予測されます。 | 時系列 | |
| リフトチャート | モデルがターゲットの母集団をどの程度うまく分割しているか、そしてターゲットを予測することができるかを示します。 | すべて | ✔ |
| 期間精度 | トレーニングデータセット内の期間全体でのモデルパフォーマンスを表示します。 | 時間認識 | |
| ROC曲線 | モデルに関連した分類、パフォーマンス、および統計を調べるためのツールを提供します。 | 分類 | ✔ |
| 系列のインサイト | 複数系列エクスペリメントの系列固有の情報が得られます。 | 時系列 | |
| 安定性 | さまざまなバックテストにおけるモデルのパフォーマンスを把握できるサマリーを提供します。 | 時間認識 |
モデルのインサイトを表示するには、左ペインのリーダーボードでモデルをクリックします。
時系列の精度¶
時間認識エクスペリメントでは、 時系列の精度により時系列での予測がどのように変化するかを視覚化します。 デフォルトでは、最新(最初)のバックテストのトレーニングデータおよび検定データの予測値および実測値と時間値の比較が表示されます。 これは、予測のデプロイと作成に使用されるバックテストモデルです。 (つまり、検定セットのエラー指標の生成に使用するモデルです。) 時系列エクスペリメントの場合、表示で使用する系列(該当する場合)および予測距離を制御できます。 系列ベースのエクスペリメントは、計画されたスペースとメモリー要件に応じて、 オンデマンドで計算されることがあることに注意してください。
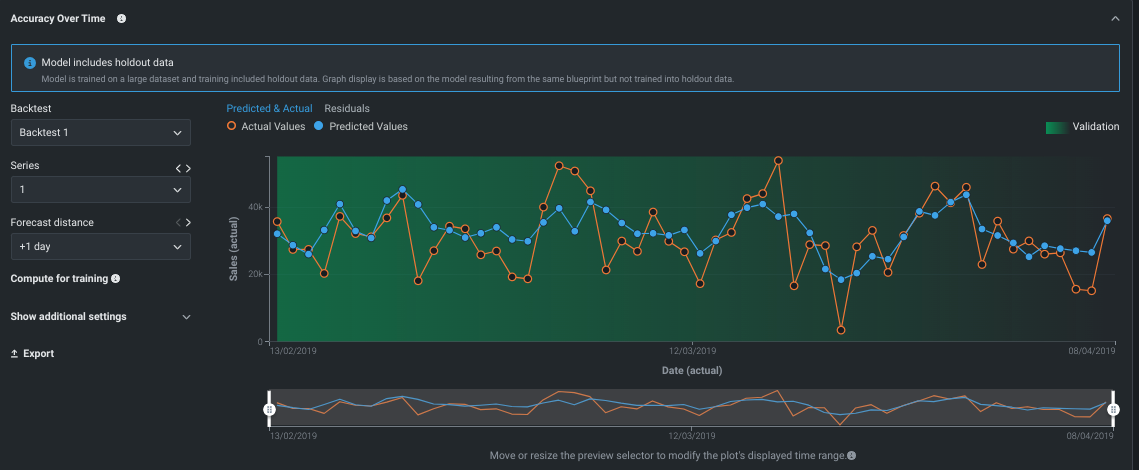
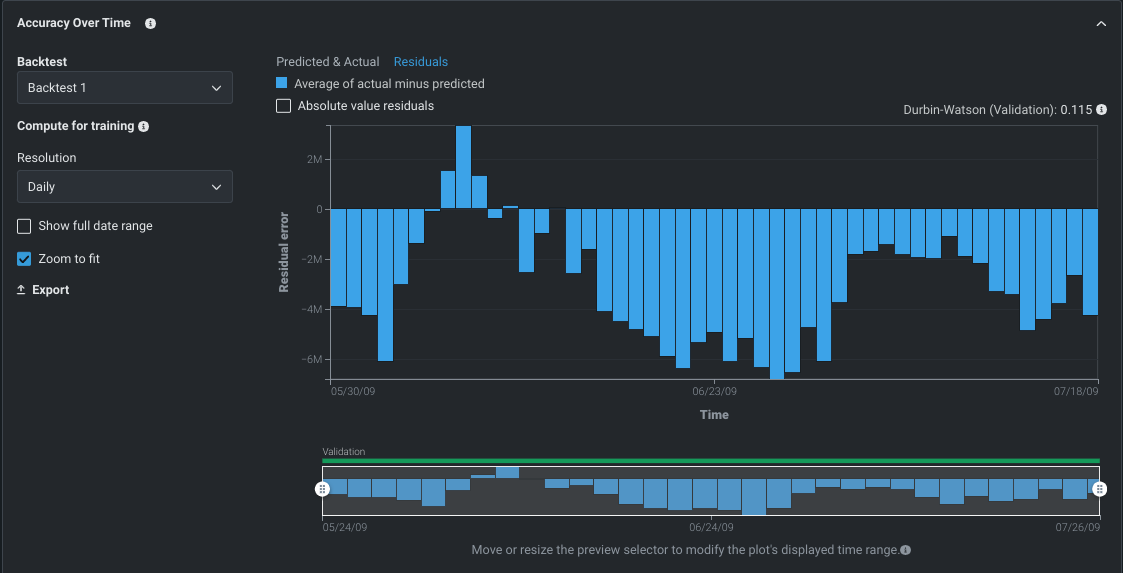
視覚化には、実測値と予測値の差分をプロットする時間認識 残差タブもあります。 データ内にモデルで考慮されておらず説明されないトレンドがあるかどうか、および時間の経過に伴うモデルの誤差の変化を可視化するために役立ちます。 時系列エクスペリメントの場合、表示で使用する予測距離を追加で設定できます。
ブループリント¶
ブループリントは、モデル構築に必要な前処理のステップ(タスク)、モデリングアルゴリズム、後処理のステップを含むMLパイプラインです。 ブループリントタブには、各ステップを示すブループリントのグラフィック表現を表示します。 ブループリント内のタスクをクリックすると、より完全なモデルドキュメント(ブループリントのタスク内からDataRobot Model Docsをクリック)を始めとする詳細が表示されます。
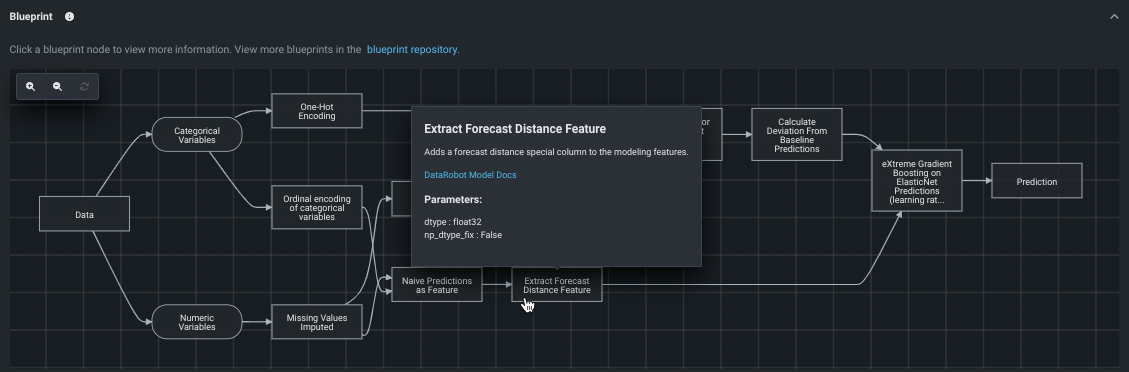
さらに、 ブループリントリポジトリに、ブループリントタブからアクセスできます。
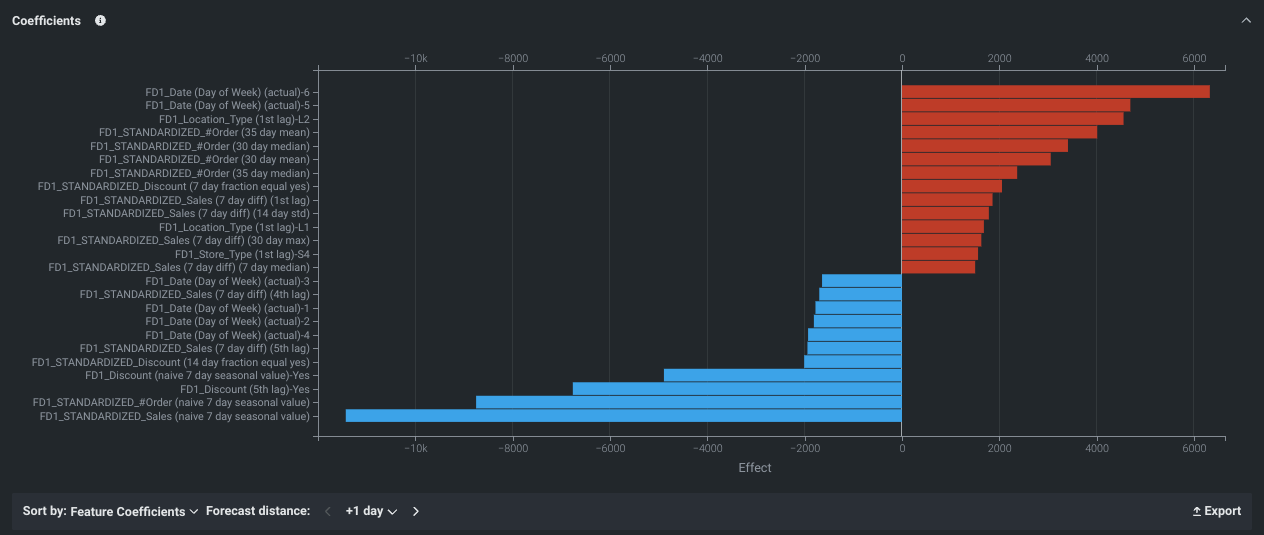
係数¶
サポートされているモデル(線形回帰およびロジスティック回帰)では、係数タブには、最も有用な30個の特徴量の相対的な影響が、(デフォルトでは)最終的な予測への影響が大きい順に並べ替えて表示されます。 positive効果のある特徴量は赤色で表示され、negative効果のある特徴量は青色に表示されます。 係数チャートは、モデル結果の評価に役立てるため、下記を判断します。
- そのモデルでの予測形成にどの特徴量が選択されたのか?
- 各特徴量の重要性はどの程度なのか?
- どの特徴量がプラスやマイナスの影響を与えるのか?
係数タブは、限られたモデルに対してのみ利用可能であることに注意してください。なぜなら、複雑なモデルの係数を短い解析形式で導き出すことは必ずしも可能ではないからです。
インサイトから、選択したモデルで予測を生成するためにDataRobotで使われるパラメーターと係数をエクスポートできます。
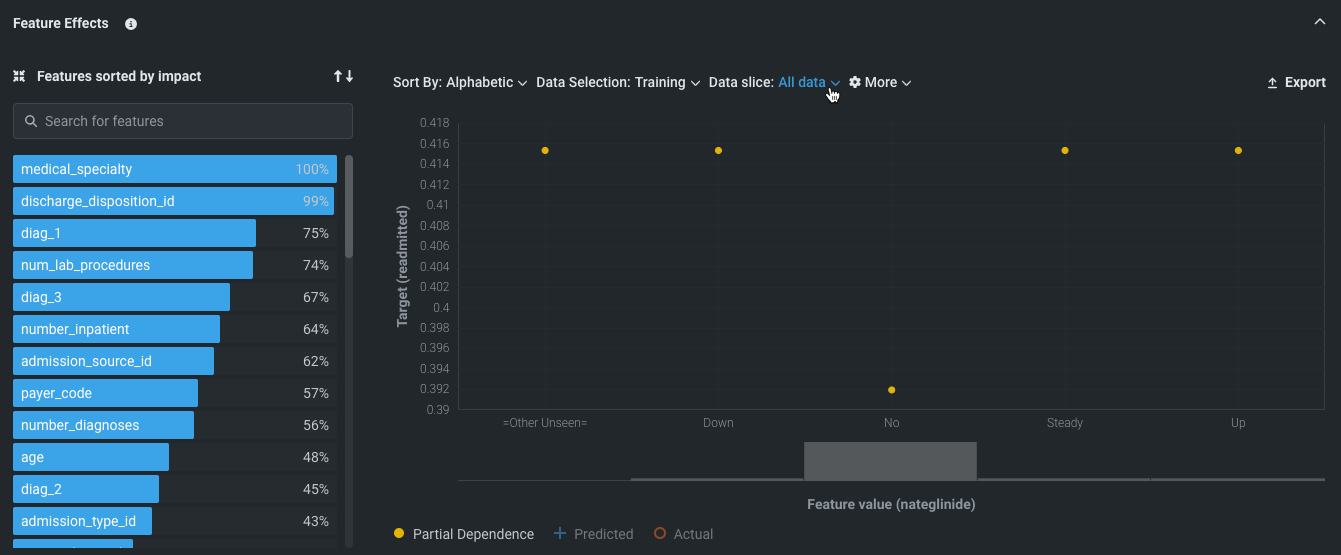
特徴量ごとの作用¶
特徴量ごとの作用のインサイトは、各特徴量の値の変化がモデル予測に与える影響を示します。モデルは各特徴量とターゲットの関係性をどのように「理解」しているのでしょうか? これはオンデマンドの機能で、最初に視覚化を開いたときに求められる 特徴量のインパクトの計算に依存します。 インサイトは、他のすべての特徴量が変化せずに維持された状態で1つの特徴量の値の変化によってモデルの予測にどのような影響が生じるかを示す 部分依存の観点から表示されます。
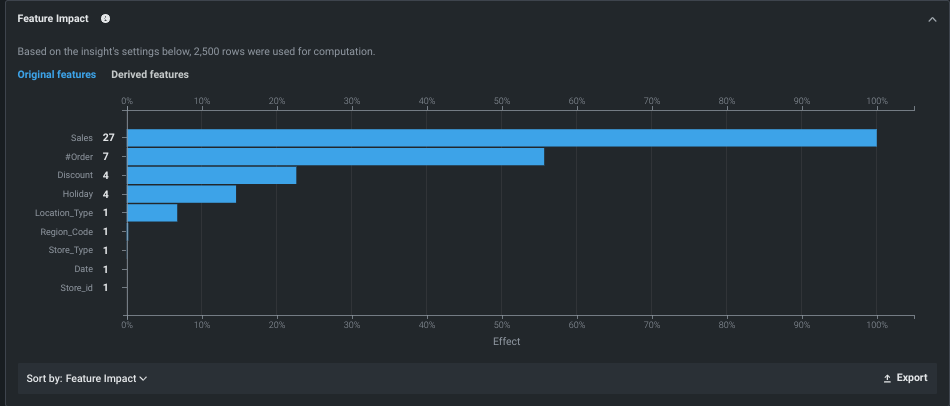
特徴量のインパクト¶
特徴量のインパクト モデルの決定を最も強力に推進している特徴量の高レベルの視覚化を提供します。 これはすべてのモデルタイプで使用可能で、オンデマンドの特徴量です。つまり、デプロイ用に準備されたモデルを除くすべてのモデルで、結果を表示するには計算を開始する必要があります。
- 特徴量の名前やバーにカーソルを合わせると、追加情報が表示されます。
- ソート条件を使用して、インパクトまたは特徴量名でソートするように表示を変更します。
元の特徴量のインパクトを表示できます。
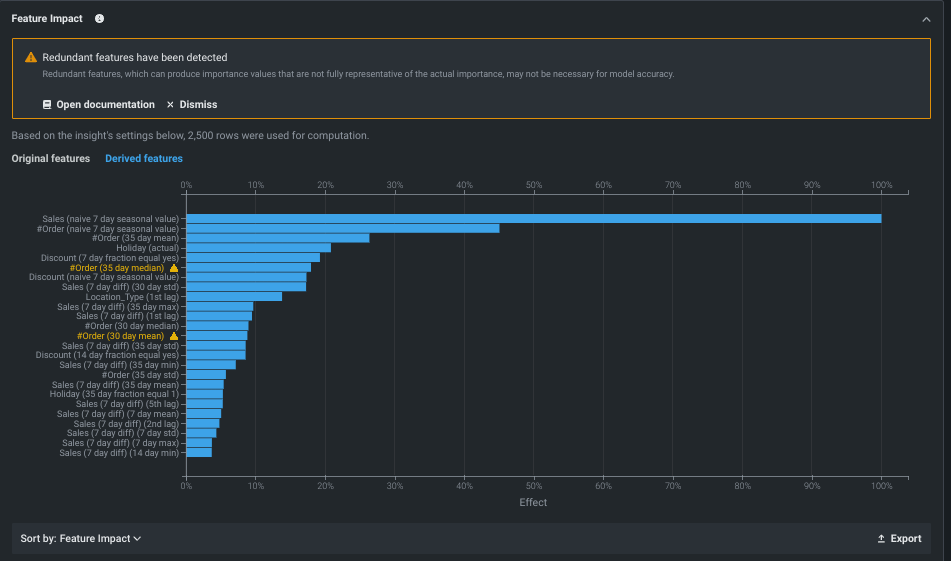
また、 派生したモデリングデータのインパクトも確認できます。
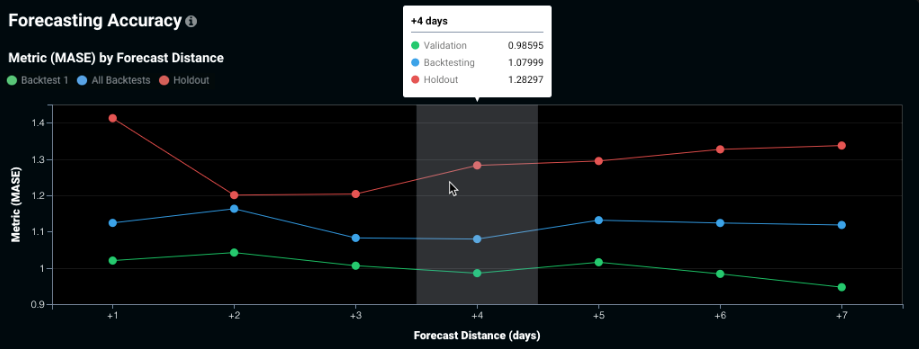
予測距離ごとの精度¶
予測距離ごとの精度タブはエクスペリメントの予測ウィンドウの各予測距離でのモデルの予測精度を視覚的に表示します。 このタブは、すべての時系列エクスペリメント(単一系列と複数系列の両方)で使用可能です。 このタブは、2日間に比べて4日間の正確な予測を行う場合の難易度などを特定する際などに役立ちます。 チャートには、将来における時間経過に伴う精度の変化が示されます。
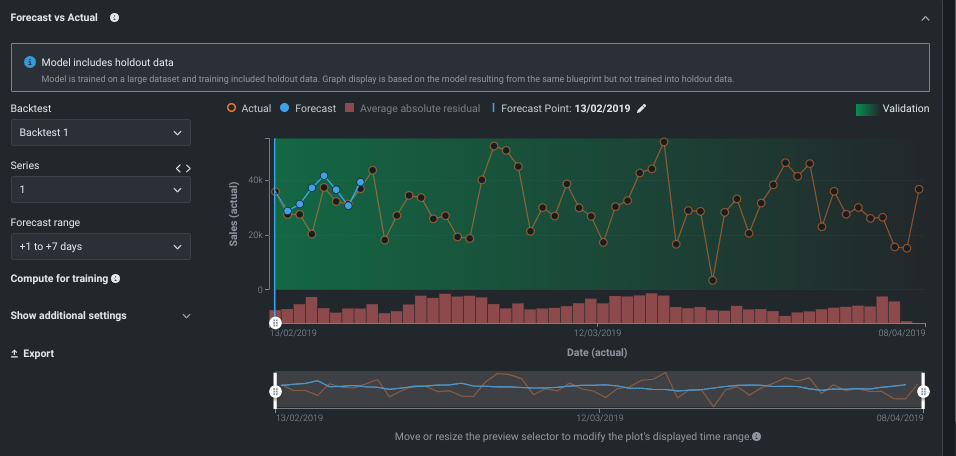
予測値と実測値の比較¶
予測値と実測値の比較では、さまざまな予測ポイントからさまざまな予測がどのように動作するかを将来のさまざまな時間で比較できます。 チャートを使用して、予測に最適な距離を判断することができます。 1日だけの予測で最良の結果が得られる場合がありますが、ビジネスにとって最も実用的なものではない場合があります。 ただし、今後3日間の予測は比較的精度が高く、提供された情報に対応する時間が生まれる可能性があります。 エクスペリメントにカレンダーデータが含まれている場合、これらのイベントはこのグラフに表示されるのでイベントの影響に関するインサイトを取得できます。 系列ベースのエクスペリメントは、計画されたスペースとメモリー要件に応じて、 オンデマンドで計算されることがあることに注意してください。
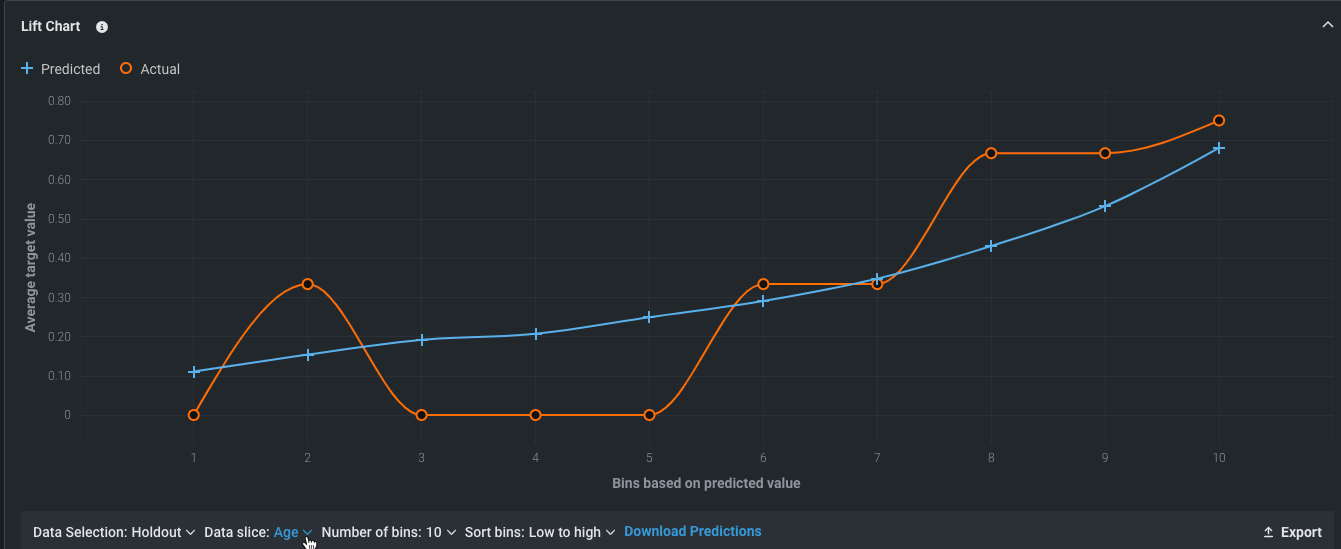
リフトチャート¶
モデルの有効性を視覚化するために、 リフトチャートは、モデルがターゲット母集団をどの程度適切にセグメント化しているか、およびターゲット特徴量の値のさまざまな範囲に対して、モデルのパフォーマンスがどの程度良好かを示します。
- 任意のポイントにカーソルを合わせると、そのビンの行の予測値スコアと実測値スコアが表示されます。
- 表示条件を変更するにはコントロールを使用します
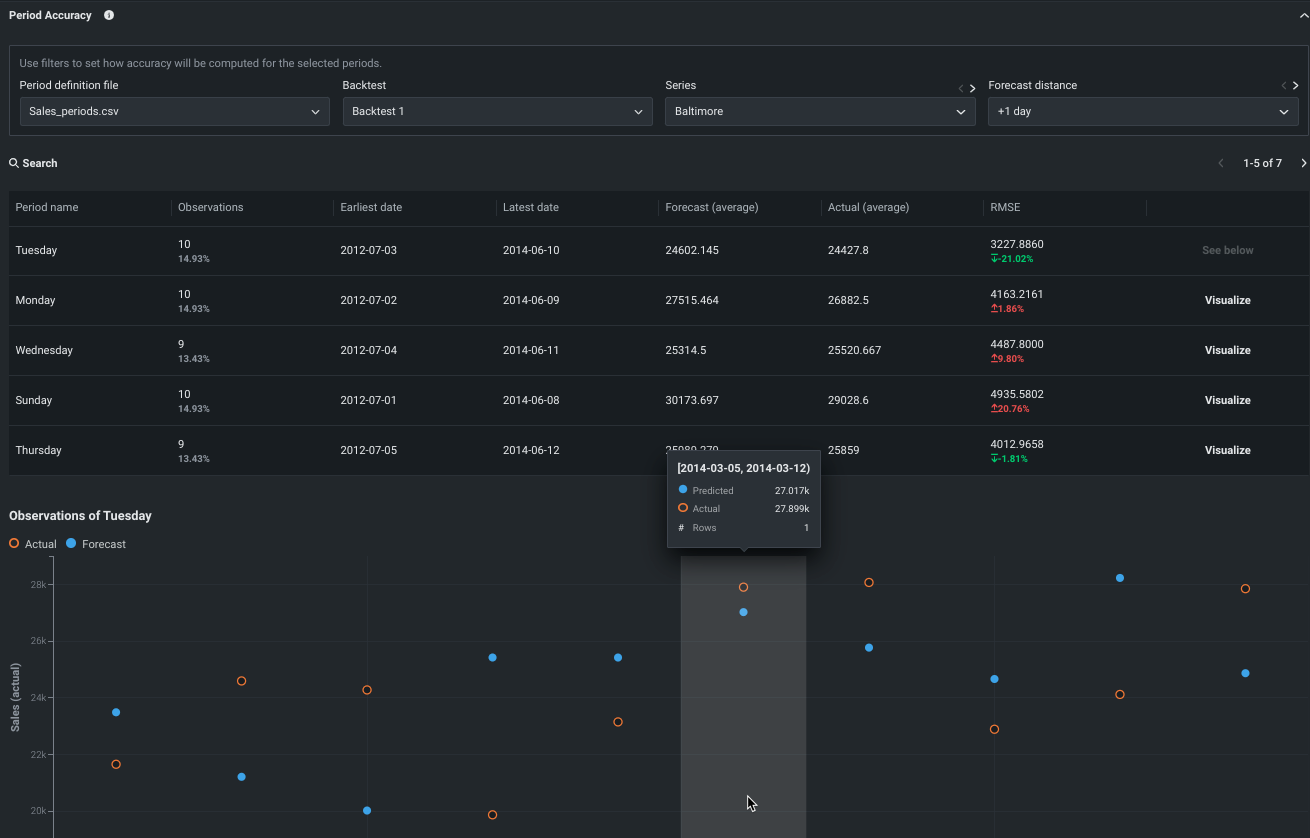
期間精度¶
期間精度では、トレーニングデータセット内でより有用性の高い期間を指定できます。これにより、DataRobotは、その期間の精度指標を集計して、結果をリーダーボードに表示することができます。
期間の精度では、データセット内の期間を定義し、その指標スコアをモデル全体の指標スコアと比較できます。 言葉を変えて言えば、トレーニングデータセット内でより有用性の高い期間を指定できます。そしてDataRobotは、その期間の精度指標を集計して、結果をリーダーボードに表示することができます。 期間は、エクスペリメントのデータ/時間特徴量に基づいてグループ化する行を識別する個別のCSVファイルで定義されます。 アップロードされ、インサイトが計算されると、DataRobotは期間ベースの結果の表と各期間の「時間経過に伴う」ヒストグラムを提供します。
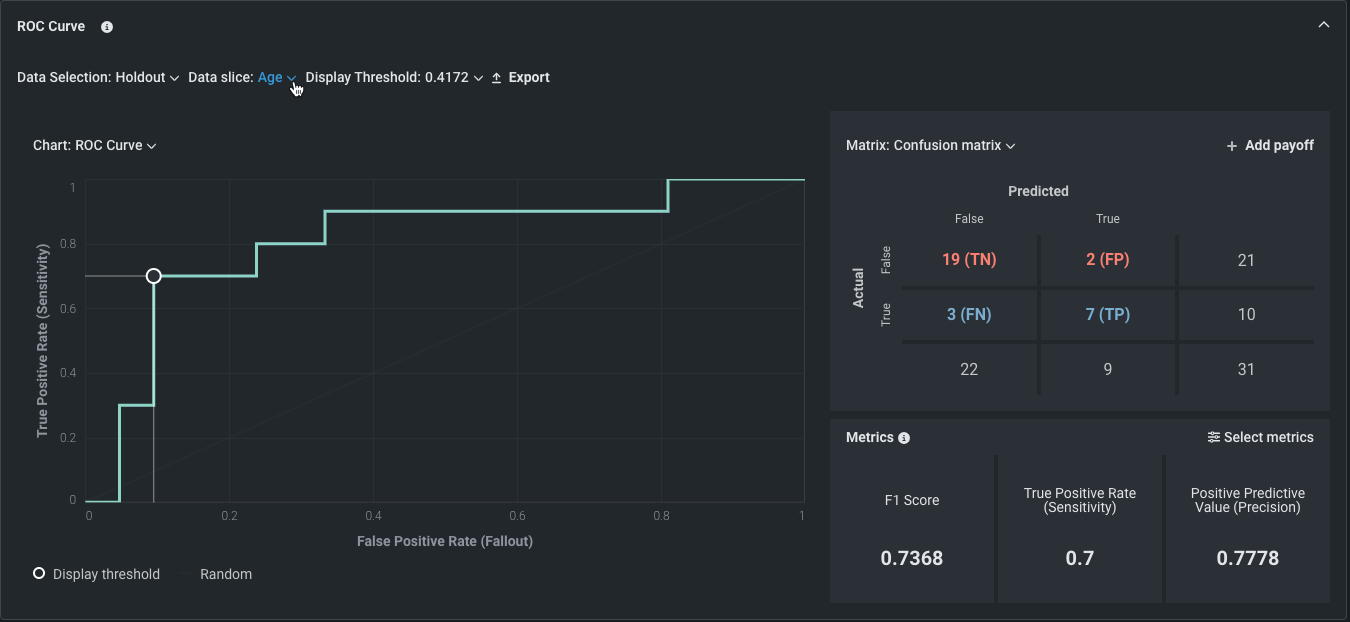
ROC曲線¶
分類エクスペリメントでは、ROC曲線タブには、確率スケール上の任意のポイントで、選択したモデルに関する分類、パフォーマンス、および統計を探索する以下のツールが用意されています。
系列のインサイト¶
複数系列エクスペリメントのための 系列のインサイトタブでは、チャート形式と表形式の両方で系列ごとの情報が得られます。
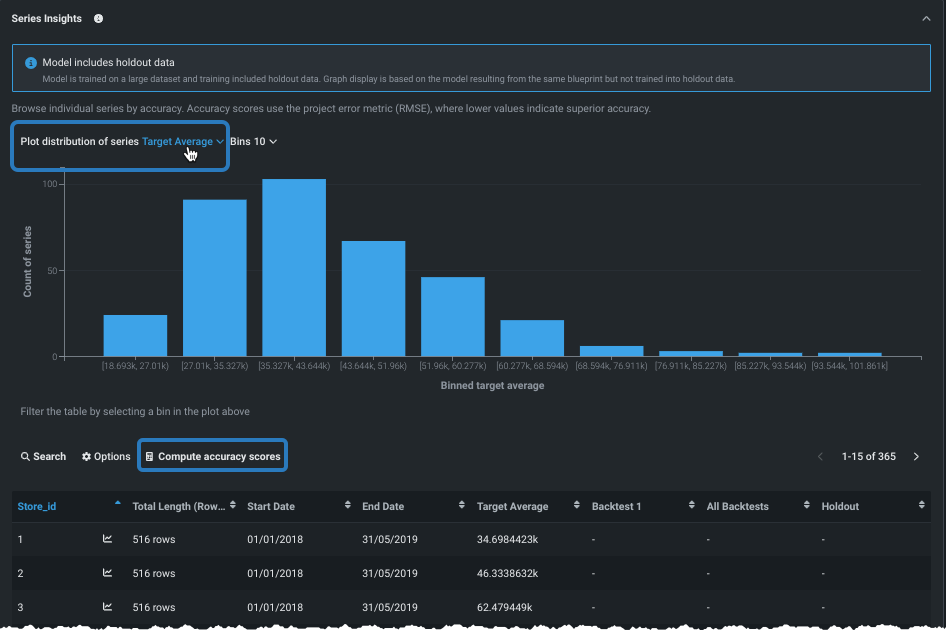
処理を高速化するため、系列のインサイトの視覚化は、最初は(IDでソートされた)先頭の1000系列について計算されます。 ただし、残りの系列データの精度スコアを計算できます。 表示を変更するには、分布プロットコントロールとビニングを使用します。
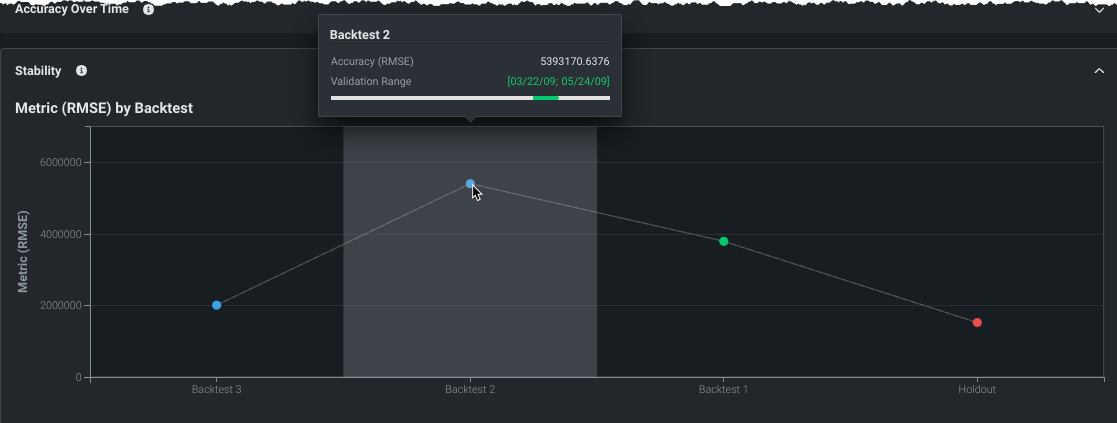
安定性¶
安定性タブは、さまざまなバックテストにおけるモデルのパフォーマンスを一目で把握できるサマリーを提供します。 これは、パフォーマンス測定に役立ちます。さらに、再トレーニングが必要になるまでに、そのモデルがどれくらいの期間、実稼働できるのか(「安定」期間はどれくらいか)を示すものです。 チャートの値は、各バックテストとホールドアウトの検定スコアを表します。
コンプライアンスドキュメント¶
DataRobotは、モデル開発に関連する多くの重要なコンプライアンスタスクを自動化することによって、規制の厳しい業界でデプロイまでの時間を短縮できます。 各モデルに対して個々のドキュメントを生成し、効果的なモデルリスク管理に関する包括的なガイダンスを提供できます。 レポートは、編集可能なMicrosoft Wordドキュメント(.docx)としてダウンロードできます。 生成されたレポートには、規制への準拠要求に応じた適切なレベルの情報および透明性が含まれます。
モデルコンプライアンスレポートの形式と内容は規定されていませんが、十分に堅牢なモデル開発、実装、および使用ドキュメントを作成するテンプレートとして機能します。 ドキュメントは、モデルのコンポーネントが意図したとおりに機能すること、それが意図したビジネス目的に対して適切であること、およびモデルが概念的に堅牢であることを示す証拠を提供します。 このため、レポートは、連邦準備制度理事会のシステムのSR11-7:モデルリスク管理に関するガイダンス完成に役立ちます。Guidance on Model Risk Management(モデルリスク管理に関するガイダンス)への準拠に役立ちます。
コンプライアンスレポートを生成するには:
- リーダーボードからモデルを選択します。
-
モデルアクションドロップダウンから、コンプライアンスレポートを生成を選択します。
-
ワークベンチはダウンロード先の場所を求めるメッセージを表示します。選択すると、エクスペリメントを続けている間に、バックグラウンドでレポートを生成します。
次のアクション¶
モデルを選択した後、エクスペリメント内から以下の操作を行うことができます。