Vector databases¶
A vector database (VDB) is a collection of unstructured text broken up into chunks with embeddings generated for each chunk. Both the chunks and embeddings are stored in a database and are available for retrieval. VDBs can optionally be used to ground the LLM responses to specific information and can be assigned to an LLM blueprint to leverage during a RAG operation.
The simplified workflow for working with VDBs is as follows:
- Add data to the Data registry.
- Add a VDB to a Use Case.
- Set the configuration.
- Set chunking.
- Create the VDB and add it to an LLM blueprint in the playground.
See the considerations related to vector databases for guidance when working with DataRobot GenAI capabilities.
Add data¶
GenAI supports two types of VDBs:
- Local, "in-house" built VDBs, identified as
DataRobotand stored in the Data Registry. - External, hosted in the model workshop for validation and registration, and identified as
Externalin the Use Case directory listing.
Dataset requirements¶
When uploading datasets for creating a vector database, the only supported format is .zip. DataRobot then processes the .zip to create a .csv containing text columns with an associated reference ID (file path) column. The reference ID column is created automatically when the .zip is uploaded. All files should be either in the root of the archive or in a single folder inside an archive. Using a folder tree hierarchy is not supported.
See the considerations for more information on supported file content.
Internal VDBs¶
Internal VDBs in DataRobot are optimized to maintain retrieval speed while ensuring an acceptable retrieval accuracy. To add data for an internal VDB:
-
Prepare the data by compressing the files that will make up your knowledge source into a single
.zipfile. You can either select files and zip or compress a folder holding all the files. -
Upload the
.ziparchive. You can do this either from:-
A Workbench Use Case from either a local file or data connection.
-
The AI Catalog from a local file, HDFS, URL, or JDBC data source. DataRobot converts the file to
.csvformat. Once registered, you can use the Profile tab to explore the data:
-
Once the data is available on DataRobot, you can add it as a vector database for use in the playground.
External VDBs¶
The External "bring-your-own" (BYO) VDB provides the ability to leverage your custom model deployments as vector databases for LLM blueprints, using your own models and data sources. Using an external VDB cannot be done via the UI; review the notebook that walks through creating an external vector database using DataRobot’s Python client.
Key features of external VDBs¶
-
Custom Model Integration: Incorporate your own custom models as vector databases, enabling greater flexibility and customization.
-
Input and output format compatibility: External BYO VDBs must adhere to specified input and output formats to ensure seamless integration with LLM blueprints.
-
Validation and registration: Custom model deployments must be validated to ensure they meet the necessary requirements before being registered as an external vector database.
-
Seamless integration with LLM blueprints: Once registered, external VDBs can be used with LLM blueprints in the same way as local vector databases.
-
Error Handling and updates: The feature provides error handling and update capabilities, allowing you to revalidate or create duplicates of LLM blueprints to address any issues or changes in custom model deployments.
Basic external workflow¶
The basic workflow, which is covered in depth in this notebook, is as follows:
- Create the vector database via the API.
- Create a custom model deployment to bring the VDB into DataRobot.
- Once the deployment is registered, link to it as part of vector database creation in your notebook.
Add a VDB¶
There are four methods for adding VDBs from within the Use Case.
Note
Although a dataset may appear greyed out in the Use Case listing, it is still available for use as the basis of a vector database. However, the database cannot be selected for preview.
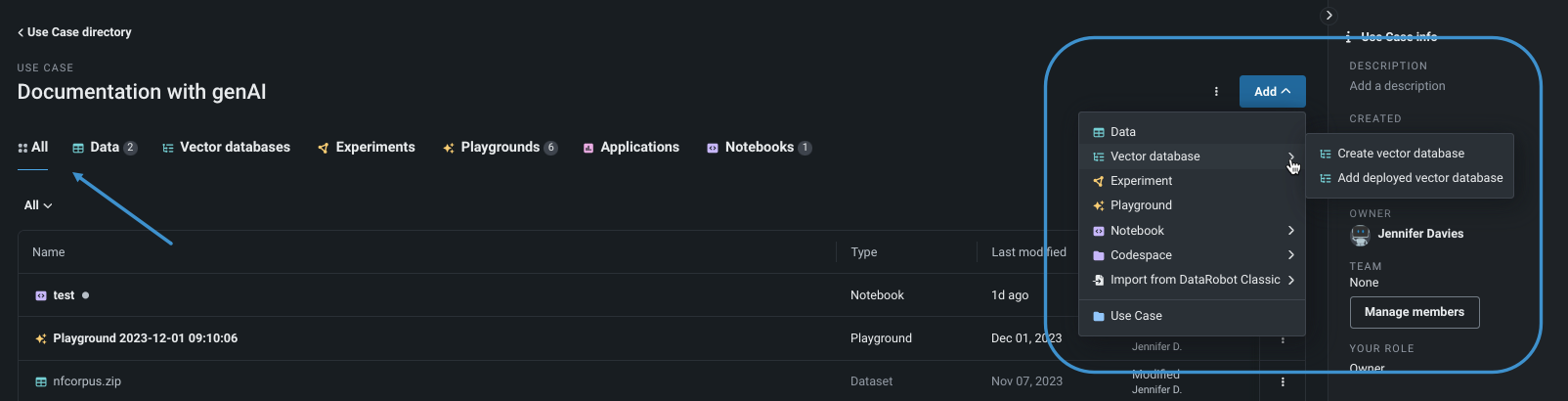
-
From Use Case home All tab, click the Add dropdown:
- Choose Create vector database to create a VDB from data in the AI Catalog.
- Choose Add deployed vector database to add a deployment that contains a vector database that will be used during LLM prompting.
-
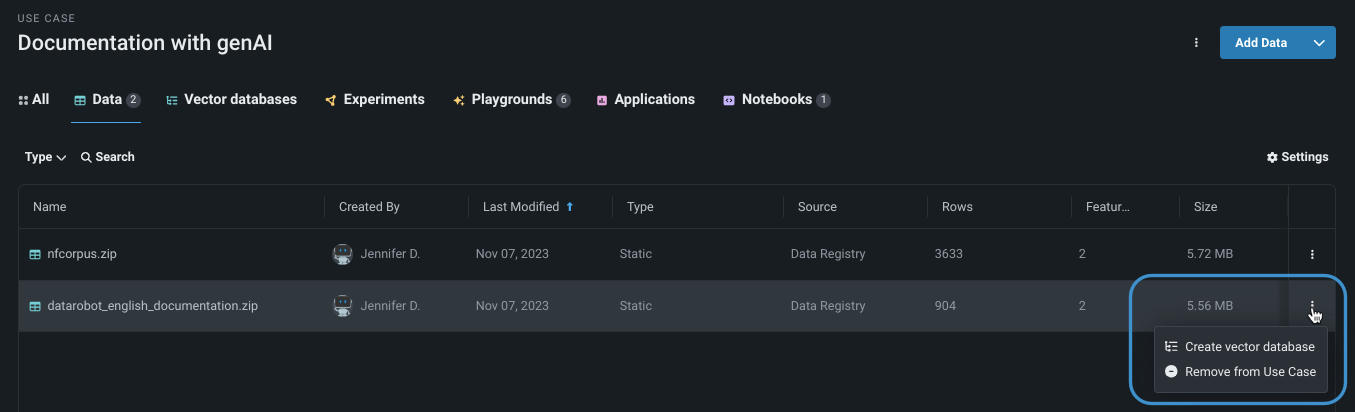
From the Data tab, use the Add dropdown or click the Actions menu and select Create vector database. This method loads the database in the Configuration > Data Source field.
-
From the Vector databases tab, click Create vector database.
-
From the LLM blueprint Configuration > Vector database tab, use the dropdown:
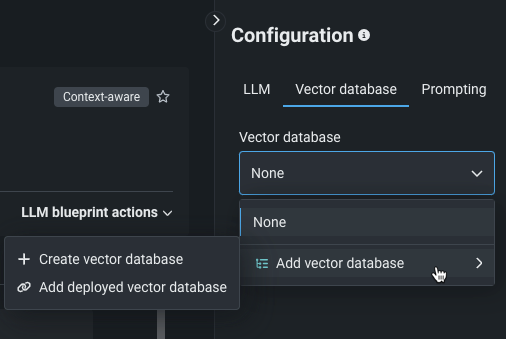
VDB settings¶
When creating a VDB, you set a basic configuration and text chunking.
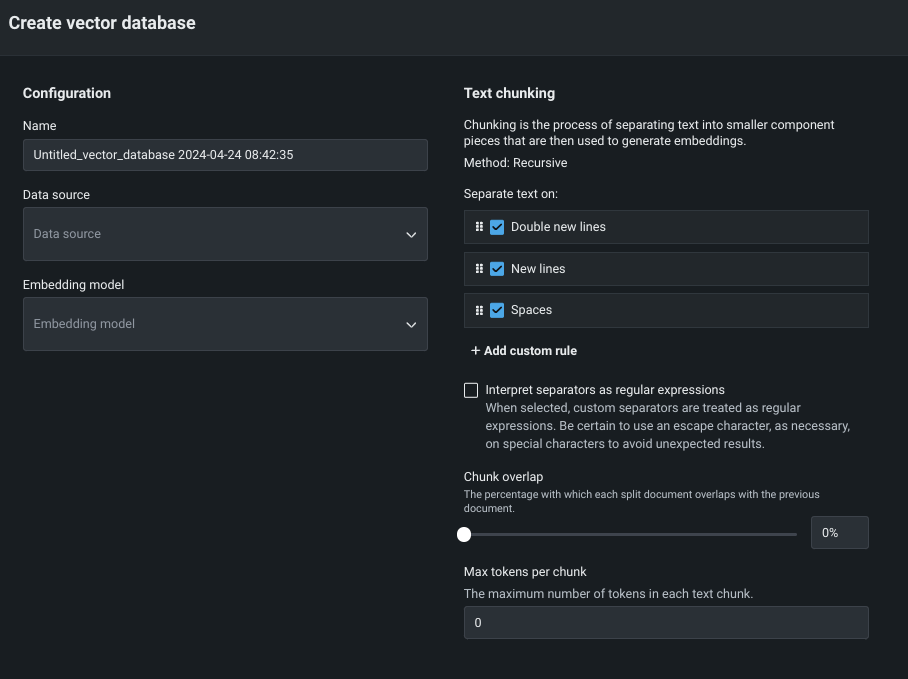
VDB configuration¶
The following table describes each setting in the Configuration section of VDB creation:
| Field | Description |
|---|---|
| Name | The name the VDB is saved with. This name displays in the Use Case Vector databases tab and is selectable when configuring playgrounds. |
| Data source | The dataset used as the knowledge source for the VDB. The list populates based on the entries in the Use Case Vector databases tab. If you started the VDB creation from the action menu on the Data tab, the field is prepopulated with that dataset. |
| Embedding model | The model that defines the type of embedding used for encoding data, described below. |
Embeddings¶
Embeddings in GenAI are based on the SentenceBERT framework, providing an easy way to compute dense vector representations for sentences and paragraphs. The models are based on transformer networks (BERT, RoBERTA, T5) and achieve state-of-the-art performance in various tasks. Text is embedded in vector space such that similar text are closer and can efficiently be found using cosine similarity.
GenAI supports five types of embeddings for encoding data:
-
_jinaai/jina-embedding-t-en-v1_: A tiny language model that has been trained using Jina AI's Linnaeus-Clean dataset. It is pre-trained on the English corpus and is the fastest embedding model offered by GenAI in DataRobot. Recommended when the dataset is detected English. -
_sentence-transformers/all-MiniLM-L6-v2_: A small language model fine-tuned on a 1B sentence-pairs dataset. It is relatively fast and pre-trained on the English corpus. -
_intfloat/e5-base-v2_: A medium-sized language model from Microsoft Research ("Weakly-Supervised Contrastive Pre-training on large English Corpus"). -
_intfloat/e5-large-v2_: A large language model from Microsoft Research ("Weakly-Supervised Contrastive Pre-training on large English Corpus"). -
cl-nagoya/sup-simcse-ja-base:: A medium-sized language model from the Nagoya University Graduate School of Informatics ("Japanese SimCSE Technical Report"). Recommended when the dataset language is detected as Japanese. -
_huggingface.co/intfloat/multilingual-e5-base_: A medium-sized language model from Microsoft Research ("Weakly-Supervised Contrastive Pre-training on large MultiLingual corpus"). The model supports 100 languages. Recommended when the dataset is detected as a language that is not English.Multilingual language support
Supported languages:
"Afrikaans", "Amharic", "Arabic", "Assamese", "Azerbaijani", "Belarusian", "Bulgarian", "Bengali", "Breton", "Bosnian", "Catalan", "Czech", "Welsh", "Danish", "German", "Greek", "English", "Esperanto", "Spanish", "Estonian", "Basque", "Persian", "Finnish", "French", "Western Frisian", "Irish", "Scottish Gaelic", "Galician", "Gujarati", "Hausa", "Hebrew", "Hindi", "Croatian", "Hungarian", "Armenian", "Indonesian", "Icelandic", "Italian", "Japanese", "Javanese", "Georgian", "Kazakh", "Khmer", "Kannada", "Korean", "Kurdish", "Kyrgyz", "Latin", "Lao", "Lithuanian", "Latvian", "Malagasy", "Macedonian", "Malayalam", "Mongolian", "Marathi", "Malay", "Burmese", "Nepali", "Dutch", "Norwegian", "Oromo", "Oriya", "Panjabi", "Polish", "Pashto", "Portuguese", "Romanian", "Russian", "Sanskrit", "Sindhi", "Sinhala", "Slovak", "Slovenian", "Somali", "Albanian", "Serbian", "Sundanese", "Swedish", "Swahili", "Tamil", "Telugu", "Thai", "Tagalog", "Turkish", "Uyghur", "Ukrainian", "Urdu", "Uzbek", "Vietnamese", "Xhosa", "Yiddish", "Chinese"
Chunking settings¶
Text chunking is the process of splitting text documents into smaller text chunks that are then used to generate embeddings. There are two components of setting up chunking—separators and chunking settings.
Work with separators¶
Separators are "rules" or search patterns (not regular expressions although they can be supported) for breaking up text by applying each separator, in order, to divide text into smaller components—they define the tokens by which the documents are split into chunks. Chunks will be large enough to group by topic, with size constraints determined by the model’s configuration. Recursive text chunking is the method applied to the chunking rules.
What is recursive chunking?
Recursive text chunking works by recursively splitting text documents according to an ordered list of text separators until a text chunk has a length that is less than the specified max chunk size. If generated chunks have a length/size that is already less than the max chunk size, the subsequent separators are ignored. Otherwise, DataRobot applies, sequentially, the list of separators until chunks has a length/size that is less than the max chunk size is achieved. In the end, if a generated chunk is larger than the specified length, it is discarded. In that case, DataRobot will use a "separate each character" strategy to split on each character and then merge consecutive split character chunks up to the point of the the max chunk size limit. If no "split on character" is listed as a separator, long chunks are cut off. That is, some parts of the text will be missing for the generation of embeddings but the entire chunk will still be available for documents retrieval.
Each VDB starts with four default rules, which define what to split text on:
- Double new lines
- New lines
- Spaces
While these rules use a word to identify them for easy understanding, on the backend they are interpreted as individual strings (i.e., \n\n, \n, " ", "").
There may be cases where none of the separators are present in the document, or there is not enough content to split into the desired chunk size. If this happens, DataRobot applies a "next-best character" fallback rule, moving characters into the next chunk until the chunk fits the defined chunk size. Otherwise, the embedding model would just truncate the chunk if it exceeds the inherent context size.
Add custom rule¶
You can add up to five custom separators to apply as part of your chunking strategy. This provides a total of nine separators (when considered together with the four defaults). The following applies to custom separators:
- Each separator can have a maximum of 20 characters.
-
There is no "translation logic" that allows use of words as a separator. For example, if you want to chunk on punctuation, you would need to add a separator for each type.
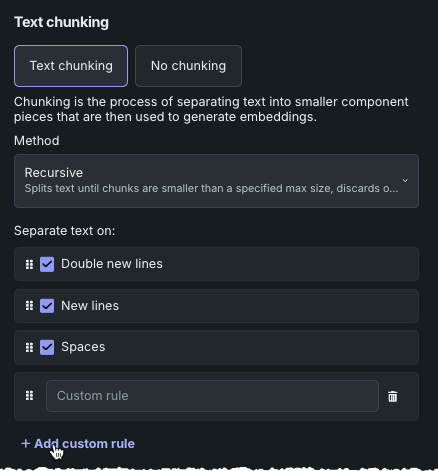
-
The order of separators matters. To reorder separators, simply click the cell and drag it to the desired location.
-
To delete separators, whether in fine tuning your chunking strategy or to free space for additional separators, click the trashcan icon. You cannot delete the default separators.
Use regular expressions¶
Select Interpret separators as regular expressions to allow regular expressions in separators. It is important to understand that with this feature activated, all separators are treated as regex. This means, for example, that adding "." matches and splits on every character. If you instead want to split on "dots," you must escape the expression (i.e., "."). This rule applies to all separators, both custom and predefined (which are configured to act this way).
Chunking parameters¶
Chunking parameters further define the output of the VDB. The default values for chunking parameters are dependent on the embedding model.
Chunk overlap¶
Overlapping refers to the practice of allowing adjacent chunks to share some amount of data. The Chunk overlap parameter specifies the percentage of overlapping tokens between consecutive chunks. Overlap is useful for maintaining context continuity between chunks when processing the text with language models, at the cost of producing more chunks and increasing the size of the vector database.
Max tokens per chunk¶
Max tokens per chunk (chunk size) specifies:
- The maximum size (in tokens) of each text chunk extracted from the dataset when building the vector database.
- The length of the text that is used to create embeddings.
- The size of the citations used in RAG operations.
Save the VDB¶
Once the configuration is complete, click Create vector database to make the database available in the playground.
Note that you can view all VDBs associated with a Use Case from the Vector database tab within the Use Case. For external VDBs you can see only the source type; because it is not managed by DataRobot, other data is not available for reporting.