title: 大規模なバッチスコアリング description: DataRobotのバッチ予測APIを使用して、ソースとターゲットのデータソースを組み合わせます。
hide_from_nav: true¶
DataRobotとSnowflake:大規模なバッチスコアリングとオブジェクトストレージ¶
DataRobotのバッチ予測APIを使用すると、ソースとターゲットのデータソースをスコアリングされたデータの送信先(JDBCデータベースおよび、AWS S3、Azure Blob、Google GCSなどのクラウドオブジェクトストレージオプション)と組み合わせて、さまざまなローカルファイル全体で一致させるジョブを構築できます。 UIを介してバッチ予測APIを利用する例と、元のHTTPエンドポイントリクエストを使用してバッチスコアリングジョブを作成する例については、以下を参照してください。
- Snowflakeを使用したサーバー側のスコアリング
- バッチ予測APIドキュメント
- Python APIクライアントの関数
スコアリングパイプラインのクリティカルパスは、通常、デプロイされた機械学習モデルを実際に実行するために使用できるリソースの量です。 データベースからデータをすばやく抽出できますが、スコアリングのスループットは、使用可能なスコアリングコンピューティングに制限されます。 COPY INTOSnowflakeステージを使用する場合など、ネイティブのオブジェクトストレージの一括読み込み操作で行うと、細分化された列指向のクラウドデータベース(Snowflake、Synapseなど)への挿入も最も効率的です。 特にSnowflakeの追加の利点は、ウェアハウスの請求を、ジョブ中のJDBC挿入の継続的なセットに対して、一括読み込みの実行に限定できることです。 これにより、ウェアハウスの実行時間が短縮され、ウェアハウスのコンピューティングコストが削減されます。 SnowflakeおよびSynapseアダプターは、オブジェクトストレージへの一括抽出操作と読み込み操作、およびオブジェクトストレージのスコアリングパイプラインを活用できます。
Snowflakeアダプターの統合¶
以下の例では、サーバー側のスコアリングの例で示した、資格情報管理のバッチ予測APIヘルパーコードの一部を利用しています。
このセクションでは、Python APIクライアント(簡単にするために推奨される場合があります)を使用するのではなく、最小限の依存関係で元のAPIを使用する方法を説明します。 スコアリングデータセットが大きくなるにつれて、ここで説明するオブジェクトストレージアプローチは、エンドツーエンドのスコアリング時間とデータベース書き込み時間の両方を削減することが期待できます。
Snowflakeアダプタータイプはオブジェクトストレージを仲介として活用するため、バッチジョブには2つの資格情報(1つはSnowflake用、もう1つはS3などのストレージレイヤー用)セットが必要です。また、ジョブと同様に、アダプターを組み合わせて使用できます。
Snowflake JDBCからDataRobot、S3ステージ、Snowflake¶
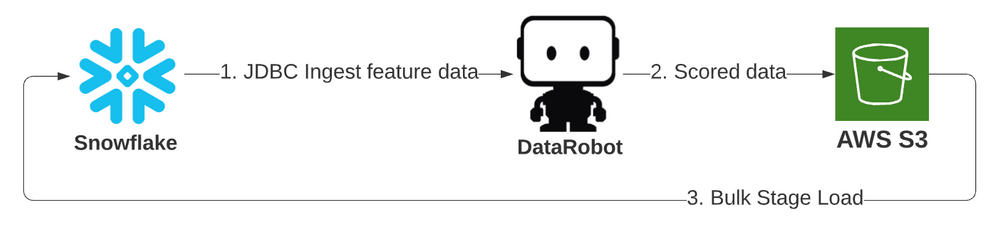
この最初の例では、以前の既存のJDBCアダプターの取込みタイプと、一括読み込みでSnowflakeステージオブジェクトを使用するSnowflakeアダプターの出力タイプを活用しています。 ジョブの詳細のみを以下に指定します。GitHubで完全なコードを参照してください。 ジョブはすべての値を明示的に提供しますが、多くの値には指定なしで使用できるデフォルト値があります。 この生存モデルでは、入力テーブルを指定してタイタニック号の乗客をスコアリングします。
job_details = {
"deploymentId": DEPLOYMENT_ID,
"numConcurrent": 16,
"passthroughColumns": ["PASSENGERID"],
"includeProbabilities": True,
"predictionInstance" : {
"hostName": DR_PREDICTION_HOST,
"datarobotKey": DATAROBOT_KEY
},
"intakeSettings": {
"type": "jdbc",
"dataStoreId": data_connection_id,
"credentialId": snow_credentials_id,
"table": "PASSENGERS_6M",
"schema": "PUBLIC",
},
'outputSettings': {
"type": "snowflake",
"externalStage": "S3_SUPPORT",
"dataStoreId": data_connection_id,
"credentialId": snow_credentials_id,
"table": "PASSENGERS_SCORED_BATCH_API",
"schema": "PUBLIC",
"cloudStorageType": "s3",
"cloudStorageCredentialId": s3_credentials_id,
"statementType": "insert"
}
}
SnowflakeからS3ステージ、DataRobot、S3ステージ、Snowflake¶
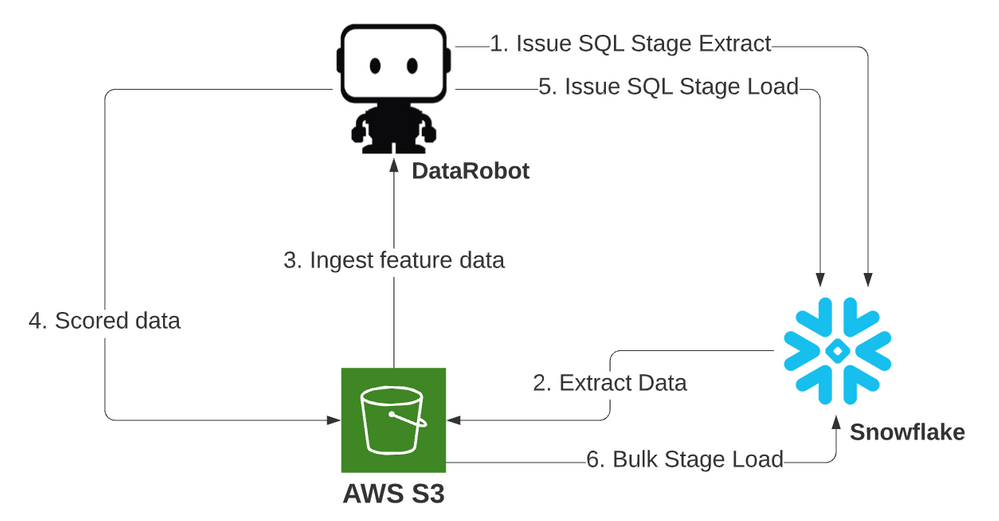
この2番目の例では、取込み操作と出力操作の両方にSnowflakeアダプターを使用します。データはオブジェクトステージにダンプされ、S3パイプラインを介してスコアリングされ、ステージから一括で読み込まれます。 これは、パフォーマンスとコストの推奨フローです。
- ステージパイプライン(S3からS3へ)は、専用予測エンジン(DPE)スコアリングリソースに対するスコアリングリクエストの一定のフローを維持し、コンピューティングを過負荷状態にします。
- スコアリングコンポーネントにどれだけ時間がかかっても、Snowflakeコンピューティングリソースは、最初の抽出期間中のみ実行する必要があり、すべてのデータがスコアリングされたら、スコアリングされたデータの最終的な一括読み込みが1回行われます。 これにより、読み込み効率が最大化され、すべてのSnowflakeコンピューティングリソースの実行コストにも有益です。
この例のジョブは最初の例と似ています。 オプションを説明するために、ソーステーブル名ではなく、SQLクエリを入力として使用します。
job_details = {
"deploymentId": DEPLOYMENT_ID,
"numConcurrent": 16,
"chunkSize": "dynamic",
"passthroughColumns": ["PASSENGERID"],
"includeProbabilities": True,
"predictionInstance" : {
"hostName": DR_PREDICTION_HOST,
"datarobotKey": DATAROBOT_KEY
},
"intakeSettings": {
"type": "snowflake",
"externalStage": "S3_SUPPORT",
"dataStoreId": data_connection_id,
"credentialId": snow_credentials_id,
"query": "select * from PASSENGERS_6m",
"cloudStorageType": "s3",
"cloudStorageCredentialId": s3_credentials_id
},
'outputSettings': {
"type": "snowflake",
"externalStage": "S3_SUPPORT",
"dataStoreId": data_connection_id,
"credentialId": snow_credentials_id,
"table": "PASSENGERS_SCORED_BATCH_API",
"schema": "PUBLIC",
"cloudStorageType": "s3",
"cloudStorageCredentialId": s3_credentials_id,
"statementType": "insert"
}
}
SnowflakeまたはAzure Synapseで大規模なスコアリングジョブを実行する場合は、関連するアダプターを利用することをお勧めします。 取込みと出力の両方にこれらのアダプターのいずれかを使用すると、データボリュームサイズの増加に合わせてスコアリングパイプラインがスケーリングされます。